
Сейчас уже никого не удивишь словами "клиент-серверная архитектура" и "реляционные СУБД". Но в далекие восьмидесятые, когда аппаратные требования были не в пример более скромными, о возможностях построения распределенных вычислений и о выделенных серверах баз данных задумывались только самые смелые творческие умы. Но уже тогда реальные потребности финансовых учреждений в качественно новых средствах управления данными и высокие требования к надежности и сохранности данных требовали решения стоящих проблем. Так на свет появилась компания Sybase.
Ориентация на решение проблем, стоящих перед передовыми в смысле обработки данных отраслями, такими как финансовые и банковские системы, заставляла компанию не просто выпускать новые программные продукты, но и искать новые подходы. Введение таких понятий, как транзакция, многоуровневая архитектура, хранимые процедуры и триггеры - вот лишь некоторые новшества, которые впервые появились именно в продуктах компании Sybase. И, хотя список производителей ПО, занимающих первые строчки "табели о рангах", постоянно меняется, компания Sybase сохраняет свое присутствие среди крупнейших поставщиков СУБД, особо удерживая свою монополию на Уолл-Стрит: крупнейшие финансовые институты США используют СУБД именно этой компании.
С годами спектр продуктов Sybase заметно расширился в сторону интернет-решений, ПО для мобильных вычислений, инструментальных средств и серверов приложений. Но сегодня мы поговорим о традиционных продуктах компании, предназначенных для создания ядра информационной инфраструктуры компании для хранения и обработки данных.
Практические нужды потребителей ПО показали, что любая фирма, независимо от ее размеров, нуждается в первую очередь не в отдельных серверах баз данных, а в комплексном решении, позволяющем интегрировать все потоки обрабатываемых данных в единый информационный комплекс. Создать универсальное решение, одинаково эффективно работающее как в маленьких отделах, так и в центральных аналитических службах предприятия, просто невозможно. Поэтому Sybase предлагает сразу три корпоративные СУБД, каждая из которых предназначена для решения своего сегмента задач (а в совокупности они покрывают весь спектр потребностей предприятия на всех уровнях обработки и хранения информации).
Общие свойства
Поговорим сначала о принципиальных особенностях, общих для всего семейства СУБД Sybase. В первую очередь это возможности расширения функциональности БД. В 80-е годы именно Sybase первой ввела в свои СУБД поддержку хранимых процедур и триггеров. Теперь же к совместимости используемого диалекта Transact-SQL с индустриальным стандартом ANSI SQL 92 добавлена возможность расширять функциональность и за счет подключения внешних программных модулей, реализованных, например, в среде Windows в виде DLL-библиотек. Последние же веяния, связанные с использованием трехуровневой архитектуры построения корпоративных приложений, предусматривают перенос реализации бизнес-логики с СУБД на уровень выделенного сервера приложений. Но иногда все-таки проектировщику корпоративных систем требуется вся мощь современных языков программирования, внедренная непосредственно в саму СУБД.
С этой целью в СУБД Sybase наравне с хранимыми SQL-процедурами можно использовать объекты и сам язык Java. Теперь наравне с обычными типами данных в БД можно хранить Java-классы. Помимо гибкости реализации бизнес-логики, это позволяет уже сейчас сделать первые шаги в построении объектно-ориентированных БД. А разнообразие инструментов, поставляемых как в составе стандартных Java-библиотек, так и в качестве самостоятельных продуктов третьих фирм, позволяет выйти за рамки принципиально ограниченных возможностей любых диалектов SQL.
Но почему в качестве универсального инструментального средства был выбран именно язык Java? Тут, конечно, сыграло роль не только широкое распространение Java и связанных с ним технологий в качестве индустриальных стандартов. Независимость от используемой программной и аппаратной платформы стала важным фактором именно для продуктов Sybase, которые работают не только на платформе Windows, но и с большинством используемых в корпоративной среде вариантов UNIX (включая Sun Solaris, IBM AIX, HP-UX и даже активно развивающийся в последнее время Linux).
Если говорить об общей стратегии Sybase, направленной на мультиплатформенность и совместимость с остальными элементами, надо обязательно упомянуть и встроенную поддержку формата XML, широко применяемого для передачи данных в Интернете и В2В-системах. Набор встроенных библиотек и возможность использования Java-парсеров позволяют непосредственно обрабатывать и хранить XML-документы в текстовом виде или в виде уже разобранного объектного документа.
