
Компонент Performance Advisor, появившийся в Rational Developer for Power Systems Software 8.5, содержит богатый набор инструментов, которые позволяют повысить производительность приложений на C/C++, работающих на IBM Power Systems. В этом руководстве Майк Кучера познакомит вас с основной функциональностью Performance Advisor и покажет на примере, как улучшить производительность приложения.
В версии 8.5 продукта IBM Rational Developer for Power Systems Software появился новый компонент под названием Performance Advisor, который предоставляет богатый набор функций для настройки производительности приложений на языках C и C++ на IBM AIX и IBM PowerLinux.
Performance Advisor отличается простотой использования и эффективностью. Для новичка в настройке производительности Performance Advisor является отличным способом начать работу, поскольку его пользовательский интерфейс прост, а сам он предоставляет множество отзывов и рекомендаций. Опытный настройщик производительности найдет в нем богатый набор инструментов для эффективного выявления и устранения проблем.
Rational Developer for Power Systems Software (неофициально его часто называют RD Power или RDp) широко известен своими средствами разработки и отладки, с которыми хорошо интегрирован Performance Advisor. Вы можете использовать Performance Advisor в качестве автономного инструмента, а можете легко интегрировать его в существующий код, компоновку, тест или цикл отладки.
В этом руководстве подробно описывается пример из практики использования Performance Advisor.
Освоение настройки производительности
Сначала заглянем под капот Performance Advisor, чтобы увидеть, как он работает.
Откуда поступают данные о производительности
Performance Advisor получает данные из нескольких источников. Необработанные данные о производительности приложений поступают от низкоуровневых средств операционной системы, которые через постоянные промежутки времени фиксируют состояние процессора и памяти. Отладочная информация, генерируемая компилятором, позволяет соотнести эти данные с исходным кодом. XLC-компиляторы могут генерировать XML-файлы отчетов с информацией об оптимизациях, которые были выполнены во время компиляции. И, наконец, для определения возможных проблем анализируются системы компоновки и исполнения приложения.
Все эти данные автоматически собираются, сопоставляются, анализируются и представляются вам в удобной для доступа и понятной форме. Это облегчает выбор лучшей стратегии оптимизации вашего приложения.
Основным источником данных о производительности на AIX является команда tprof (в Linux ей эквивалентна OProfile).
Во время работы приложения команда tprof выполняется примерно каждые 10 миллисекунд, записывая выборку состояния указателя команд процессора, содержащую адрес памяти выполняемой в данный момент команды. Каждая выборка называется тик (tick). После завершения прогона отладочная информация, сгенерированная компилятором, используется для отображения каждого тика на соответствующие строки исходного кода. Сопоставив эти данные, можно сказать, какие части программы выполняются чаще всего. Эти части называются горячими и являются, как правило, лучшим местом для начала поиска возможностей оптимизации программного кода.
Команду tprof можно запускать непосредственно из командной строки AIX, но этот путь довольно сложен. Эта команда обладает широкими возможностями настройки и имеет множество параметров командной строки. Она генерирует очень большие файлы необработанных данных, ручной анализ которых может занять много времени. Performance Advisor использует tprof для сбора необработанных данных о производительности, но делает это прозрачно. Поэтому конечному пользователю не приходится иметь дело с низкоуровневыми средствами напрямую.
Подводные камни в данных о производительности, основанных на выборках
Во время профилирования приложения на целевой системе может выполняться несколько процессов. Понятно, что многие тики могут относиться к конкурирующим процессам. Поэтому лучше выполнять прогон на сравнительно "спокойной" системе. Идеальным вариантом для тестирования производительности является выделенная машина.
Поскольку необработанные данные основаны на выборках, увеличение числа выборок увеличивает статистическую значимость полученных данных. Мы предполагаем, что прогон приложения выполняется по крайней мере 30 секунд (желательно намного дольше). Для этого можно подобрать входные данные, которые обеспечат длительную работу приложения, или запускать приложения несколько раз в цикле сценария.
Выборки данных стека вызовов также собираются низкоуровневыми средствами операционной системы. Эти данные поступают от команд procstack в AIX и OProfile в Linux.
Выборки стека вызовов приложения осуществляются через постоянные промежутки времени, а все выполняющиеся в этот момент функции приложения записываются. Пути выполнения вызовов любой интересующей вас функции и из нее можно исследовать с помощью графического средства просмотра. На основании этой информации можно ответить на вопрос, почему данная функция является "горячей" - потому, что выполняется слишком долго или потому что вызывается слишком часто?
Производительность приложения также зависит от способа его компоновки и от среды, в которой оно выполняется. Часто простое изменение в среде компоновки или выполнения может сильно повлиять на производительность приложения без изменения его исходного кода.
Performance Advisor анализирует хосты компоновки и выполнения и оценивает их по нескольким критериям, таким как оборудование, операционная система, версия компилятора и параметры компоновки. Генерируется отчет System Scorecard, предоставляющий рекомендации по улучшению конфигурации системы для повышения производительности приложений. С него хорошо начинать тем, кто ищет легкие пути.
Отчеты компилятора о преобразованиях
XLC-компиляторы могут создавать XML-файлы отчетов, в которых описываются оптимизации, выполненные во время компиляции. Эти отчеты не являются строго обязательными, но их создание предоставляет больше информации для анализа. Важно, что эти отчеты показывают места вызовов функций, встраиваемых во время компиляции.
Руководство: использование Performance Advisor для повышения производительности C++-приложений
Performance Advisor можно использовать для анализа и сравнения производительности приложений на нескольких машинах под управлением AIX или PowerLinux, но для простоты мы сосредоточим внимание на настройке производительности на одном компьютере под AIX.
