

Реляционные СУБД занимают лидирующие позиции уже более 30 лет, однако эта ситуация может измениться в связи с растущей популярностью баз данных, не имеющих реляционных схем данных (или баз данных типа NoSQL). РСУБД предоставляют надежные средства хранения данных в системах с традиционной клиент-серверной архитектурой, которые, к сожалению, не всегда легко и дешево масштабируются путем добавления новых вычислительных узлов. Это становится весьма серьезным ограничением в эпоху таких Web-приложений, как Facebook и Twitter, которым хорошая масштабируемость крайне необходима.
Проблему масштабируемости не удалось решить ранним альтернативам реляционных СУБД (помните объектно-ориентированные базы данных?). В отличие от них СУБД NoSQL, подобные Bigtable и SimpleDB (от Google и Amazon соответственно), проектировались именно в расчете на высокую масштабируемость Web-приложений. NoSQL вполне могут оказаться решением критически важной проблемы масштабируемости, которая будет становиться все более актуальной по мере развития Web 2.0.
В этой статье серии Вторая волна разработки Java-приложений приводится введение в проектирование баз данных без использования схем, что представляет собой одну из главных трудностей при переходе на NoSQL для разработчиков, ранее работавших с реляционными СУБД. Вы увидите, что самое главное в этом процессе - начать проектирование с создания модели предметной области, а не реляционной модели. При работе с Bigtable (как в примерах ниже) вы можете рассчитывать на помощь Gaelyk - легковесной инфраструктуры, расширяющей возможности платформы Google App Engine.
Об этой серии.
Характерные черты разработки на Java существенно изменились с момента выхода первого релиза платформы. Благодаря зрелости открытых инфраструктур и аренде надежных сред развертывания, есть возможность собирать, тестировать и поддерживать Java-приложения без серьезных временных и денежных затрат. В этой серии Эндрю Гловер описывает ряд технологий, лежащих в основе новой парадигмы создания приложений на Java.
NoSQL: Нужен ли новый взгляд на мир?
Рассуждая о нереляционных базах данных, многие разработчики в первую очередь упоминают о необходимости изменения своего мировоззрения. Однако, на мой взгляд, это зависит от их любимого подхода к созданию моделей данных. Если вы привыкли начинать разработку приложения с создания структуры базы данных, в частности с описания таблиц и связей между ними, то проектирование нереляционного хранилища данных, например на основе Bigtable, потребует от вас изменения вашего подхода в целом. Если же вы обычно начинаете создание приложений с моделирования предметной области, то нереляционная структура Bigtable должна выглядеть более естественно.
Масштабируемость у них в крови.
Проблемы, связанные с потребностями высокомасштабируемых Web-приложений, привели к появлению новых решений. В частности, Facebook не может полагаться на реляционную БД для хранения информации. Вместо этого в ней используется хранилище пар типа "ключ-значение", т.е. фактически - высокопроизводительная хэш-таблица. Созданное на ее основе решение (проект Cassandra) в настоящее время также используется сервисами Twitter и Digg, а недавно было передано организации Apache Software Foundation. Другим примером компании, чей рост требовал альтернативных подходов к хранению данных, является Google, в котором была создана технология Bigtable.
В нереляционных базах данных не используется соединение таблиц, первичные или вторичные ключи (ключи присутствуют, но в менее строгом виде). Таким образом, вы будете сильно разочарованы, попробовав применить реляционное моделирование при создании модели данных для базы данных NoSQL. Гораздо проще начать с описания предметной области. При этом лично мне доставляет удовольствие гибкость нереляционной структуры БД, лежащей в основе модели предметной области.
Таким образом, сложность перехода на нереляционную модель данных зависит от вашего подхода к проектированию приложений, а именно: начинаете вы с реляционной схемы или описания предметной области. Начав использовать СУБД, подобную CouchDB или Bigtable, вам придется распрощаться с удобными инфраструктурами хранения данных, например Hibernate. C другой стороны, перед вами откроются широкие возможности для самостоятельного создания такой технологии для своих нужд. А в процессе ее создания вы познакомитесь с тонкостями баз данных NoSQL.