Все эти характеристики относятся ко всей линейке СУБД Sybase. Единообразие их внешнего интерфейса легко объясняется тем, что во всех продуктах одинаково реализованы модули, которые обрабатывают поступающие в СУБД запросы. Поэтому и разработка баз данных для всех СУБД Sybase практически ничем не отличается друг от друга, позволяя легко переносить работающее ПО с одной СУБД на другую.
Три СУБД разного уровня
Как уже говорилось, компания Sybase поставляет три СУБД - Sybase Adaptive Server Anywhere, Sybase Adaptive Server Enterprise и Sybase Adaptive Server IQ.
Adaptive Server Anywhere - полнофункциональная СУБД, предназначенная для обработки данных в отделах и подразделениях нижнего и среднего звена и требующая минимум аппаратных ресурсов. Adaptive Server Enterprise - это уже серьезный высокопроизводительный сервер, способный работать на всех уровнях информационной системы предприятия и обеспечивающий максимальную производительность онлайновой обработки данных (OLTP). Последний продукт из линейки, Adaptive Server IQ, предназначен для аналитической обработки информации в так называемых хранилищах данных, о его особенностях мы поговорим ниже.
Adaptive Server Anywhere
Требования, предъявляемые этой СУБД к аппаратным ресурсам, действительно минимальны: 3 Мбайт оперативной памяти и 4 Кбайт на одно подключение пользователя. Продукт может полноценно работать не только на UNIX-платформах и под Windows NT/2000, но даже под Windows 9x, обеспечивая разработчику все возможности полнофункциональной корпоративной СУБД. Этот сервер баз данных хорошо использовать в небольших отделах, где число пользователей не превышает 10-15 человек. Можно даже вообще работать с сервером в персональном режиме, используя его только для промежуточного сбора и обработки информации перед ее отправкой в центральные подразделения предприятия.
Нацеленность на работу в небольших рабочих группах, занимающихся первичным сбором информации, обусловила появление пакета Sybase SQL Anywhere Studio, в комплект поставки которого, помимо самого сервера баз данных, входят развитые средства репликации. Причем речь идет о репликации не только онлайновой, но и работающей в условиях плохих линий связи. Традиционная структура промышленной компании подразумевает наличие головных офисов с мощными вычислительными средствами и линиями связи. А вот масса небольших отделов и представительств в регионах, выполняющих значительную долю работы перед отправкой текущих данных и информации в центр, довольствуется обычно достаточно старыми моделями компьютеров и в лучшем случае модемным подключением к телефонной сети невысокого качества.
Для таких небольших подразделений Adaptive Server Anywhere вполне может стать панацеей. Готовность работать на имеющихся компьютерах без их существенной модернизации дополняется в этой СУБД возможностью организовать (с использованием фирменной технологии SQL Remote) обмен данными с центральными офисами посредством электронной почты или даже путем передачи дискет с информацией через курьерскую службу. И это будет не тривиальное копирование таблиц с данными, а полноценная репликация с двухсторонней передачей только внесенных в БД изменений и сохранением транзакционной целостности информации.
Если же линии связи допускают периодическое подключение БД к центральным корпоративным хранилищам информации, то технология MobiLink позволит наладить репликацию на сессионной основе, путем синхронизации данных между центральным офисом и удаленным компьютером. В этом случае в качестве второй СУБД может выступать не только продукция Sybase, но также СУБД IBM, Oracle и Microsoft.
Возможности Adaptive Server Anywhere не ограничиваются простой экономностью в потреблении мощностей той машины, на которой запущена СУБД, - с ней можно полноценно работать и на персональных коммуникаторах. На карманных компьютерах, функционирующих под управлением Windows CE, PalmOS и других мобильных ОС, тоже можно запускать миниатюрный сервер БД. Используемая для этого технология UltraLite компилирует только ту часть базы данных, которая необходима для мобильного приложения, оптимизируя общий размер приложения вместе с СУБД так, что он не превышает 50 Кбайт. В результате на основе Adaptive Server Anywhere можно разворачивать сети обработки информации, в которых будут задействованы свободно перемещающиеся сотрудники компании с небольшими персональными коммуникаторами. Об эффективности такого решения говорит статистика: более 60% рынка мобильных вычислений принадлежит Sybase.