Пример приложения под именем Raytracer, используемый в данной статье, приведен в разделе Загрузки. Raytracer - это небольшое приложение на C++, которое генерирует файлы изображений различных геометрических фигур. Мы будем использовать Performance Advisor для постепенного повышения производительности этого приложения и сравнения ее с базовой.
Вы можете загрузить программу RayTracer и следовать указаниям данного руководства, но имейте в виду, что результаты зависят от системы, в которой работает приложение, так что вы получите числа, отличающиеся от чисел в рассматриваемых примерах.
Предварительные требования
Вы должны иметь доступ к серверу AIX с XLC 11.1 и установленным серверным компонентом Rational Developer for Power Systems Software.
- Начните с перехода в перспективу Performance Advisor (Window > Open Perspective > Other Performance > Advisor).
Рисунок 1. Перспектива Performance Advisor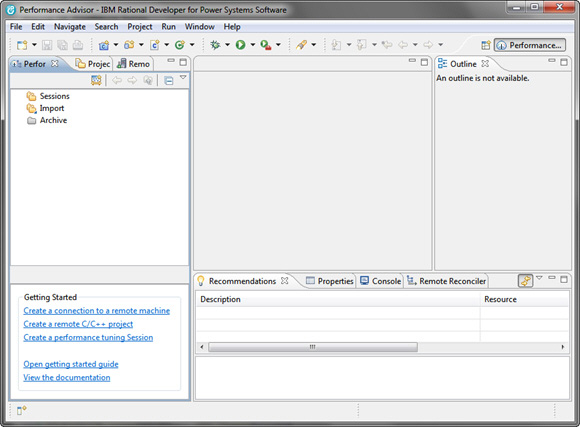
Прежде всего нужно подключиться к удаленной машине, на которой будут выполняться сборка и прогон приложения.
- Перейдите в представление Remote Systems и в New Connection щелкните правой кнопкой мыши на узле AIX, выберите New Connection, а затем следуйте указаниям мастера.
Рисунок 2. Создание нового подключения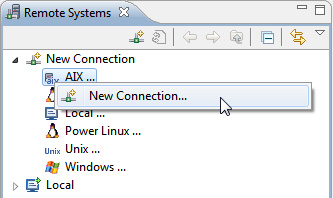
Теперь нам нужен удаленный проект на C++, который мы будем использовать для редактирования и компоновки нашего приложения.
- Извлеките исходный код Raytracer в папку где-нибудь на удаленной машине.
- В главном меню выберите New > Remote C/C++ Project.
Рисунок 3. Создание удаленного проекта на C/C++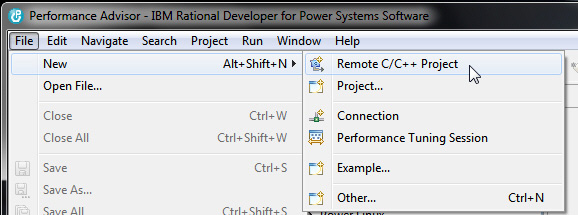
- Следуйте указаниям мастера для настройки проекта. (В Rational Developer for Power Systems Software есть несколько типов удаленных проектов, но Performance Advisor поддерживает все).
Рисунок 4. Мастер нового удаленного проекта на C/C++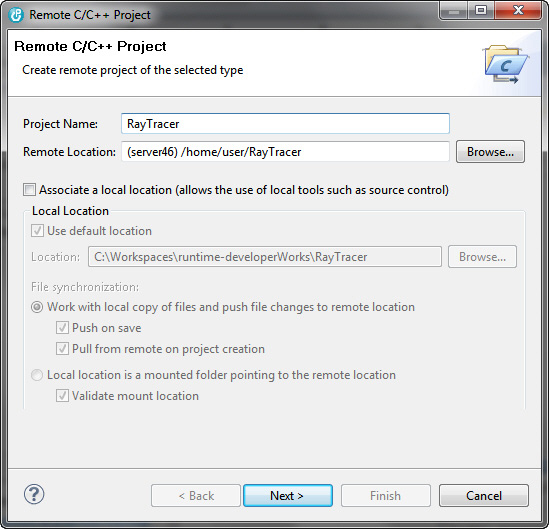
Приложение должно быть откомпилировано с отладочной информацией, позволяющей собирать данные о производительности на уровне строк. Для обоих компиляторов (XLC и GCC) это делается при помощи параметра -g. Кроме того, при использовании XLC необходим параметр -qlistfmt=xml=all для создания XML-отчетов преобразования в процессе компоновки.
Более подробное описание параметров компилятора, используемых Performance Advisor, приведено в документации. В файле makefile, сопровождающем Raytracer, указаны необходимые параметры для XLC на платформе AIX.
Мы хотим запускать приложение Raytracer из интегрированной среды разработки.
- В главном меню выберите Run > Run Configurations.
Рисунок 5. Диалоговое окно Run Configurations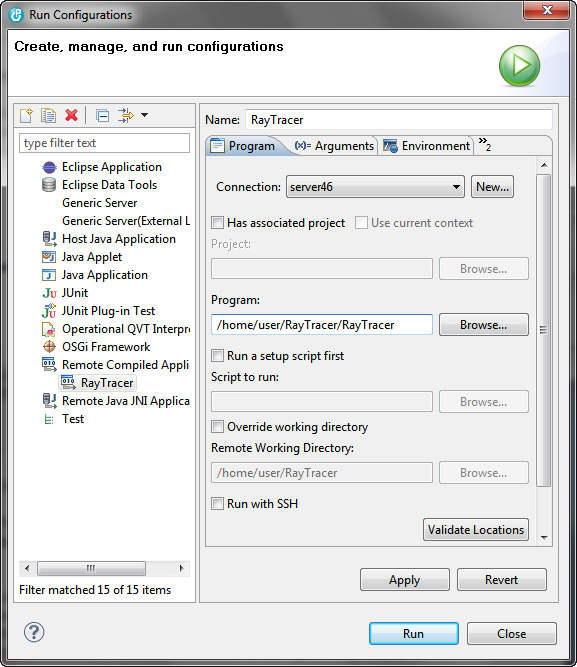
- В диалоговом окне дважды щелкните на Remote Compiled Application, а затем перейдите в папку исполняемого файла RayTracer.
