Последние десять лет кардинальным образом изменили рынок хранилищ данных. В начале нынешнего столетия большинство хранилищ данных использовалось для генерации нескольких отчетов, пакетной загрузки данных, запускаемой раз в день или даже в неделю, и время от времени для обработки нескольких нерегламентированных запросов, поступивших от небольшой группы пользователей. Сегодня сложные интеграционные инструменты позволяют интегрировать данные практически в режиме реального времени, все больше и больше пользователей применяют удобные в обращении средства Business Intelligence. Наконец, объемы данных, загружаемых в хранилище, растут с невероятной скоростью и, кажется, никогда не достигнут своего придела. Так, по оценке исследовательской компании WinterCorp, крупные хранилища данных увеличиваются втрое каждый два года. Согласно опросу среди корпоративных IT-специалистов в области хранилищ данных, проведенному Институтом Хранилищ данных (The Data Warehousing Institute, TDWI), к 2012 году 59% из числа опрошенных ожидают, что их хранилище данных превысит 3Тб.
Все эти факторы приводят к тому, что производительность хранилищ данных последние годы начинает падать, и сегодня проблема производительности выходит на первый план. Как отмечают аналитики Gartner, в ближайшие годы все потребители хранилищ данных в той или иной степени столкнуться с этой проблемой. В Gartner даже ввели специальный термин - смешанная нагрузка, который отражает влияния изменений произошедших за последние годы - рост объемов данных, усложнение запросов и т.д. (подробнее см. "Рынок СУБД для Хранилищ данных 2007. Итоги года, тенденции").
Каким образом можно оценить производительность хранилища данных? Сегодня эксперты - члены консорциума TCP1 - предлагают при оценке производительности системы учитывать следующие параметры:
- Время загрузки базы данных;
- Время исполнения запросов;
- Время сопровождения данных (обновления и изменения данных).
Стандарты оценки производительности
Производительность хранилища данных всегда была важным вопросом. Еще в далеком 1994 году консорциум TCP выпустил свою первую спецификацию для оценки производительности аналитических систем - TCP-D. Данный документ определял параметры оценки и регламентировал порядок проведения тестирования производительности.
Критерии оценки, заложенные в TCP-D, предъявляли серьезные требования к технологиям того времени - как к аппаратной, так и программной составляющей (СУБД). Согласно требованиям стандарта тестированию подвергались хранилища данных в третьей нормальной форме, содержащие 8 таблиц. С учетом ожидаемого роста данных, TCP-D предусматривал увеличение необработанных данных от 1 Гб до 3 Тб, при которых подсистемы ввода-вывода должны были достигнуть пределов своих возможностей. При оценивании хранилищ данных использовались предопределенные размеры баз данных, или коэффициенты масштабирования. Каждый коэффициент соответствовал заданному объему необработанных данных в хранилище. Для оценки оптимизаторов запросов использовались 17 сложных, долго выполняемых запросов, а также две функции сопровождения данных (insert и delete). Шесть из восьми таблиц увеличивались пропорционально коэффициенту масштабирования и заполнялись данными, которые были равномерно распределёны.
Последующее широкое распространение агрегатных/итоговых структур (например, индексов объединения, итоговых таблиц, аналитических выборок), которые не были заложены в TCP-D, привели к появление двух его модификаций - TCP-H (стандарт оценки производительности систем с нерегламентированными запросами) и TCP-R (стандарт оценки производительности систем для выпуска отчетности) в апреле 1999 года.
В новых стандартах были добавлены шесть новых запросов, а коэффициент масштабирования увеличен до 10Тб. В остальном TCP-H и TCP-R идентичны своему предшественнику. Различие же между TCP-H и TCP-R состоит в наличии информации о нагрузке, которая будет использована для оценки системы. TCP-H предназначен для среды, при работе с которой администраторы базы данных не знают, какие запросы будут переданы в систему. Следовательно, знания о запросах и данных не могут быть использованы для оптимизации СУБД. При применении TCP-R предполагается наличие исходной информации о запросах, что может быть использовано для определения агрегатных/итоговых структур. Поскольку TCP-R не получил сколь значимого внимания, в январе 2006 года он был признан утратившим силу.