Adaptive Server Enterprise
Уяснив себе структуру построения информационной системы небольших рабочих групп, давайте обратимся к крупным узлам централизованной обработки информации. На этом уровне на сцену выступает Adaptive Server Enterprise. Классический сервер СУБД, обеспечивающий высокую скорость обработки транзакций в условиях большого количества одновременно работающих пользователей, этот продукт позволяет обрабатывать одновременно в одном запросе до 50 таблиц, работать с БД размером до нескольких терабайт, а аппаратные требования для нормального функционирования начинаются всего с 42 Мбайт оперативной памяти.
Для упрощения интеграции разрозненных фрагментов корпоративной системы Adaptive Server Enterprise обеспечивает доступ ко всем имеющимся в системе СУБД. Настроив внутри схемы БД так называемые прокси-таблицы, пользователь может осуществлять запросы и обработку информации в других СУБД. Внешне такая таблица выглядит как обычная таблица БД внутри СУБД Sybase, но на деле она отражает данные, хранящиеся на другом компьютере в СУБД другого производителя.
Поддержка встроенных систем защиты информации, передаваемой по каналам связи, и аутентификация пользователей позволяют применять такие индустриальные стандарты, как протоколы DCE/Kerberos, гарантируя, что ваши коммерческие тайны не станут достоянием хакеров.
Можно возразить, что некоторые из перечисленных характеристик Sybase Adaptive Server Enterprise - это стандарт для корпоративных СУБД. Но много ли предлагается на рынке систем, поддерживающих весь спектр возможностей сразу в одном продукте? Помимо традиционной поддержки разных компьютерных платформ и ОС, Adaptive Server Enterprise позволяет строить репликацию, работать с распределенными транзакциями и даже создавать отказоустойчивые кластерные системы. Версия продукта с опцией High Availability (HA) гарантирует работу СУБД даже в случае выхода из строя части аппаратного обеспечения. Таким образом, корпоративная система будет защищена от любых сбоев, работая круглосуточно 365 дней в году. Представьте себе только возможные финансовые потери от простоя информационной инфраструктуры предприятия в течение получаса, нескольких часов, дней... Особенно такие потери становятся ощутимы, если ведение бизнеса компании тесно интегрировано с Интернетом. Многие независимые эксперты оценивают готовность Adaptive Server Enterprise к производительной и бесперебойной работе в составе интернет-проектов именно как портал-готовность (portal ready).
Adaptive Server IQ
Внимательный читатель, оценив еще раз возможности Adaptive Server Anywhere и Adaptive Server Enterprise, может заметить, что эти два продукта полностью заполняют ниши вычислительных программ нижнего и верхнего уровня. Одна СУБД - рабочая лошадка, эффективно функционирующая на местах, а другая составляет оплот крупных центров обработки информации, обеспечивая высокую производительность и возможности при разумных требованиях к вычислительным ресурсам. Для чего же нужна еще одна, третья СУБД?
Оказывается, мало собрать информацию, очистить ее и предоставить для общего доступа. Когда речь заходит об аналитической и статистической обработке большого объема данных, вопросы производительности снова выходят на первый план. Обычно любой аналитический запрос так или иначе затрагивает большую часть собранных данных. А сколько времени нужно, чтобы просмотреть все строки таблицы размером в сотни гигабайт? Даже при современном развитии компьютерных технологий на выполнение таких запросов могут потребоваться часы, дни и даже недели. Целая индустрия аналитических средств обработки данных создала технологию многомерного анализа и построения витрин данных, позволяющих в ограниченной форме изучать накопленную информацию с разумным временем отклика на запросы.
Именно для таких аналитических структур, традиционно называемых хранилищами данных, и предназначен продукт Sybase Adaptive Server IQ. Независимые тесты показали, что производительность в аналитических запросах может увеличиваться в несколько сотен раз! Там, где обычная СУБД "думает" несколько часов, Adaptive Server IQ возвращает ответ в считанные минуты.
Дело здесь в том, что данные внутри Adaptive Server IQ хранятся не по строкам, а по столбцам. Кроме того, применяется несколько патентованных технологий сжатия и внутреннего представления информации. В результате массовый просмотр данных выполняется гораздо быстрее, а сама БД занимает даже меньше места на диске, чем неупакованные данные.