Совет.
Нажав кнопку Run, вы увидите, что Raytracer запускается на удаленном компьютере и вывод на консоль отображается локально в представлении Console View.
Создание сеанса настройки производительности
Теперь начинается самое интересное - настройка производительности приложения.
Основным представлением Performance Advisor является представление Performance Explorer. С него начинаются выполнение прогонов, организация данных и анализ результатов.
Прогоны организуются при помощи двух артефактов: Sessions (сеансы) и Activities (действия). Каждое действие (Activity) представляет собой один прогон приложения, а сеанс (Session) - это просто перечень действий. Есть два вида действий: System Scorecard (показатели системы) и Hotspot Detection (определение горячей точки). Оба будут рассмотрены ниже.
- Для создания сеанса нажмите кнопку New Session на панели инструментов в верхней части представления Performance Explorer, после чего откроется мастер New Performance Tuning Session.
Рисунок 6. Кнопка New Session на панели инструментов
Рисунок 7. Мастер New Performance Tuning Session, первая страница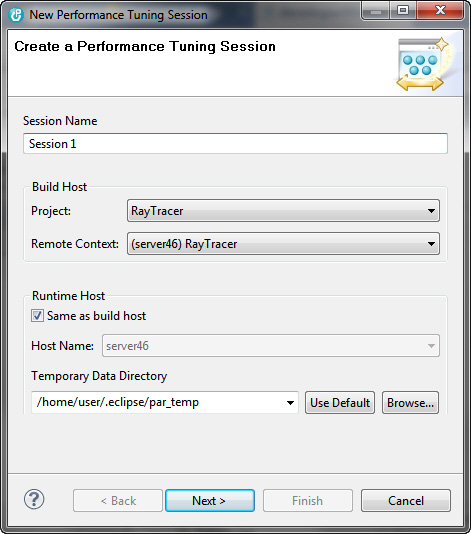
Мастер New Performance Tuning Session можно использовать для настройки сложных сценариев, таких как настройка больших приложений на нескольких машинах. В нашем случае мы создадим простой сценарий компоновки и настройки небольшого приложения Raytracer на одной машине.
На первой странице мастера запрашивается следующая информация:
- Имя сеанса.
- Хост компоновки. В Rational Developer for Power Systems Software 8.5 появилась новая функция, которая позволяет синхронизировать удаленный проект между несколькими хостами. В проектах, использующих эту функции, здесь выбирается хост компоновки. Мы используем только один хост, поэтому оставляем значение по умолчанию
- Хост выполнения. Performance Advisor поддерживает сценарий, в котором компоновка выполняется на одном хосте, а прогон на другом. Он предназначен для организаций, которые имеют выделенные машины для тестирования производительности, а также для тех, кто хочет протестировать свои приложения на другой машине (не там, где они компоновались), но не хочет копировать туда все файлы проекта. В нашем случае прогон и компоновка выполняются на одном и том же хосте.
- Каталог временных данных. Во время сбора данных о производительности создаются временные файлы. Необходимо предоставить папку для хранения этих файлов во время прогона (после прогона они автоматически удаляются). Нажмите кнопку Use Default, чтобы выбрать папку по умолчанию в вашем домашнем каталоге.
- После ввода этой информации нажмите кнопку Next.
Рисунок 8. Мастер New Performance Tuning Session, вторая страница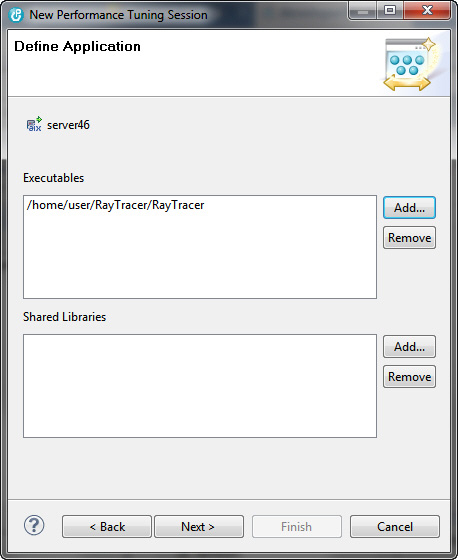
На второй странице мастера нужно указать местоположение исполняемых файлов и динамических библиотек, из которых состоит приложение. Эта информация используется для предоставления более точных рекомендаций (эти данные можно обновить после создания сеанса).
- Перейдите в папку исполняемого файла RayTracer и добавьте его в список исполняемых файлов.
- Нажмите кнопку Next.
Рисунок 9. Мастер New Performance Tuning Session, третья страница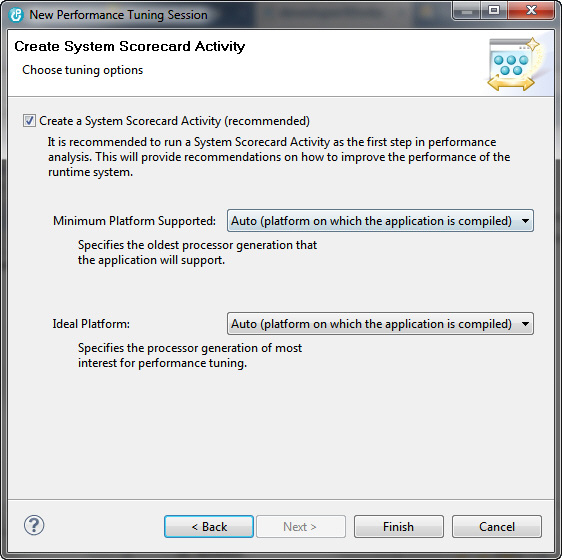
На третьей странице вам будет предложено создать действие System Scorecard Activity вместе с новым сеансом. Это рекомендуется сделать при первой настройке производительности на конкретном удаленном компьютере. На этой странице вы можете задать минимальный и предпочтительный вариант платформы Power. Сгенерированные рекомендации будут предназначены для предпочитаемых вами платформ.