Сущности и связи
Нереляционные СУБД позволяют проектировать модель предметной области в виде набора объектов, причем эта возможность упрощается такими современными решениями, как Gaelyk. На следующем этапе вам предстоит отобразить созданную модель на структуру базы данных, что в случае использования Google App Engine не представляет никаких трудностей.
Ранее, в статье Инфраструктура Gaelyk в приложениях для Google App Engine, вы познакомились с Gaelyk - Groovy-библиотекой, которая упрощает работу с хранилищем данных Google. В настоящей статье немало внимания будет уделяться объекту Entity в Google. В листинге 1 приведен пример из предыдущей статьи, демонстрирующий работу с сущностями (entity) в Gaelyk.
def ticket = new Entity("ticket")
ticket.officer = params.officer
ticket.license = params.plate
ticket.issuseDate = offensedate
ticket.location = params.location
ticket.notes = params.notes
ticket.offense = params.offense
|
Объектное проектирование.
Предпочтение объектной, а не реляционной модели при проектировании базы данных прослеживается в современных инфраструктурах приложений, таких как Grails и Ruby on Rails. Эти платформы уделяют повышенное внимание именно созданию модели, беря на себя генерацию физической схемы базы данных.
Подобный подход к сохранению данных вполне приемлем, однако легко заметить, что он становится трудоемким при интенсивной работе с билетами, например, если их приходится создавать или искать в различных сервлетах. Частично эту задачу можно облегчить при помощи общего сервлета (или грувлета), но есть более логичное решение - создание объекта Ticket. Оно будет рассмотрено ниже.
Соревнования
Вместо того чтобы вернуться к примеру с извещениями из первой статьи о Gaelyk, мы рассмотрим новое приложение, иллюстрирующее методы, которые обсуждаются в этой статье. Оно будет манипулировать данными о соревнованиях и их участниках, причем, как следует из рисунка 1, в одном старте (Race) участвуют несколько спортсменов (Runner), а один спортсмен может быть участником многих стартов.

При моделировании этих отношений в реляционной базе данных нам потребовались бы три таблицы - третья должна была бы служить для связывания соревнований и участников по принципу "многое-ко-многим". К счастью, нам этого делать не придется. Вместо этого мы будем использовать Gaelyk в Groovy для отображения этой модели на структуру Bigtable, предоставляемую платформой Google App Engine. Наша задача существенно упрощается благодаря тому, что Gaelyk позволяет работать с сущностями как с ассоциативными таблицами (Map).
Масштабирование и шарды.
Шардинг - это вариант декомпозиции базы данных, при котором происходит репликация таблиц и логические распределение информации по вычислительным узлам. Например, на одном узле могут храниться данные обо всех учетных записях пользователей в США, а на другом - жителей Европы. Сложности шардинга обусловлены наличием связей между данными, размещенными на разных узлах. Это серьезная и сложная проблема, которая в ряде случаев не решается (в разделе Ресурсы приведена ссылка на мою дискуссию с Максом Россом из Google (Max Ross) на тему шардинга и сложностей масштабируемости реляционных баз данных).
Одной из привлекательных черт нереляционных моделей данных является то, что вам не требуется продумывать все детали заранее - последующие изменения могут вноситься гораздо проще, чем в реляционную схему. Учтите, я не имею в виду, что реляционную схему изменить нельзя. Это, безусловно, возможно, но задача упрощается при отсутствии схемы. В данный момент времени мы не будем описывать свойства объектов предметной области - о них позаботится динамический язык Groovy (в частности, он позволяет использовать объекты в качестве прокси при работе с Entity). Вместо этого мы рассмотрим сценарии поиска объектов в базе данных и связи между ними. В настоящее время СУБД NoSQL и различные инфраструктуры не предоставляют встроенных возможностей для реализации подобной функциональности.
Мы начнем с создания базового класса, объекты которого будут хранить экземпляры Entity. Его дочерние классы должны иметь динамический набор свойств, которые будут добавляться в соответствующий экземпляр Entity при помощи удобного метода setProperty в Groovy. Этот метод вызывается при установке значения каждого свойства, для которого нет set-метода (это может показаться странным, но не беспокойтесь - скоро все встанет на свои места).
