Недавно, на конференции linux.conf.au 2012 разработчик XFS Дэйв Чиннер (Dave Chinner) заметил, что, по его мнению, XFS привлечет большее количество пользователей в будущем. Его доклад касался решения проблем с масштабированием, а также дальнейшей работы по улучшению файловой системы. Если верить его словам, возможно в ближайшие несколько лет мы услышим значительно больше об XFS.
XFS часто рассматривают как файловую систему для тех, кто работает с файлами больших размеров. По словам Дэйва, с этой задачей она справляется прекрасно, кроме того, XFS традиционно хорошо работает при больших нагрузках. Но ситуация ухудшается при записи метаданных. Поддержка записи большого количества метаданных в течение долгого времени является слабым местом для этой файловой системы. Говоря коротко, метаданные записываются очень медленно, и практически не масштабируются, даже при работе на одном CPU.
Насколько медленно? Дэйв привел несколько слайдов, на которых показаны результаты теста fs-mark в сравнении с ext4. Результаты XFS значительно хуже (практически в два раза) даже на одном CPU. С увеличением числа потоков до восьми ситуация еще больше ухудшается, после чего производительность ext4 также резко падает. Для работ, связанных с высокой нагрузкой на систему ввода/вывода, где необходимо изменять большое количество метаданных (в качестве примера была приведена распаковка тарболла), ext4 показала производительность в 20 - 50 раз больше, чем XFS. Такое отставание представляет собой действительно серьезную проблему.
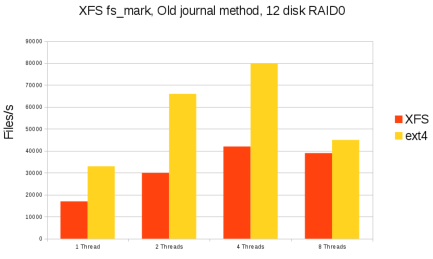
Отложенное журналирование
Проблема заключается в журнале ввода/вывода: XFS генерировала очень большое количество трафика для изменения метаданных. В худших случаях практически весь трафик ввода/вывода представлял собой данные для журнала, а не данные, которые пользователь пытался записать на диск. Попытки решения данной задачи в течение многих лет включали одно важное изменение алгоритма записи и множество других важных оптимизаций и настроек. Единственное, что не требовалось - любое изменение формата данных на диске, хотя оно может быть востребовано в будущем.
Нагрузки, связанные с изменением большого количества метаданных, могут в конечном итоге привести к тому, что один и тот же блок директории будет изменен много раз за короткий период времени, а каждое из этих изменений генерирует запись, которая должна быть сохранена в журнале. Это и есть источник огромного журнального трафика. Концепция решения этой проблемы очень проста: отложить обновление журнала и объединять изменения одного и того же блока в одной записи. На самом деле, для претворения в жизнь этой идеи в масштабируемой реализации потребовалось несколько лет тяжелой работы, но сейчас она уже работает. Отложенное журналирование для файловой системы XFS поддерживается в ядре версии 3.3.
Фактически технология отложенного журналирования была позаимствована у файловой системы ext3, поэтому алгоритм ее работы известен и требуется намного меньше времени для ее внедрения в XFS, чем если бы она разрабатывалась с нуля. Вместе с преимуществами в быстродействии это также значит значительное уменьшение объема кода. Если вы хотите более детально изучить, как работает эта технология, подробности можно найти в файле filesystems/xfs-delayed-logging.txt в дереве документации ядра.
Отложенное журналирование - это большое изменение, но не единственное. Быстрый способ резервирования места в журнале остается горячей темой в XFS. Сегодня он не требует блокировки, в то время как медленный способ все еще требует глобальной блокировки этой точки. Код асинхронной записи метаданных приводил к сильной фрагментации ввода/вывода, значительно уменьшая производительность. Теперь запись метаданных откладывается, а перед записью они сортируются. Это значит, что, по словам Дэйва, файловая система выполняет функции планировщика ввода/вывода. Но планировщик ввода/вывода работает с очередью запросов, которая, как правило, ограничивается 128 записями, в то время как очередь отложенных метаданных XFS может содержать многие тысячи записей, так что имеет смысл производить сортировку в файловой системе, до передачи метаданных системе ввода/вывода. "Активные элементы журнала (Active log items)" - это механизм, который повышает производительность при работе с большими сортированными списками элементов журнала путем накапливания изменений и применения их в пакетном режиме. Кроме того, кэшированные метаданные были удалены со страницы подкачки, так их наличие приводило к запросам на загрузку страниц в неподходящее время.
Сравнение файловых систем
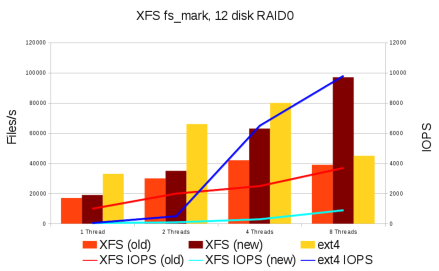
Как же XFS масштабируется после всех изменений? При работе с одним или двумя потоками она все еще немного медленнее, чем ext4, но с увеличением числа потоков до восьми ее производительность линейно возрастает, в то время как у ext4 ухудшается, а у btrfs ухудшается еще больше. На сегодняшний день масштабируемость XFS ограничивается блокировкой слоя ядра, работающего с виртуальными файловыми системами, а не кодом, связанным непосредственно с файловой системой. Обход директорий теперь работает быстрее даже с одним потоком, и еще быстрее при использовании восьми потоков.