- Для нашего простого примера просто оставьте значения по умолчанию и нажмите кнопку Finish.
Новые сеанс и действие отобразятся в представлении Performance Explorer.
Рисунок 10. Performance Explorer с новыми сеансом и действием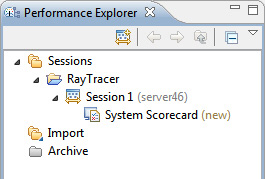
Действие System Scorecard находится в состоянии new, означающем, что оно готово к запуску. Для запуска действия используется нижняя панель Performance Explorer.
- Выберите действие System Scorecard и нажмите кнопку Begin Data Collection.
Рисунок 11. Запуск действия System Scorecard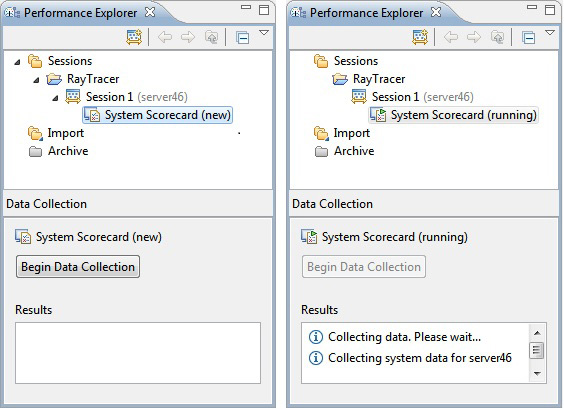
Действие переходит в состояние running (выполняется). Performance Advisor анализирует хост выполнения и исполняемый файл в фоновом режиме. Когда этот процесс завершится, действие перейдет в состояние complete (завершено). Время завершения появится рядом с действием.
- Дважды щелкните на действии, чтобы открыть окно System Scorecard.
Рисунок 12. Окно System Scorecard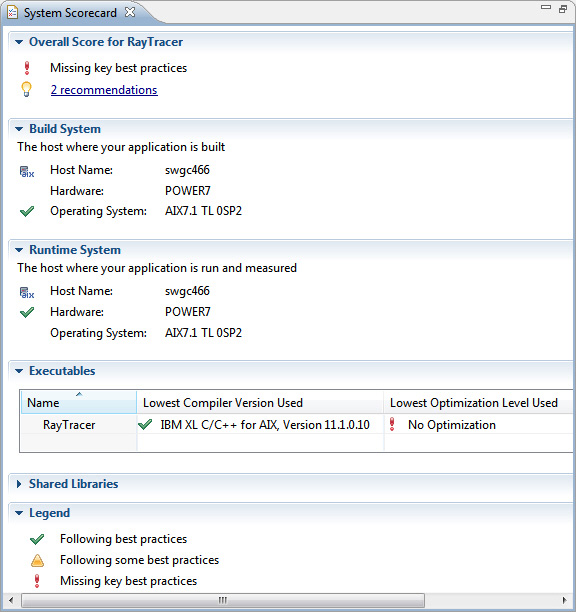
Очевидно (см. рисунок 12), что мы игнорируем некоторые ключевые рекомендации. Оказывается, что приложение Raytracer компоновалось с отключенной оптимизацией компилятора.
- Посмотрим, что можно сделать, нажав ссылку 2 recommendations, чтобы открыть представление Recommendations.
Представление Recommendations содержит автоматически сгенерированные рекомендации для выбранного действия. Каждой рекомендации соответствует Confidence Level (уровень доверия), и чем выше Confidence Level, тем больше вероятность, что выполнение рекомендации положительно повлияет на производительность.
Рисунок 13. Представление Recommendations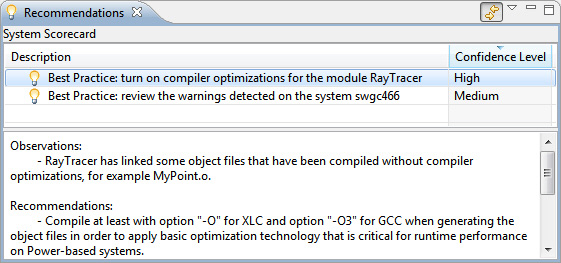
Performance Advisor определил, что приложение нужно перекомпоновать с использованием параметра компилятора -O. Это быстрый и простой способ улучшения производительности.
Повышение уровня оптимизации скорее всего увеличит время выполнения компоновки. Performance Advisor будет выборочно рекомендовать повышение уровня оптимизации для самых горячих частей приложения. Это позволяет получить максимальную выгоду за счет оптимизации горячих частей приложения, избегая при этом затрат времени на оптимизацию частей, которые мало влияют на общую производительность.
Определение базы для сравнения
Performance Advisor рекомендовал перекомпоновку Raytracer с более высоким уровнем оптимизации компилятора. Но перед этим рекомендуется определить базу для сравнения. Для этого нужно выполнить прогон приложения до внесения изменений.
- Щелкните правой кнопкой мыши на Session и выберите New Activity.
- Создайте новое действие Detection Hotspot, назовите его Hotspot Detection 1 и используйте созданную ранее конфигурацию запуска.
