Вы наверняка слышали о т.н. "больших данных" (Big Data) и о их влиянии на бизнес-анализ. Возможно, вас интересует, какой информационный капитал ваша организация смогла бы получить в результате регистрации, обработки и применения больших данных, собранных с веб-сайтов, с электронных датчиков или из журналов программного обеспечения - в дополнение к традиционным данными, уже имеющимся в вашей организации. Безусловно, сегодня не ощущается нехватки продуктов с открытым исходным кодом и продуктов сторонних поставщиков, помогающих организациям успешно справляться с различными трудностями при реализации своих проектов в области больших данных. Однако большинство этих продуктов ориентировано на программистов, на администраторов и на технических специалистов, т. е. на лиц с соответствующими навыками.
Так что же делать, если необходимо сделать большие данные доступными для бизнес-аналитиков, для руководителей по направлениям бизнеса и для других специалистов, не являющихся программистами? Рекомендуем обратиться к инструменту BigSheets. Это инструмент в стиле электронной таблицы, поставляемый вместе с продуктом InfoSphere BigInsights. Он позволяет "непрограммистам" итеративно исследовать, обрабатывать и визуализировать данные, хранящиеся в распределенной файловой системе. Типовые приложения, предоставляемые продуктом BigInsights, помогают собирать и импортировать данные из различных источников. В этой статье описывается инструмент BigSheets и два типовых приложения, дополняющие этот инструмент.
BigInsights - это программная платформа, помогающая организациям выявлять и анализировать бизнес-сведения, скрытые в больших объемах весьма разнообразных данных - которые часто игнорируются или отбрасываются, поскольку их обработка с помощью традиционных средств является слишком непрактичной или сложной.
Для того, чтобы оказать организациям эффективное содействие в извлечении пользы из таких данных, в редакцию Enterprise Edition продукта BigInsights включено несколько решений с открытым исходным кодом, в т. ч. Apache Hadoop, и несколько разработанных корпораций IBM технологий, в т. ч. BigSheets. Проект Hadoop и связанные с ним проекты служат эффективной программной инфраструктурой (фреймворком) для приложений с интенсивным использованием данных, которые пользуются распределенными вычислительными средами для достижения высокой масштабируемости.
Технологии IBM обогащают эту инфраструктуру с открытым исходным кодом посредством таких элементов, как аналитическое программное обеспечение, интеграция с корпоративными программными продуктами, расширения платформы и инструменты. Ссылки на дополнительную информацию о продукте BigInsights приведены в разделе Ресурсы. BigSheets - это основанный на браузере аналитический инструмент, первоначально разработанный группой IBM Emerging Technologies. В настоящее время инструмент BigSheets входит в состав продукта BigInsights, что позволяет бизнес-пользователям и непрограммистам исследовать и анализировать данные в распределенных файловых системах. BigSheets представляет пользователям подобный электронной таблице интерфейс, благодаря чему они могут моделировать, фильтровать, сочетать, исследовать и визуализировать данные, собранные из различных источников. Веб-консоль продукта BigInsights содержит вкладку для доступа к инструменту BigSheets. Ссылки на дополнительную информацию об этой веб-консоли приведены в разделе Ресурсы.
На рисунке 1 показан пример коллекции данных в инструменте BigSheets. Хотя эта коллекция выглядит как типичная электронная таблица, она содержит данные из блогов, размещенных на публичных веб-сайтах, и аналитики даже могут нажимать на включенные в эту коллекцию ссылки с целью посещения веб-сайтов, которые опубликовали соответствующий исходный контент.
Рисунок 1. Типовая коллекция BigSheets, основанная на данных из социальных медиа (со ссылками на исходный контент)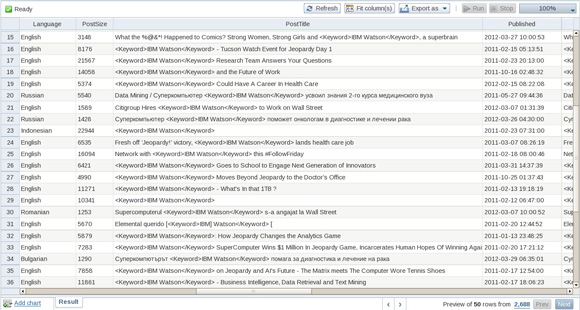
После формирования коллекции BigSheets аналитик может фильтровать или преобразовать ее данные нужным для себя образом. На заднем плане инструмент BigSheets транслирует пользовательские команды, выраженные с помощью графического интерфейса, в скрипты на языке Pig, применяемые к подмножеству первичных данных. Это позволяет аналитику эффективно исследовать различные преобразования итеративным образом. После достижения удовлетворительного результата пользователь может сохранить коллекцию и запустить ее на исполнение, вследствие чего инструмент BigSheets инициирует такие операции, как применение MapReduce-заданий ко всему набору данных, запись результатов в распределенную файловую систему и демонстрация контента новой коллекции. Аналитики могут просматривать данные постранично или обрабатывать весь набор данных нужным для себя образом.
