| СТАТЬЯ | 22.08.01 |
Исследование возможностей CASE-технологии при создании интеллектуальных систем управления
(c) 2000 Семизельникова О.А.
Эта статья была размещена на сайте www.inftech.webservis.ru/
2.3. CASE – средство qWord
2.3.1. Некоторые сведения об идеологии и структуре qW
qWORD, как CASE-средство, построенное в системе Cache, поддерживает процессы создания и сопровождения информационной системы, включая анализ и формулировку требований, проектирования прикладных приложений и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы. CASE-средство qWORD вместе с системным ПО и техническими средствами образует полную среду разработки информационных систем.
При создании структуры информационной среды посредством qWORD используются объектно-ориентированные методы проектирования. Причём проектируемая структура не привязана к конкретной парадигме (иерархической, реляционной или какой-либо другой).
В системе выработана структура базовых понятий, которые представлены базовыми классами. Полностью поддерживаются механизмы наследования и инкапсуляции. Это позволяет провести более глубокий анализ предметной области, ускорить процесс проектирования, упростить сопровождение и корректировку баз данных и, как следствие, снизить количество человеческих ошибок. qWORD даёт возможность осуществлять весь комплекс работ со структурой информационной среды, опираясь на объектно-ориентированные методы проектирования.
Вся информация о структурах проектируемой информационной среды находится в специализированных массивах данных (фрейме и словаре). Этими мета-данными оперируют все подсистемы комплекса, на их основе формируются методы ввода информации, её обработки, анализа и вывода. Благодаря такому подходу обеспечивается целостность и устойчивость генерируемых структур информационной среды, возможность дальнейшей работы по корректировке и усовершенствованию, как её логики, так и физического представления в виде таблиц баз данных.
Помимо явных действий, очевидных любому проектировщику баз данных, в qWORD заложен ряд системных функций, призванных облегчить и упростить ему работу.
Прежде всего, qW является программным инструментом для создания инструментов. Его возможности никак не могут быть сведены, скажем, к системе управления реляционной базы данных.
Главным общим принципом, лежащим в основе идеологии qW, является принцип саморазвивающегося программного продукта. Саморазвитие qW происходит в процессе его эксплуатации. Структуры, которые создает Разработчик конкретного приложения, в дальнейшем являются достоянием qW, выходят за рамки конкретного приложения и развивают qW как инструмент.
Принцип саморазвивающегося программного продукта находится в противоречии с принципом традиционно проектируемого программного продукта. qW не является спроектированным программным инструментом с изначально четко продуманной, но не способной к качественному развитию структурой. qW является открытой системой, написанной самой на себе. Пользователю qW (разработчику конкретных приложений) легко доступны для модификации структурные части системы и на всех уровнях.
2.3.2. Фрейм как совокупность данных
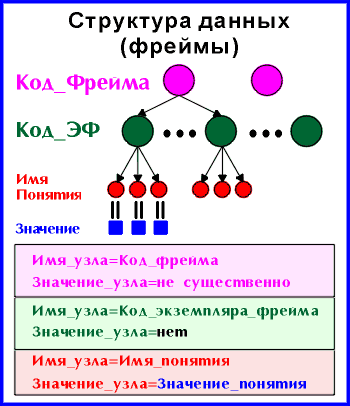
Инструментальная система баз знаний qWORD (СБЗ qW) состоит из множества фреймов. Фрейм - это совокупность связанных между собой данных (хранящейся в компьютере информации) и процедур (инструкций компьютеру для обработки этой информации). Опишем структуру фрейма и связанную с ней терминологию сначала рассматривая фрейм как совокупность входящих в него данных, а затем как совокупность входящих в него процедур.
Как совокупность данных фрейм состоит, с одной стороны, из множества экземпляров фрейма и, с другой стороны, из множества используемых во фрейме понятий. Внутренняя семантическая структура фрейма определяется через структуру связей входящих в него понятий. Никаких ограничений на сложность структуры не накладывается. Структура может быть простой таблицей, сложной иерархией или сетью понятий.