Новое действие появится в представлении Performance Explorer.
Рисунок 15. Performance Explorer с Hotspot Detection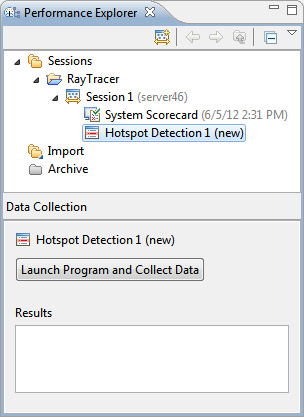
- Выберите только что созданное действие и нажмите кнопку Launch Program and Collect Data.
- Когда действие завершится, щелкните на нем правой кнопкой мыши и выберите Set as Baseline.
Рисунок 16. Установка базы для сравнения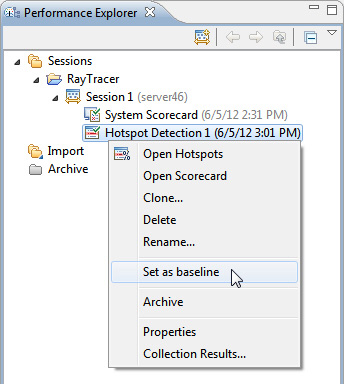
- Откройте файл makefile, добавьте -O2 в параметры компилятора и перекомпонуйте приложение.
Рисунок 18. Редактор файла makefile
Посмотрим, как это повлияло на производительность приложения.
- Создайте еще одно действие Hotspot Detection, присвойте ему имя Hotspot Detection 2 и выполните его.
- Когда оно закончится, щелкните на нем правой кнопкой мыши и выберите Compare with Baseline.
Откроется браузер сравнения горячих точек, показанный на рисунке 19.
Рисунок 19. Браузер сравнения горячих точек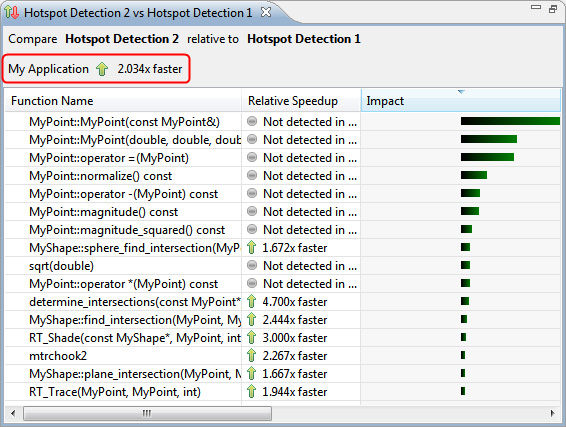
Это средство просмотра сравнивает результаты двух прогонов. В верхней его части говорится, что приложение стало работать примерно в 2 раза быстрее. Это отличный результат для такого небольшого изменения!
Анализ данных о производительности
Теперь попробуем внести изменения в само приложение. Но прежде нужно посмотреть на данные о производительности и выяснить, какие изменения мы должны сделать.
Дважды щелкните на Hotspot Detection 2, чтобы открыть браузер горячих точек.
Рисунок 20. Браузер горячих точек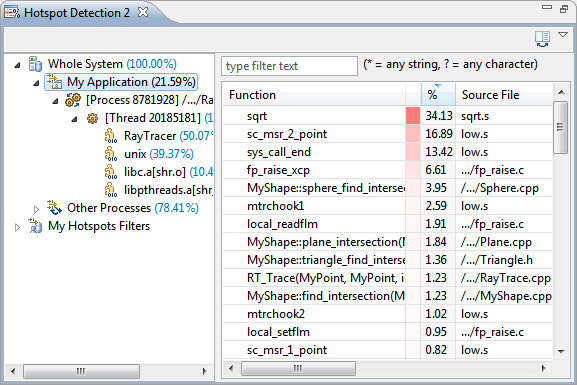
В левой части браузера горячих точек отображается дерево иерархии процессов. Это дерево содержит все процессы и потоки, по которым в ходе прогона делались выборки.
Процессы профилируемого приложения собраны в узле My Application. Все другие процессы, выполняющиеся в системе одновременно с приложением, собраны в узле Other Processes.
Узел My Application можно развернуть, чтобы исследовать процессы, потоки и модули, входящие в приложение. Приложение Raytracer является однопоточным, поэтому в нашем примере показан только один поток. Каждый поток и процесс многопоточных или многопроцессных приложений можно исследовать индивидуально или в виде группы.
При выборе узла дерева иерархии процессов отобразятся функции, по которым выполнялись выборки на данном уровне иерархии. По умолчанию функции отсортированы по занимаемому времени. Самые горячие функции находятся в верхней части списка, что дает хорошую отправную точку для настройки производительности.
Эти данные показывают, что значительную часть времени выполнения приложения занимает функция sqrt. Но sqrt - библиотечная функция, поэтому мы не можем напрямую изменить ее. Кроме того, оптимизация кода библиотеки не наша работа. Вместо этого попробуем выяснить, как используется sqrt в нашем приложении.
Фильтрация и поиск функций
Hotspot Browser имеет две функции, облегчающие поиск:
- Создание фильтров по дереву процессов. Фактически узлы My Application и Other Processes - это всего лишь встроенные фильтры. Любые пользовательские фильтры помещаются в узел My Filters. Чтобы создать свой собственный фильтр, просто щелкните правой кнопкой мыши на узле My Filters и выберите New Filter.
- Кроме того, при поиске функции с определенным именем можно фильтровать таблицу функций, введя часть имени функции в поле фильтра над таблицей. Поддерживается групповой символ * (звездочка), который полезен при работе со сложными именами C++-функций.
- Щелкните правой кнопкой мыши на строке sqrt в таблице горячих точек и выберите Show callers/callees, после чего откроется браузер вызовов.