Adaptive Server IQ позволяет без изменения SQL-структуры таблиц и БД получить существенный выигрыш в быстродействии без предварительной обработки данных и построения промежуточных структур информации. Но не надо полагать, что этот сервер баз данных может заменить традиционные OLTP-серверы. Если начать выполнять на Adaptive Server IQ традиционные для онлайновой обработки операции вставки в таблицу строки данных, то вы обнаружите, что производительность таких операций будет гораздо ниже, чем у того же Adaptive Server Enterprise. Там, где хитроумная внутренняя структура хранения информации позволяет быстрее работать с аналитическими запросами, она же мешает быстро выполнять онлайновое проведение транзакций. Но в хранилищах данных этого и не требуется. Главное в них - уметь загрузить накопленную информацию и потом быстро провести ее аналитическую обработку. О скорости выполнения аналитических запросов мы уже говорили, а как дело обстоит с загрузкой информации?
Тут Adaptive Server IQ тоже устанавливает своеобразный рекорд: потоки накопленной вовне информации он может загружать в себя со скоростью 40 гигабайт в час. Некоторые компании даже не удосуживаются создать приличную схему репликации своих БД, а просто загружают их в хранилище целиком. А зачем, если возможности сервера позволяют?
Последняя версия продукта, получившая название Adaptive Server IQ Multiplex, дает возможность организовывать настоящие кластерные системы для аналитической обработки полученной информации. Производительность такой системы легко увеличить, добавив в кластер серверов БД необходимое число компьютерных систем.
Единая информационная система
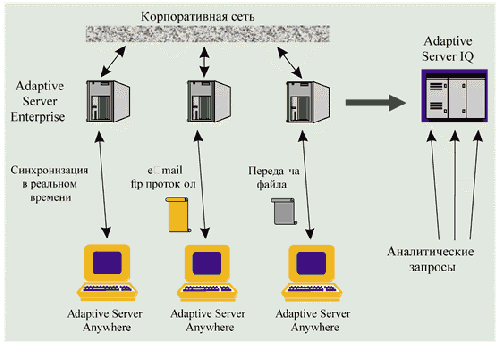
Вот теперь все элементы информационной системы встали на свои места, как показано на рисунке. Удаленные подразделения компании обрабатывают информацию и доставляют ее в головные офисы посредством Adaptive Server Anywhere, центральные вычислительные центры хранят и выполняют транзакционную обработку данных на Adaptive Server Enterprise, а аналитические подразделения планируют дальнейшую работу предприятия и подводят итоги его деятельности с использованием Adaptive Server IQ. Причем видно, что все три сегмента информационной структуры предприятия предъявляют настолько специфические и взаимно противоречивые требования, что использовать одну универсальную СУБД невозможно в принципе.
Но мало установить СУБД, необходимо еще разработать ее структуру и способы взаимодействия с другими программными элементами системы. Развитие компьютерной индустрии показало, что построение серьезных информационных систем и их дальнейшее сопровождение просто невозможно без использования специального ПО.
Столпы объектно-ориентированной парадигмы распространили свои идеи и на проектирование систем в целом, что привело даже к созданию стандартного языка описания UML для практического воплощения этих идей. Для поддержки объектно-ориентированной разработки систем, основанных как на собственных СУБД компании, так и на продуктах других производителей, Sybase уже несколько лет предлагает пакет PowerDesigner . Версия PowerDesigner Object Architect позволяет не только проектировать структуру БД на концептуальном и физическом уровнях, но и разрабатывать внутреннюю и внешнюю структуру всего ПО, входящего в информационную систему. Благодаря совместимости с языком UML можно использовать наработки из других систем проектирования и стандартизировать методики построения системы в соответствии с последними разработками в этой области.
Простые операции рисования кубиков данных таблиц, иерархии объектов и динамики их взаимодействия, вплоть до взаимных вызовов во время выполнения отдельных операций, позволяют в наглядной и понятной форме описать и задать все тонкости функционирования корпоративной системы на любом уровне детализации процесса. Как и многие другие системы объектно-ориентированного проектирования, PowerDesigner позволяет автоматически сгенерировать всю необходимую документацию по вашей корпоративной системе.
Кроме PowerDesigner, у Sybase есть и другие продукты, предназначенные для построения всей информационной инфраструктуры предприятия. Это инструментальные средства PowerBuilder и PowerJ, мощный сервер приложений Enterprise Application Server, специальные средства для построения единой репликационной инфраструктуры Replication Server и многие другие. Главное, что все они нацелены на интеграцию систем масштаба предприятия в цельный, надежно функционирующий механизм, объединяющий в себе программные продукты не только компании Sybase, но и любых других поставщиков.