В отличие от TCP-R стандарт TCP-H получил широкое распространение и активно используется до сих пор. В декабре 2007 года количество тестов, выполненных в соответствии с этим стандартом, превысило две сотни. Например, в августе прошлого года корпорация Oracle заявила о впечатляющих результатах тестирования хранилища данных на своей СУБД Oracle Database 11g.
Основной величиной, по которой оценивается производительность системы, является показатель QphH@size (Composite Query-per-Hour Performance Metric at Size - сложный показатель производительности запросы, выполненные за час, на заданном объеме данных ), который отражает вычислительные возможности системы по обработке запросов. Помимо, данного показателя при публикации результатов тестирования в обязательном порядке указывается стоимость системы для данного показателя QphH@size (исходя из используемой при тестрировании программно-аппаратной конфигурации), дата выпуска системы и другие дополнительные характеристики, например, время загрузки данных.
Новые стандарты оценки производительности: фокус на загрузке данных
Вряд ли кто станет отрицать, что требования, предъявляемые сегодня к системам хранилищ данных, претерпели существенные изменения с тех пор, когда был разработан TCP-D и его "приемник" TCP-H. Именно поэтому, чтобы продлить жизнь TCP-H консорциум TCP увеличил размеры объемов данных с помощью еще двух коэффициентов масштабирования - 30,000 и 100,000, что соответствует 30Тб и 100Тб необработанных данных.
Вместе с тем, различия между сегодняшними системами хранилищ данных и те, для оценки которых был спроектирован TCP-H, существенны и многообразны. Например, схема хранилища данных, которая была удовлетворительно сложной для тестирования систем в 1999 году, не отражает современные реалии построения сложных аналитических систем. Сегодняшние схемы включают гораздо большее количество таблиц и ушли от чистой третьей нормальной форме к разновидностям схемы типа "звезда".
Именно поэтому TPC разработал и выпустил в январе 2006 года рабочую версию нового стандарта TPC-DS, работа над которой продолжается и сегодня.
Основными характеристиками разрабатываемого стандарта является:
- Многочисленные схемы типа "снежинка" с совместно используемыми измерениями;
- 24 таблицы, каждая из которых содержит в среднем 18 столбцов;
- 99 различных запросов SQL-99 со случайными подстановками;
- Более репрезентативное (приближенное к реальному) содержание базы данных;
- В отличие от TCP-H таблицы данных изменяются пропорционально объему базы данных (коэффициенту масштабирования), таблицы измерений - непропорционально;
- Наличие нерегламентированных и итерационных запросов, а также запросов для выпуска отчетности и извлечения данных;
- Сопровождение данных, подобное процессам ETL.
Последний пункт заслуживает отдельного внимания. TPC-DS отводит главное место возможности системы включать новые данные про мере роста объемов исходных данных. Очевидно, что включение в состав теста операцией по работе с данными (трансформацией на основе SQL) позволяет говорить о TPC-DS как о первом отраслевом стандарте для оценки ETL-процессов (рис. 1).
Так, в отличие от стандарта TCP-H в расчете основного параметра оценки производительности системы по TPC-DS (Query-per-Hour Performance Metric at Scale Factor - показатель производительности запросы, выполненные в час, при заданном коэффициенте масштабирования ) учитывается как время создания базы данных (загрузки данных), так и время на сопровождение данных (процессы ETL):
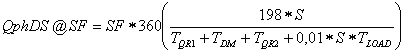
где TQR1 - время на выполнение запросов первой серии,
TQR2 - время на выполнение запросов второй серии,
TDM - время на выполнение операций по сопровождению данных,
TLoad - время на тестирование загрузки базы данных,
S - число потоков, которые выполняются при оценке производительности,
SF - коэффициент масштабирования. Проведение тестирования системы в соответствии с TPC-DS предусматривает выполнение следующей последовательности действий (см. рис. 1. Схема проведения оценки производительности хранилища данных в соответствии со спецификацией TPC-DS ):
- Тестирование загрузки базы данных;
- Тестирование производительности.
Под тестированием загрузки базы данных понимается создание тестовой базы. Оценке подлежит время, затрачиваемое на создание таблиц, загрузку данных, создание вспомогательных структур данных, создание и проверку ограничений, анализ таблиц и вспомогательных структур данных. Включение загрузки базы данных в тест было продиктовано необходимостью учесть ситуации, при которых происходит полная перезагрузка данных в системе (например, при модернизации аппаратной части).