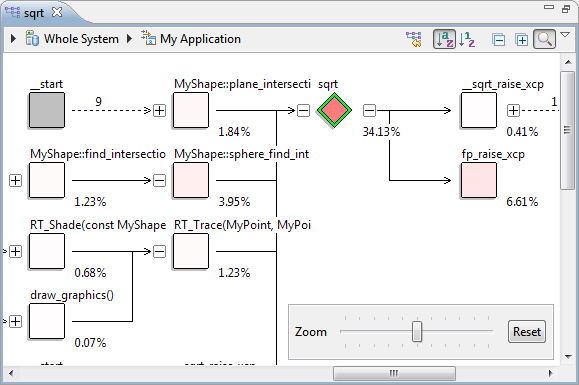
Браузер вызовов отображает одну функцию за раз и содержит графическое представление всех выборок стеков вызовов, включающих эту функцию.
Браузер вызовов очень гибок. Он позволяет выполнять масштабирование, выявлять конкретные пути вызовов и концентрироваться на различных частях приложения. Здесь мы видим, что самая горячая функция, вызывающая sqrt , выглядит так:
MyShape::sphere_find_intersection
Давайте посмотрим на код этой функции.
- Щелкните правой кнопкой мыши на узле sphere_find_intersection и выберите Open Source.
Рисунок 22. Пункт меню Open Source
Средство просмотра исходного кода
Средство просмотра исходного кода отображает исходный код функции
sphere_find_intersection
Исходный код отображается вместе с данными о производительности на уровне строк (см. рисунок 23). Слева от кода приводится время выполнения каждой строки в процентах.
Рисунок 23. Средство просмотра исходного кода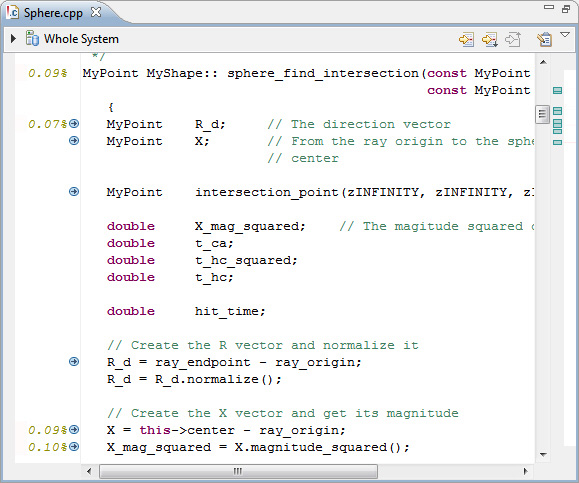
За средством просмотра исходного кода следует стандартное представление Outline. Когда средство просмотра исходного кода открыто, представление Outline показывает разбивку блоков кода в пределах каждой функции в файле. Его можно использовать для поиска горячих блоков кода, например горячих циклов.
Рисунок 24. Стандартное представление Outline в Eclipse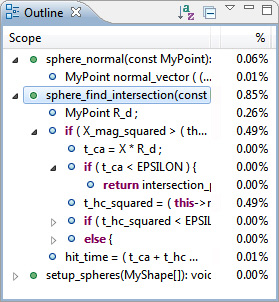
- Чтобы вернуться в средство просмотра исходного кода, нажмите первую кнопку на панели инструментов для перехода к самой горячей строке кода в файле.
Неудивительно, что самая горячая строка содержит вызов функции sqrt.
Рисунок 25. Переход к самой горячей строке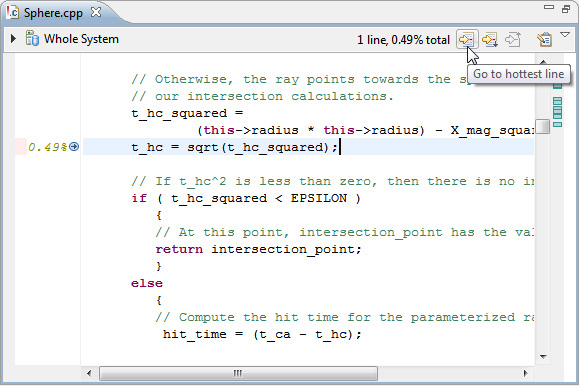
Кажется, возможна простая оптимизация. Значение, возвращаемое функцией sqrt, не используется в первом ветвлении оператора if. Изменение кода таким образом, чтобы sqrt вызывалась только в ветвлении else, может положительно повлиять на производительность, поэтому попробуем сделать это.
Код нельзя редактировать непосредственно в средстве просмотра исходного кода, так как после изменения данные о производительности на уровне строк будут отображаться неправильно.
- Нажмите кнопку Switch to Editor на панели инструментов.
Рисунок 26. Удаленный редактор C/C++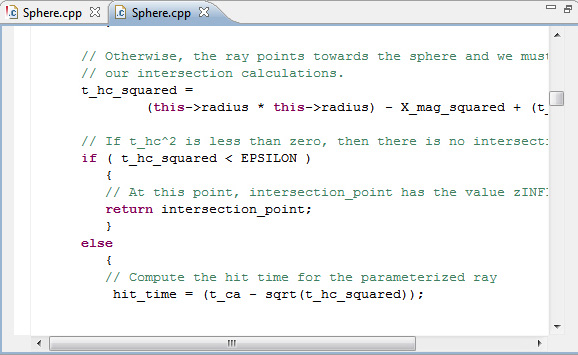
- Измените код так, чтобы sqrt вызывалась только в ветвлении else , а затем перекомпонуйте приложение.
Сравнение изменений исходного кода
- Создайте еще одно действие Hotspot Detection, присвойте ему имя Hotspot Detection 3 и выполните его.