В листинге 2 показан первый вариант класса Model демонстрационного приложения.
Листинг 2. Простой вариант базового класса Model
package com.b50.nosql
import com.google.appengine.api.datastore.DatastoreServiceFactory
import com.google.appengine.api.datastore.Entity
abstract class Model {
def entity
static def datastore = DatastoreServiceFactory.datastoreService
public Model(){
super()
}
public Model(params){
this.@entity = new Entity(this.getClass().simpleName)
params.each{ key, val ->
this.setProperty key, val
}
}
def getProperty(String name) {
if(name.equals("id")){
return entity.key.id
}else{
return entity."${name}"
}
}
void setProperty(String name, value) {
entity."${name}" = value
}
def save(){
this.entity.save()
}
}
|
Обратите внимание на конструктор этого абстрактного класса, в который передается ассоциативный массив (Map) свойств. Всегда можно добавить дополнительные конструкторы, что мы и сделаем ниже. Подобный подход довольно удобен для различных инфраструктур Web-приложений, которым часто приходится работать с параметрами, полученными через Web-формы. Gaelyk и Grails элегантно представляют такие параметры в виде объекта под именем params. Конструктор перебирает элементы Map и вызывает метод setProperty для каждой пары типа "ключ-значение".
Если взглянуть на метод setProperty, то становится ясно, что ключом является имя свойства entity, а значением - значение данного свойства.
Приемы программирования на Groovy
Как упоминалось выше, динамическая природа Groovy позволяет обращаться к свойствам, для которых не существует методов get и set. Таким образом, дочерним классам Model не обязательно объявлять собственные методы свойств - они могут делегировать все обращения к свойствам объекту entity.
В листинге 2 следует отметить несколько моментов, характерных для языка Groovy. Во-первых, метод при обращении к свойству можно не указывать, достаточно лишь добавить @ перед именем свойства. Это делается при создании объекта entity в конструкторе, поскольку иначе пришлось бы вызывать метод setProperty, что на данном этапе, разумеется, невозможно, поскольку переменная entity в этот момент равна null.
Во-вторых, при помощи вызова this.getClass().simpleName конструктор задает "тип" сущности. Значением свойства simpleName является имя конкретного дочернего класса без префикса пакета (при обращении к simpleName фактически вызывается метод getSimpleName, поскольку Groovy позволяет обращаться к свойствам без явного указания get-метода класса JavaBean).
Наконец, при обращении к свойству id вызывается метод getProperty. При работе с платформой Google App Engine ключи сущностей генерируются автоматически.
Класс Race, унаследованный от Model, очень прост (листинг 3).
package com.b50.nosql
class Race extends Model {
public Race(params){
super(params)
}
}
|
Экземпляр сущности создается в памяти в момент инстанциирования дочернего класса с использованием списка параметров (ассоциативного массива пар типа "ключ-значение"). Для сохранения сущности в базе данных необходимо вызвать метод save.
import com.b50.nosql.Runner
def iparams = [:]
def formatter = new SimpleDateFormat("MM/dd/yyyy")
def rdate = formatter.parse("04/17/2010")
iparams["name"] = "Charlottesville Marathon"
iparams["date"] = rdate
iparams["distance"] = 26.2 as double
def race = new Race(iparams)
race.save()
|
В листинге 4 показан грувлет, в котором создается экземпляр Map (переменная iparams), содержащий значения трех свойств - name, date и distance. Обратите внимание, что в Groovy пустой Map инициализируется при помощи конструкции [:]. После создания новый экземпляр Race сохраняется в базе данных при помощи метода save.
Содержимое базы данных можно просматривать при помощи консоли Google App Engine, чтобы убедиться, что данные были успешно сохранены (рисунок 2).