Масштабируемость выделения дискового пространства в настоящее время на несколько порядков быстрее, чем в ext4. Это положение немного изменится после введения в релизе 3.2 функции "bigalloc", которая повышает масштабируемость выделения дискового пространства в ext4 на два порядка, если используется достаточно большой размер блока. К сожалению, при этом пропорционально увеличивается место, занимаемое на диске файлами малых размеров. Например, для размещения исходного кода ядра Linux в этом случае потребуется 160 Гб дискового пространства. Bigalloc не очень хорошо совместим с некоторыми другими функциями ext4 и требует сложной настройки. По словам Дэйва ext4 страдает от архитектурных недостатков - такие вещи, как использование битовых карт для отслеживания дискового пространства, были типичны для восьмидесятых годов. Она просто не может масштабироваться на действительно большие файловые системы.
Выделение дискового пространства в Btrfs происходит еще медленнее, чем в ext4. По словам Дэйва, проблема в основном заключается в перемещении кэша свободного дискового пространства, на которое затрачивается слишком много ресурсов процессора. Однако это не архитектурная ошибка, поэтому она может быть достаточно легко исправлена.
Будущее файловых систем Linux
На сегодняшний день проблемы с производительностью и масштабируемостью можно считать решенными. Теперь узким местом является слой VFS, поэтому дальнейшие усилия должны быть направлены на этот участок работы. Но самым большим вызовом в будущем будет проблема надежности хранения данных, и это может потребовать значительных изменений в файловой системе XFS.
Надежность заключается не только в том, чтобы не потерять данные - в этом вопросе, надеемся, XFS уже достаточно надежна, проблема также связана с масштабируемостью. Просто непрактично отключать петабайтную файловую систему, чтобы запустить ее проверку, или утилиту восстановления данных. В будущем просто необходимо сделать возможным проводить такие операции на работающей файловой системе. Это потребует надежного инструмента для обнаружения сбоев, встроенного в файловую систему, чтобы проверять метаданные на лету. Некоторые другие файловые системы имеют подобные механизмы, но, по словам Дэйва, для XFS такую систему лучше будет реализовать на уровне массивов устройств для хранения данных, либо на уровне приложений.
"Проверка метаданных" означает разработку метаданных, которые защищали бы себя от неправильно адресованных запросов на запись на уровне устройств для хранения данных. Проверки контрольной суммы недостаточно - она показывает только, что данные были записаны правильно. Метаданные с такой защитой могли бы определять блоки, которые были записаны в неправильное место и помогать в восстановлении целостности файловой системы при серьезных сбоях. Это также может помочь решить известную проблему reiserfs, которая заключается в том, что утилита для восстановления файловой системы вводится в заблуждение устаревшими метаданными, или метаданными, найденными в образах файловой системы.
Разработка таких метаданных потребует большого количества изменений. Каждый блок метаданных будет включать UUID файловой системы, к которой он принадлежит, а также номера блока и индексного дескриптора, чтобы файловая система могла определить, что метаданные переданы из правильного источника. Также здесь будут контрольные суммы для определения поврежденных блоков метаданных и собственный идентификатор для связывания метаданных с собственным индексным дескриптором или директорией. Обратное отображение дерева распределения позволит файловой системе быстро идентифицировать, какому файлу принадлежит любой блок.
Разумеется, нынешний формат XFS не обеспечивает хранения всех этих дополнительных данных, поэтому его необходимо будет менять. При этом, по словам Дэйва, не планируется сохранять какую-либо обратную совместимость с текущим форматом файловой системы. Это делается для того, чтобы предоставить полную свободу разработчикам в создании нового формата файловой системы, который будет использоваться в течение многих лет. Кроме добавления описанных выше возможностей, разработчики также планируют добавить пространство для d_type в структуре директории, счетчики версии NFSv4, время создания индексного дескриптора и, вероятно, что-то еще. Максимальный размер директории, который сегодня составляет всего 32 Гб, также будет увеличен.
При реализации всех этих функций появятся новые возможности: проактивное обнаружение повреждений файловой системы, локализация и замена отключенных блоков, а также улучшенное исправление ошибок файловой системы "на лету". Это значит, как сказал Дэйв, что XFS останется лучшей файловой системой для работы с большими объемами данных под Linux в течение долгого времени.
Каковы последствия всего этого с точки зрения перспектив btrfs? По словам Дэйва, btrfs явно не оптимизирована для работы с большим количеством метаданных - имеются серьезные проблемы с масштабируемостью. Этого и следовало ожидать от файловой системы, находящейся на ранней стадии разработки. Потребуется определенное время для решения этих проблем, а некоторые из них, возможно, окажутся неразрешимыми. С другой стороны, надежность хранения данных в btrfs находится на высоте, и в течение ближайших нескольких лет она может использоваться в таком качестве.
Ext4, напротив, страдает от проблем масштабируемости, связанных с ошибками в инфраструктуре. В любом случае, согласно результатам тестов, приведенных Дэйвом, она не является самой быстрой. Сказывается почтенный возраст ее архитектуры, хотя имеются планы по повышению ее надежности. Ext4 в ближайшее время будет бороться, чтобы остаться на уровне конкурентов.
В конце своего выступления Дэйв затронул еще несколько вопросов. По его словам, btrfs, благодаря своим достоинствам, вскоре заменит ext4 как файловую систему по умолчанию во многих дистрибутивах. В то же время ext4 уступает XFS на большинстве рабочих операций, включая те, где она была традиционно сильна. Проблема масштабируемости проявляется уже на небольших серверах. Кроме того, она не так стабильна, как о ней думают пользователи. В конце он спросил: "Почему же мы все еще используем ext4?"
Можно предположить, что у разработчиков ext4 имеется хороший ответ на этот вопрос, но, к сожалению, никто из них не присутствовал в зале. Так что, похоже, что это обсуждение должно быть продолжено в другом месте. Послушать его будет интересно.