- После завершения сравните его с предыдущим действием, щелкнув на нем правой кнопкой мыши и выбрав Compare with Previous.
Рисунок 27. Выбор Compare with Previous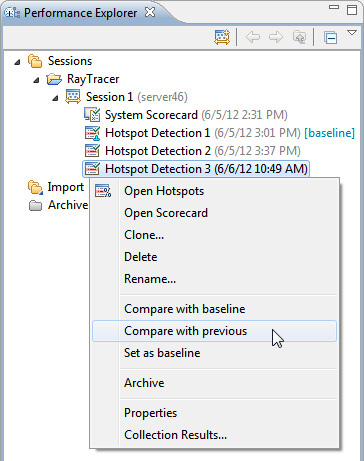
Снимок экрана, приведенный на рисунке 28, показывает, что изменение кода оказало положительное влияние на производительность: теперь приложение выполняется в 2,353 раза быстрее, чем в предыдущем прогоне.
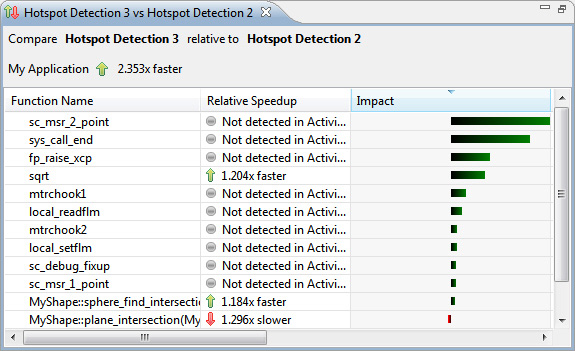
Таблица влияния функций показывает, что sqrt оказала значительное влияние на изменение производительности. Но есть три функции выше sqrt, которые оказывают еще большее влияние. Браузер вызовов (см. рисунок 29) показывает, что все эти функции вызывают sqrt, поэтому, уменьшая число вызовов sqrt, мы также уменьшаем число вызовов этих функций.
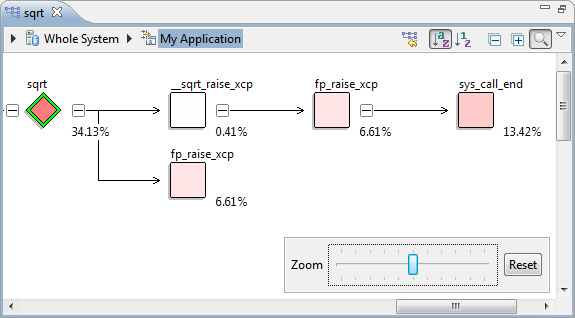
Теперь давайте сравним Hotspot Detection 3 с базой.
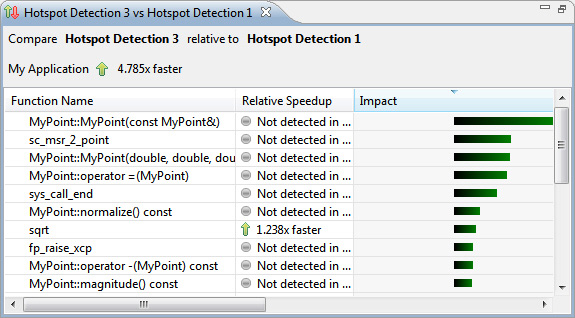
Приложение выполняется в 4,785 раза быстрее, так как комбинируются результаты двух изменений. Неплохо!
Автоматическое отслеживание исходного кода
Мы можем пойти дальше и сравнить производительность на уровне строк для sphere_find_intersection до и после изменения.
- Откройте средство просмотра исходного кода с sphere_find_intersection в Hotspot Detection 2.
Вы увидите исходный код до изменения (вместе с первоначальными данными о производительности).
- Теперь откройте средство просмотра с тем же файлом в Hotspot Detection 3.
- Расположите оба окна просмотра рядом друг с другом, чтобы видеть их одновременно.
Рисунок 31. Сравнение исходного кода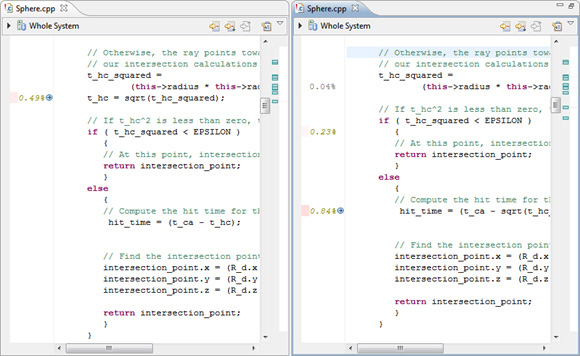
Сейчас у вас может возникнуть вопрос: "Я редактировал этот файл. Как можно увидеть код до его изменения?"
В Performance Advisor есть функция Automatic Source Tracking (автоматическое отслеживание исходного кода). Всякий раз при выполнении прогона сохраняются снимки состояния всех исходных файлов проекта. Вернувшись, чтобы просмотреть данные о производительности из предыдущих прогонов, вы увидите код таким, каким он был на тот момент. Это позволяет детально сравнивать данные о производительности на уровне строк из двух любых прогонов. Эта функция полностью прозрачна и работает автоматически. Он не мешает работе систем управления версиями, которые вы, возможно, уже используете (например, IBM® Rational Team Concert).
- Вернемся немного назад и еще раз сравним Hotspot Detection 1 и Hotspot Detection 2.