По своим структурно-семантическим возможностям qW принципиально качественно мощнее реляционной или иерархической модели обработки данных и не может быть к ним сведен. Однако, в первом приближении, мы можем использовать терминологию реляционных баз данных. Согласно этой терминологии фрейм это отношение или реляционная таблица, экземпляр фрейма - запись или строка таблицы, понятие - атрибут или столбец таблицы.
Любой фрейм имеет имя (название), код фрейма(номер) и набор экземпляров фрейма, каждый из которых однозначно идентифицируется кодом экземпляра фрейма. Одним из основных подобъектов фрейма являются понятия. Понятия нужны для хранения данных (или для их вычисления). Значением понятия может быть строка символов, или дерево. Понятия могут быть разных типов:
· простые (произвольная строка символов),
· типа текст (набор строк символов),
· структурированные (произвольное дерево) .
По способу получения значений понятий они подразделяются на два больших класса - терминальные и обобщенные. Терминальные понятия хранятся в БД, значение такого понятия может быть упорядоченным множеством слов, разделенных пробелами или состоять из одного слова. В операциях поиска слово выступает наименьшей смысловой единицей информации. Например, терминал название организации может иметь значение СП АРМ, состоящее из двух слов. Обобщенные понятия вычисляются из значений терминальных понятий в тот момент, когда они требуются, т.е. вместо их значений в БД хранится правило вывода значения понятия.
Фреймы, экземпляры фреймов, понятия и слова кодируются уникальным кодом. Коды фреймов и понятий открыты для Пользователя и в большинстве случаев он непосредственно присваивает фреймам и понятиям те коды, которые считает нужным присвоить. Коды экземпляров фреймов и слов скрыты от Пользователя и обычно порождаются автоматически. Все программные операции в qW совершаются через использование кодов, а не имен.
Код фрейма должен быть числом в интервале от 1 до 999. Код терминального понятия должен представлять из себя строку с первым буквенным символом. Первая буква строки кода определяет тип терминального понятия. Код обобщения должен быть с первым символом @.
С терминалами может быть связано правило проверки. Правило проверки - логическое выражение, определяющее допустимость записи значения терминального понятия в БЗ. С понятиями, терминалами и обобщениями, связывается правило вывода.
Например, обобщению ФИО может быть присвоен код @fio и оно может быть образовано из терминалов фамилия, имя, отчество с кодами ff, ii, оо путем задания простейшего правила вывода: $$G(“ff”)_”,”_$$G(“ii”)_”,”_$$G (“оо”). Это правило определяет ФИО для каждого экземпляра фрейма как строку, состоящую из значений соответствующих терминалов, разделенных запятой. В правиле вывода могут употребляться как встроенные в qW функции (в данном случае $$G - взять значение терминала), так и любые процедуры пользователя, оформленные как внешние функции М-языка.
Обобщение не обязательно должно быть образовано из терминалов. Например, обобщение время в правиле вывода может содержать вызов функции получения времени суток от системных часов.
При употреблении обобщения в качестве объекта поиска или в качестве содержимого полей бланков или таблиц, система автоматически будет порождать значение в соответствии с указанным правилом вывода.
Как уже говорилось, СБЗ - это множество фреймов, состоящих из множества экземпляров фреймов (множество записей). Уникальность конкретного экземпляра фрейма в пределах одного фрейма обеспечивается заданием списка ключевых терминальных понятий. Список определяет набор значений терминалов, однозначно идентифицирующих данный экземпляр фрейма. Например, если список состоит из терминалов фамилия, имя, отчество, то система позволит ввести в базу только одного Иванова Ивана Ивановича. Список ключевых терминалов может изменяться пользователем в процессе функционирования системы.