Рисунок 2. Просмотр созданного экземпляра Race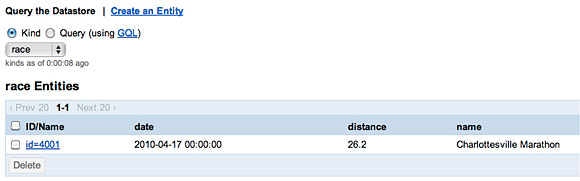
После сохранения экземпляра Entity было бы полезно иметь возможность выборки его из базы данных. Для этого служат поисковые методы. В данном случае мы добавим статический метод, который будет искать экземпляры Race по названию (т.е. по свойству name). Другие поисковые методы всегда можно будет добавить позже.
Кроме того, мы установим следующее соглашение об именовании поисковых методов: все методы, в названии которых отсутствует слово all , будут возвращать один сохраненный экземпляр. Остальные методы, например findAllByName, могут возвращать Collection или List экземпляров. Код метода findByName приведен в листинге 5.
static def findByName(name){
def query = new Query(Race.class.simpleName)
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
if(preparedQuery.countEntities() > 1){
return new Race(preparedQuery.asList(withLimit(1))[0])
}else{
return new Race(preparedQuery.asSingleEntity())
}
}
|
В этом методе используются классы Query и PreparedQuery для поиска сущности типа "Race", имеющего указанное свойство name. Если таковых сущностей несколько, метод вернет только первое из них, поскольку указана конструкция withLimit(1), ограничивающая число результатов.
Метод findAllByName выглядит очень похоже, но ему требуется дополнительный параметр, указывающий число требуемых результатов (листинг 6).
static def findAllByName(name, pagination=10){
def query = new Query(Race.class.getSimpleName())
query.addFilter("name", Query.FilterOperator.EQUAL, name)
def preparedQuery = this.datastore.prepare(query)
def entities = preparedQuery.asList(withLimit(pagination as int))
return entities.collect { new Race(it as Entity) }
}
|
Как и ранее, этот метод находит экземпляры Race по свойству name, однако возвращает все экземпляры, удовлетворяющие условию. Обратите внимание, насколько удобен метод collect в Groovy: с его помощью можно избавиться от цикла создания экземпляров Race на основе найденных объектов Entity. Кроме того, учтите, что Groovy разрешает использовать значения по умолчанию при вызове методов, поэтому если не передать второй параметр, то поиск будет ограничен 10 результатами.
def nrace = Race.findByName("Charlottesville Marathon")
assert nrace.distance == 26.2
def races = Race.findAllByName("Charlottesville Marathon")
assert races.class == ArrayList.class
|
Методы в листинге 7 работают в точности так, как ожидается: findByName возвращает один экземпляр, а findAllByName - набор экземпляров (если, конечно, в базе данных есть несколько соревнований с названием "Charlottesville Marathon").
Реализовав функциональность для создания и поиска экземпляров Race, можно переходить к классу Runner. Он создается так же просто, как и Race: достаточно унаследовать класс от Model, как показано в листинге 8.
package com.b50.nosql
class Runner extends Model{
public Runner(params){
super(params)
}
}
|
Итак, наше приложение практически завершено. Все, что осталось, - это описать связь между соревнованиями и участниками. Разумеется, это будет связь типа "многие-ко-многим", поскольку наши спортсмены должны быть способны участвовать в нескольких соревнованиях.
Моделирование информации без схемы
Абстракция базы данных Bigtable, предлагаемая Google App Engine, не является объектно-ориентированной: вы не можете сохранять связи, однако можете использовать общие ключи. Соответственно для моделирования отношения между соревнованиями и участниками мы будем сохранять список экземпляров Runner внутри каждого экземпляра Race и наоборот .
Нам придется добавить немного логики к нашему механизму общих ключей, чтобы API выглядел естественно: в частности, должна быть возможность получения списка именно спортсменов, а не их идентификаторов (ключей). К счастью, в этом нет ничего сложного.