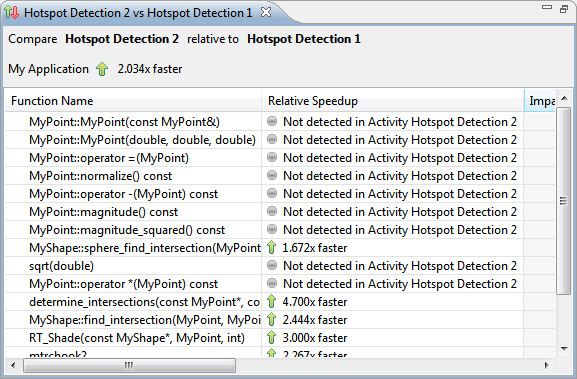
Некоторые функции в верхней части таблицы не имеют информации об ускорении. Они помечены как Not detected in Activity Hotspot Detection 2 (не обнаружены в действии Hotspot Detection 2). Что это означает?
Единственное отличие между двумя прогонами состоит в том, что во втором мы включили оптимизацию компилятора. Одной из основных оптимизаций, выполняемых компилятором, является встраивание функций.
- Откройте средство просмотра исходного кода с файлом RayTrace.cpp в Hotspot Detection 1.
В нем нет ничего особо интересного. Есть несколько данных на уровне строк, но все они говорят нам, что в этом файле нет горячих строк кода.
Рисунок 33. RayTrace.cpp из Hotspot Detection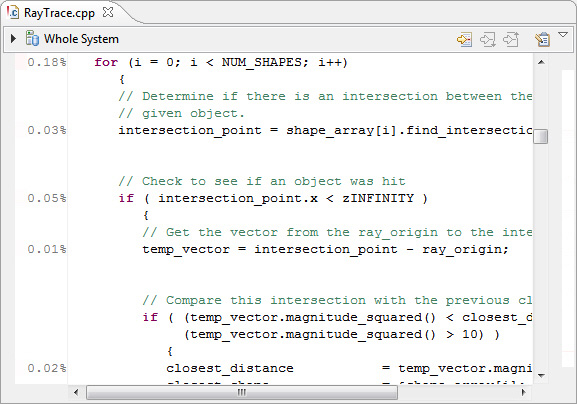
- Теперь откройте тот же файл в Hotspot Detection 2.
Рисунок 34. RayTrace.cpp из Hotspot Detection 2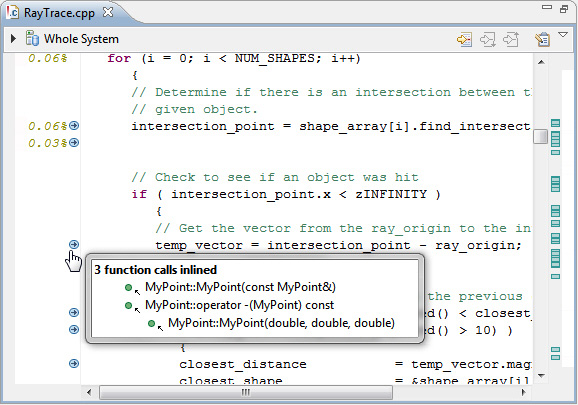
В средстве просмотра для второго прогона появилось много дополнительной информации. Маленькие стрелки слева отмечают строки кода, содержащие вызовы функций, которые были встроены компилятором.
- При наведении курсора на стрелку появится всплывающее окно со встроенными функциями.
При нажатии на значок стрелки развернется исходный код со встроенным непосредственно в него исходным кодом встроенной функции.
Рисунок 35. Исследование встраивания функции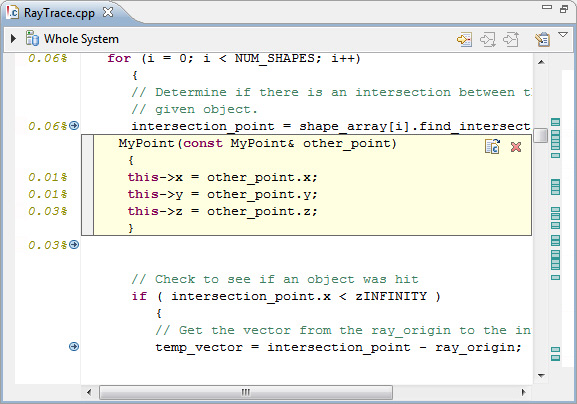
Верхние функции в браузере сравнения не были обнаружены во втором прогоне, потому что компилятор полностью встроил эти функции в узлы их вызова. Это оказало большое положительное влияние на производительность приложения. Поддержка встраивания функций средством просмотра исходного кода позволяет исследовать результат этого влияния с высокой степенью детализации.
Performance Advisor предоставляет богатый набор инструментов для настройки производительности C/C++-приложений на AIX и PowerLinux. В данной статье приведен краткий обзор самых основных функций.
Вот список нескольких более сложных функций, не рассмотренных в статье:
- Всегда доступно представление Recommendations (рекомендации). Рекомендации создаются для каждого действия и являются отличным способом получить совет, где искать возможности для повышения производительности.
- Поддерживаются сложные сценарии настройки. Вы можете компоновать приложения и тестировать их производительность на многих AIX- и PowerLinux-серверах, а затем сравнивать результаты.
- При тестировании производительности вы не обязаны сидеть за компьютером. Performance Advisor позволяет запланировать выполнение прогонов на время вашего отсутствия. Например, можно запланировать ночное выполнение прогона и проанализировать данные на следующий день.
- Performance Advisor поставляется с набором сценариев, которые можно использовать для выполнения прогонов на серверах, где не установлен Rational Developer for Power Systems Software, или на серверах, к которым у вас нет прямого доступа. Просто дайте эти сценарии вашим клиентам для выполнения, а затем импортируйте полученные данные для анализа.
- Члены команды могут совместно использовать данные о производительности посредством импорта и экспорта.
|
Описание |
Имя |
Размер |
Метод загрузки |
|---|---|---|---|
| Пример приложения | RayTracer.zip | 137КБ | HTTP |