База знаний может состоять из нескольких фреймов, связанных через одинаковые значения общих терминалов. Общими считаются терминалы, имеющие один и тот же код в различных фреймах. Через общие понятия возможна операция отображения - переход от экземпляра одного фрейма к экземпляру (или множеству экземпляров) другого фрейма.
Структура БЗ может изменяться по желанию пользователя в процессе функционирования системы.
Для хранения данных используется дерево, чрезвычайно удобное для реализации объектного подхода. Говоря объект - имеем в виду дерево, и наоборот. Для хранения значений атрибутов объектов в qWORD5 может использоваться дерево.
Таким образом, в простейшем случае имеется двухуровневая структура данных (хранимых в БД):
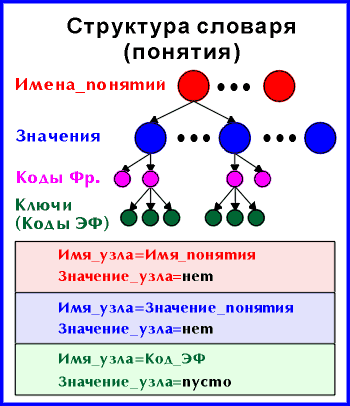
Таким образом, вся БД состоит из экземпляров фреймов, каждый из которых имеет свой уникальный ключ (код ЭФ) и характеризуется набором конкретных значений понятий (реквизитов записи). Для доступа к данным используются дополнительные структуры - словари значений понятий. Некоторые понятия (атрибуты) не обязательно попадают в словарь.
Основные принципы:
Первая структура данных (фреймы-понятия) (рис.2.2), вообще говоря, абсолютно не упорядочена, поскольку ключ, кроме уникальной идентификации записи (ЭФ) не несет никакой нагрузки. Вторая структура (словарь данных) предназначена, прежде всего, для убыстрения поисков, поскольку по конкретному значению конкретного понятия сразу доступен список релевантных ключей - кодов ЭФ, в которые входит именно это значение. Это обстоятельство очень важно для М-реализаций, внутренняя БД которых представляет собой упорядоченное иерархическое дерево, узлы которого упорядочиваются автоматически на системном уровне, так как зная значение имени текущего узла, всегда можно определить имя следующего/предыдущего. Это позволяет автоматически получать списки релевантных ключей ЭФ, упорядоченных по одному значению.
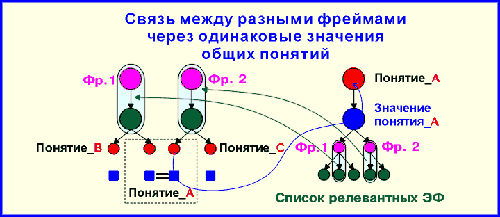
Рис.2.2. Основные структуры данных qWord
Структурированный код ЭФ
Некоторым недостатком такого подхода является использование ключа (кода ЭФ) только для обеспечения уникальности идентификации ЭФ (записей). На самом деле, если придать ключу дополнительную структуру, сделав его значимым, можно получить гораздо больше возможностей. Например, сделав код ЭФ зависимым от какого-то понятия таким образом, что упорядоченности значений понятий соответствует упорядоченность кодов ЭФ, мы получим возможность иерархического упорядочивания списка релевантных одновременно по двум понятиям, не вводя дополнительных структурированных понятий. Это одна из возможностей. Вторая возможность существенно богаче, и основывается на идее структурированного ключа, когда он разбивается на отдельные значимые фрагменты. Это позволяет отразить реальную иерархичность, присущую большинству информационных структур. Общая идея достаточно тривиальна. Упорядоченной иерархии однозначно соответствует дерево, которое можно представить как массив с произвольными индексами:
Дерево=Корень (Имя узла1, Имя Узла2, … ,Имя Узлаn),
где значимыми являются как имена узлов, так и их значения (отметим, что некоторые узлы могут не иметь значений). Тогда уникальный ключ, характеризующий запись (т.е. некоторую совокупность подузлов данного узла) может быть сконструирован из имени их общего отца, равно как ключ, однозначно характеризующий конкретное понятие в данной конкретной записи - из полного имени этого узла. Каким образом - в каждой конкретной ситуации может быть решено тем или иным способом, наиболее удобным для практической реализации. В принципе, даже информация о уровне (т.е. глубине дерева) может быть весьма значимой. Максимально возможный вариант порождения ключа - если узлы дерева каким-то образом упорядочены, то точно таким же образом упорядочен и порожденный структурированный ключ.