Тестирование производительности состоит из выполнения двух серий запросов и сопровождения данных. При выполнении операций по сопровождению данных оценивается возможности системы загружать, добавлять и удалять данные, а также поддерживать вспомогательные структуры данных. Как известно, количество и сложность вспомогательных структур данных, которые используются в хранилище данных для уменьшения времени выполнения запроса, значительно увеличивает время на выполнение операций по сопровождению данных.
При тестировании сопровождения данных считается, что данные уже извлечены из исходных систем и представлены в виде плоских файлов, каждый из которых моделирует содержание одной таблицы в вымышленной учетной системе. В совокупности эти файлы образуют схему этой системы. В соответствии с требованиями TPC-DS, ETL-процесс включает интеграцию и консолидацию данных из учетных систем, что подразумевает применение смешанной нагрузки, которая включает трансформацию данных, начиная простыми операциями со строками и заканчивая сложной денормализацией 3-й формы и различными алгоритмами для поддержки медленно меняющихся измерений и таблиц фактов (см. рис. 2. Проведение тестирования сопровождения данных).
В соответствии с требованиями спецификации, на первом шаге данные загружаются во внутренние таблицы, каждый файл в одну таблицу. На втором шаге происходит трансформация внутренних таблиц для загрузки данных в таблицы хранилища. При этом возможны следующие виды трансформации:
- Источник непосредственно в целевое назначение: это наиболее общий случай трансформации, который применяется к таблицам в хранилища данных, которые имеют эквивалентную таблицу в схеме учетной системы.
- Несколько источников в одно целевое назначение: в этом случае третья нормальная форма схемы учетной системы преобразуется в денормализованную форму хранилища данных в результате объединения нескольких таблиц источника данных.
- Одна таблица источника данных в несколько целевых назначений: это наиболее редко используемая трансформация, которая применяется - в целях повышения производительности - если схема учетной системы менее нормализована по сравнению со схемой хранилища данных.
На третьем шаге производится управление данными, которые подлежат сохранению (например, медленно меняющиеся измерения). Наконец, на четвертом шаге происходит добавление новых записей данных и удаление записей на дату.
Как отмечают авторы нового стандарта, ожидается, что в ближайшем будущем TPC-DS получит широкое распространение и будет активно использоваться как поставщиками хранилищ данных для демонстрации возможностей своих систем, так и потребителями в процессе выбора системы.
В заключение стоит заметить, что актуальность процессов загрузки данных привела к тому, что консорциум TPC озаботился разработкой отдельной спецификации для тестирования ETL-процессов. Так, в 2008 году был сформирован комитет с целью подготовки стандарта для сравнения различных ETL-систем.
Публикации
- Магические квадранты Gartner для СУБД Хранилищ данных, 2009 год (Gartner Magic Quadrant for Data Warehouse Database Management Systems, 2009).
- Филипп Рассом (Philip Russom). Отчет об исследовании TDWI: "Платформы Хранилищ данных следующего поколения" (Next Generation Data Warehouse Platforms). 3-й квартал 2009 года.
- Ричард Уинтер (Richard Winter). "Масштабирование хранилища данных" (Scaling The Data Warehouse). Information Week. 17.10.2008.
- Джефф Келли (Jeff Kelly) "Решение проблемы эксплуатации перегруженных хранилищ данных: инструменты управления нагрузкой - "(Workload management tools key to running busy data warehouses), 13.04.2010.
- Рагхунатх Намбиар (Raghunath Nambiar), Мейкел Поусс (Meikel Poess). "Создание TPC-DS" (The Making of TPC-DS).
- Мейкел Поусс (Meikel Poess), Рагхунатх Намбиар (Raghunath Nambiar), Дэвид Уолраф (David Walrath). "Зачем использовать TPC-DS: анализ нагрузки" (Why You Should Run TPC-DS: A Workload Analysis).
[1] Консорциум TPC (Transaction Processing Performance Council) - некоммерческая организация, созданная с целью разработки стандартов тестирования производительности транзакционных систем и систем для поддержки принятия решения (хранилищ данных), а также распространения результатов тестирования.