В листинге 9 показаны два новых метода класса Race. При передаче экземпляра Runner в метод addRunner его идентификатор (id) добавляется в коллекцию runners объекта entity. Если эта коллекция уже существует, то новый ключ добавляется в конец; в противном случае создается новый объект Collection, после чего ключ добавляется в него.
def addRunner(runner){
if(this.@entity.runners){
this.@entity.runners << runner.id
}else{
this.@entity.runners = [runner.id]
}
}
def getRunners(){
return this.@entity.runners.collect {
new Runner( this.getEntity(Runner.class.simpleName, it) )
}
}
|
Коллекция экземпляров Runner создается на основе сохраненной в базе данных коллекции идентификаторов в момент вызова метода getRunners (см. листинг 9). Для этого нужен новый метод getEntity в классе Model. Его код приведен в листинге 10.
def getEntity(entityType, id){
def key = KeyFactory.createKey(entityType, id)
return this.@datastore.get(key)
}
|
Метод getEntity использует класс KeyFactory для генерации ключей, которые затем могут применяться для поиска экземпляров сущностей в базе данных.
Последнее, что необходимо сделать - это добавить новый конструктор класса Model, принимающий на вход экземпляр сущности любого типа (листинг 11).
public Model(Entity entity){
this.@entity = entity
}
|
Как видно из листингов 9, 10 и 11, а также объектной модели, показанной на рисунке 1, вы можете добавлять экземпляры Runner в любой объект Race и запрашивать список экземпляров Runner у объектов Race. Аналогичные методы можно также добавить в класс Runner, как показано в листинге 12.
def addRace(race){
if(this.@entity.races){
this.@entity.races << race.id
}else{
this.@entity.races = [race.id]
}
}
def getRaces(){
return this.@entity.races.collect {
new Race( this.getEntity(Race.class.simpleName, it) )
}
}
|
Таким образом, моделируется связь типа "многие-ко-многим" в базе данных без реляционной схемы.
Создание соревнований и участников.
Теперь нам осталось только создать экземпляр Runner и добавить его в Race. Если вы хотите, чтобы связь была двунаправленной (см. рисунок 1), то можете также добавить экземпляры Race в объекты Runner, как показано в листинге 13.
def runner = new Runner([fname:"Chris", lname:"Smith", date:34]) runner.save() race.addRunner(runner) race.save() runner.addRace(race) runner.save() |
После добавления нового Runner в соревнование и вызова метода Race.save в базе данных должен быть сохранен список идентификаторов, показанный на рисунке 3.
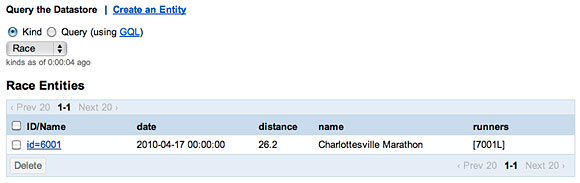
При подробном изучении данных в Google App Engine становится понятно, что новый экземпляр сущности Race содержит список экземпляров типа Runner (рисунок 4).
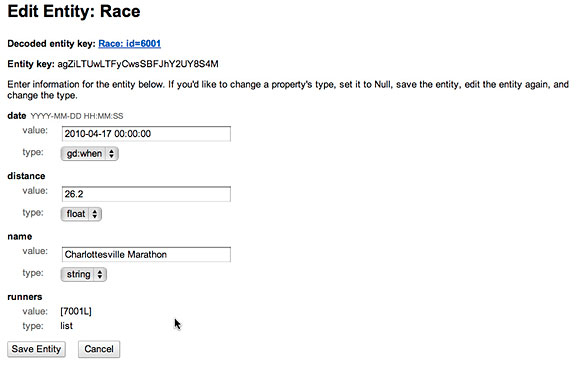
Аналогичным образом, свойство races не существует до момента добавления нового соревнования в только что созданный экземпляр Runner. Пример показан на рисунке 5.
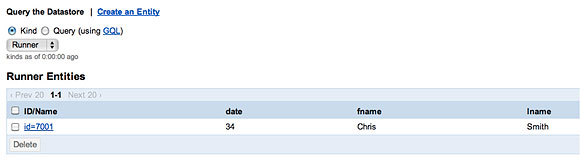
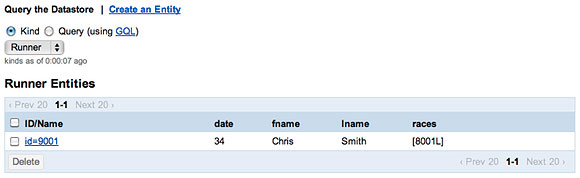
После добавления экземпляра Race в объект Runner база данных будет хранить список идентификаторов соревнований, в которых участвует этот спортсмен (рисунок 6).