Посмотрим, что это может дать. Во-первых, значения самих понятий легко могут быть сделаны структурированными в виде некоторой иерархии. Во-вторых, в качестве имени узла может выступать уже не имя соответствующего понятия, а его значение (или какая-либо функция от него).
Например, на рис.2.3 представлен простейший вариант отображения иерархической структуры в линейную совокупность ключей. Заметим, что в данном варианте, кроме однозначности отображения, сохраняется и упорядоченность, что, в принципе, не обязательно. Информация о глубине уровня иерархии заложена в количестве разделителей, содержащихся в ключе, информация о имени узла на этом уровне - в содержании соответствующего поля ключа. Уже этого оказывается вполне достаточно, чтобы строить эффективные структуры данных. Рассмотрим, например, простейшую ситуацию, встречающуюся в реальной жизни, когда в структуре документов, подлежащих хранению в БД, с одной стороны, имеется явная иерархия понятий, но с другой стороны, поиски должны идти по разным уровням этой иерархии. Например, документ как таковой имеет шапку со своим набором реквизитов, строки - с другим набором реквизитов, и каждая строка может иметь подстроки с третьим набором реквизитов.
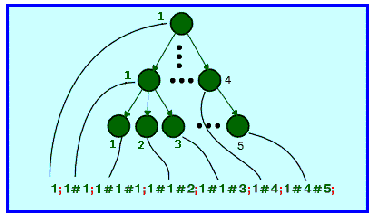
Рис.2.3. Отображение иерархической структуры в линейную
Для конкретности, пусть с шапкой документа связаны понятия (реквизиты):
Уровень 1: Дата_документа, Грузоотправитель, Грузополучатель, Номер документа, документострока.
Документ состоит из документострок, со следующими реквизитами:
Уровень 2: Номер строки, Товарная группа, Стоимость, подстрока.
Подстрока имеет следующие реквизиты:
Уровень 3: Наименование товара, Цена, Количество.
Определяем правило порождения кода экземпляра фрейма, исходя из имеющейся в документе иерархии уровней: Код_ЭФ=Код1#Код2#Код3 , где Код i - некоторый ключ, однозначно идентифицирующий данный уровень (например, просто следующий номер по порядку, или нечто более сложное). В принципе, возможны два варианта структуры ключа, однозначно указывающих на требуемый уровень - "статический", когда в качестве кодов подуровней полного ключа указываются какие-то определенные значения, никогда не используемые для кода реально существующего уровня, и "динамический", когда подуровни вообще никак не отражаются в ключе. В первом случае, код ЭФ для второго уровня может выглядеть как
Код_ЭФ=Код1#Код2#zero, во втором случае как Код_ЭФ=Код1#Код2. В первом случае любой ключ сразу несет в себе информацию о глубине иерархии, во втором случае - нет. Получающаяся структура приведена на рис.2.4.
Формальное отличие этой структуры от полного дерева заключается в том, что если у узла есть значение (красные узлы), то у него нет потомков, и значения именно этих узлов могут попасть в словарь. Естественно, имеется возможность хранить и данные типа дерево (фиолетовые узлы). Правда, пока способ ведения словаря для значений такого типа находится в стадии экспериментов. Если же у узла есть потомки (зеленые узлы), то:
С формальной точки зрения можно считать, что выделяется понятие некоторого особенного типа, назовем его "код узла", значение которого используется в качестве имени узла.