Гибкость нереляционных баз данных впечатляет, в частности, тем, что свойства могут автоматически добавляться в БД по необходимости. При этом разработчикам не придется изменять схему, не говоря уже о ее развертывании.
Плюсы и минусы NoSQL
Разумеется, нереляционные модели данных имеют как преимущества, так и недостатки. Одним из преимуществ, которые были продемонстрированы на примере нашего приложения, является гибкость. Если нам потребуется добавить новое свойство в класс Runner, например номер социального страхования (SSN), то это не потребует серьезных усилий. Достаточно будет просто включить его в список параметров конструктора. При этом ничего страшного не произойдет с ранее созданными объектами, просто их свойство (SSN) будет содержать null.
Производительность.
Скорость выполнения операций очень важна при сравнении РСУБД и NoSQL. Для современных Web-сайтов, манипулирующих данными миллионов пользователей (в Facebook сейчас около 400 млн пользователей и их число постоянно увеличивается) реляционная модель оказывается слишком медленной и дорогой. В свою очередь, чтение данных в СУБД NoSQL выполняется невероятно быстро.
С другой стороны, в нашем примере согласованность базы данных явно принесена в жертву эффективности. Текущая модель данных приложения не накладывает никаких ограничений; например, можно создать неограниченное число экземпляров одного и того же объекта. Благодаря автогенерации ключей в Google App Engine все экземпляры будут иметь уникальные ключи, но все остальное будет идентично. Кроме того, не поддерживается возможность каскадного удаления, поэтому если применить тот же подход к хранению отношений типа "один-ко-многим", то возможна ситуация, при которой родительский объект будет удален, а дочерние останутся в базе данных. Разумеется, ничто не мешает вам реализовать собственную схему обеспечения согласованности, но в этом-то и кроется проблема: вам придется делать это самостоятельно (примерно так же, как мы реализовывали остальную функциональность).
Таким образом, работа с нереляционными базами данных требует определенной дисциплины. Если начать создавать различные типы соревнований, некоторые с названиями, некоторые без них, одни - со свойством date, другие - c race_date, то это приведет к головной боли и для вас самих, и для других разработчиков, которые будут использовать ваш код.
Разумеется, с базами данных в Google App Engine можно работать при помощи JDO и JPA. При этом, имея опыт общения как с реляционными, так и NoSQL-моделями в ряде проектов, я могу сказать, что низкоуровневый API Gaelyk является наиболее гибким и интересным. Еще одним его преимуществом является то, что вы ближе познакомитесь с особенностями Bigtable и общими принципами нереляционных баз данных.
Заключение
Причудливые новые технологии постоянно появляются и исчезают, и иногда безопаснее их игнорировать (это мой совет как успешного в финансовом смысле человека). Однако NoSQL не выглядит как некая причуда и вполне может стать основой для создания высокомасштабируемых Web-приложений. При этом NoSQL не заменят РСУБД, а скорее, дополнят их. Для реляционных баз данных существуют тысячи библиотек и утилит, поэтому их популярности ничего не угрожает.
NoSQL является своевременной альтернативой объектно-реляционной модели данных. Таким образом, было продемонстрировано, что возможно решение, которое лучше себя ведет в некоторых весьма существенных сценариях использования. Базы данных NoSQL наиболее подходят для Web-приложений, которые развернуты на нескольких узлах и которым необходимы высокая масштабируемость и скорость чтения данных. Кроме того, благодаря этим СУБД разработчики осознают подход к моделированию данных, который начинается с описания предметной области, а не проектирования таблиц.
Оригинал статьи: Java development 2.0: NoSQL (Эндрю Гловер, developerWorks, май 2010 г.). (EN)