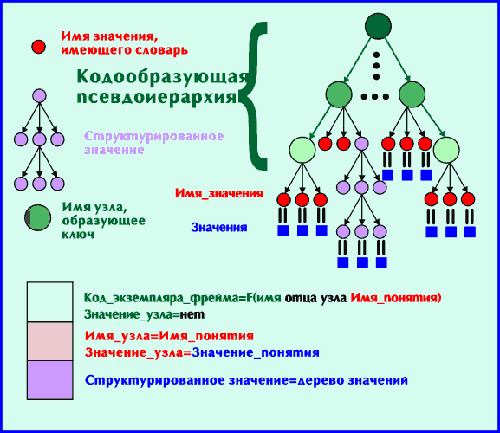
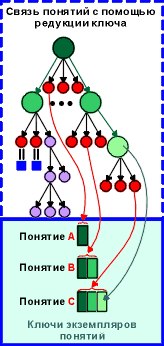
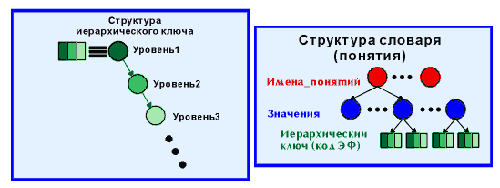
Рис.2.4. Структура иерархического ключа
Чем привлекательна идея структурированного ключа в сочетании с реляционными словарями?
Во-первых, она позволяет резко сократить объем словаря, так как мощность множества ключей понятий, находящиеся на верхнем уровне иерархии существенно меньше.
Во-вторых, используя метод редукции ключа, мы легко получаем доступ к любому предку. Например, если понятие Номер_Договора описано на первом уровне иерархии, а понятиеКод_Товара - на третьем, усекая (редуцируя) ключ экземпляра понятия Код_Товара,< мы сразу получаем ссылку на значение понятия Номер_Договора, по которому этот товар поставлялся.
В третьих, наличие такой иерархии позволяет заранее структурировать данные, упорядочивая их в той или иной последовательности (путем выбора функции порождения кодообразующего понятия на соответствующем уровне иерархии), так что совокупность ссылок на экземпляры соответствующих фреймов оказывается внутренне упорядоченной и "расслоенной" на релевантные экземпляры.
В четвертых, иерархия позволяет удобным и естественным образом реализовать наследование свойств, и их индивидуализацию для тех или иных объектов, что в свою очередь позволяет разработать универсальные методы доступа к данным и свойствам.
В пятых, естественным образом реализуются связи "многие-ко-многим" через общие имена и значения понятий в разных поддеревьях.
В шестых, совершенно автоматически получается возможность дальнейшей детализации свойств информационного объекта. Поясним последнее на примере. Пусть, например, из какой-то другой базы данных поступает некоторый документ со множеством своих атрибутов, из которых для начала требуются лишь немногие - например, дата договора и его наименование. Тогда мы можем поместить его в базу данных следующим образом - заводим три понятия "Дата", "Наименование", "Текст_Договора", причем первые два попадают в словарь, а третье - структурированное значение. Таким образом, на данный конкретный документ у нас появляются ссылки через словари значений понятия "Дата" и "Наименование", через которые мы можем получить и доступ к тексту договора в целом. В дальнейшем, когда нам потребуется извлечь из этого документа другие атрибуты, мы сможем сделать это просто создавая новые понятия для этого объекта, придавая им требуемые значения. Более того, мы можем полностью переструктурировать имеющуюся информацию на основе имеющейся, создав другую иерархию понятий, связанную с имеющимся именем общего "отца"-первоначально созданного ключа, никак не мешая эксплуатации имеющегося приложения!
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Отправить ссылку на страницу по e-mail
Обсудить на форуме
| Interface Ltd. Отправить E-Mail http://www.interface.ru |
|
| Ваши
замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 22.08.01 |