Инструмент BigSheets дополнен несколькими готовыми к применению типовыми приложениями, которые бизнес-пользователи могут запускать из веб-консоли BigInsights с целью сбора данных с веб-сайтов, из систем управления реляционными базами данных, из дистанционных файловых систем и из других источников. В описанной ниже работе мы будем использовать два таких приложения. Однако необходимо понимать, что программисты и администраторы могут использовать и другие технологии BigInsights для сбора, обработки и подготовки данных к последующему анализу в инструменте BigSheets. К числу таких технологий относятся Jaql, Flume, Pig, Hive, MapReduce и другие.
Перед началом работы рассмотрим учебный сценарий применения. Этот сценарий предусматривает анализ данных социальных медиа о системе IBM Watson и последующее объединение этих данных с полученными посредством имитационного моделирования внутренними данными о мероприятиях IBM по расширению медиаохвата, извлеченными из реляционных баз данных. Цель состоит в исследовании наблюдаемости, охвата и слухов относительно известного бренда (услуги, проекта и т. д.), что является распространенной потребностью во многих организациях. В этой статье мы не будем рассматривать весь набор имеющихся аналитических возможностей, поскольку наша цель состоит в демонстрации того, как ключевые аспекты инструмента BigSheets помогают аналитикам быстро приступить к работе с большими данными. Тем не менее, наша работа поможет читателю понять, что можно сделать ценой лишь небольших усилий - а возможно и вызовет удивление относительно популярности системы IBM Watson.
IBM Watson - это исследовательский проект по применению сложных аналитических механизмов для получения ответов на вопросы, представленные на естественном языке. Программное обеспечение Watson "консультируется" с данными, собранными из различных источников, и использует платформу Hadoop для эффективной обработки этих данных с помощью объединенных в кластер серверов IBM Power 750. В 2011 г. система IBM Watson заняла первое место на телевизионной викторине, победив двух ведущих соперников из числа людей. Обратитесь в раздел Ресурсы для получения дополнительной информации о системе IBM Watson и о телевикторине Jeopardy!
Прежде, чем приступить к использованию инструмента BigSheets, необходимо иметь соответствующие данные для анализа. Сначала мы сосредоточимся на сборе данных из социальных медиа.
Сбор данных из социальных медиа
Вне всякого сомнения, сбор и обработка данных, извлеченных из разнообразных социальных веб-сайтов, может оказаться трудным делом, поскольку разные веб-сайты содержат разную информацию и используют разные структуры данных. Кроме того, идентификация и обследование обширного диапазона отдельных веб-сайтов может оказаться весьма длительным мероприятием.
Мы использовали типовое приложение BoardReader, предоставленное продуктом BigInsights, для инициирования поиска по блогам, по новостным потокам, по электронным доскам объявлений и по видео-сайтам. На рисунке 2 показаны входные параметры, введенные нами в приложение BigInsights BoardReader, которое мы запустили со страницы Applications веб-консоли BigInsights. Ссылки на необходимые сведения о веб-консоли и о ее каталоге типовых приложений содержатся в разделе Ресурсы.
Рисунок 2. Вызов приложения BoardReader из веб-консоли инструмента BigInsights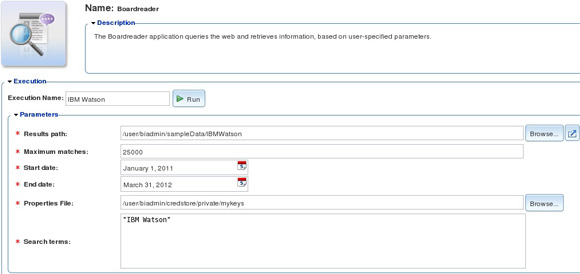
Кратко рассмотрим входные параметры, показанные на рисунке 2. Параметр Results Path специфицирует каталог в распределенной файловой системе Hadoop (HDFS), предназначенный для вывода результатов работы приложения. Последующие параметры показывают, что мы ограничили максимум совпадений в возвращаемых результатах числом 25000, а период поиска интервалом с 1 января 2011 г. по 31 марта 2012 г.Параметр Properties File ссылается на хранилище полномочий BigInsights, в которое мы поместили свой лицензионный ключ BoardReader (каждый заказчик должен обратиться в компанию BoardReader для получения действительного лицензионного ключа). И, наконец, "IBM Watson" - это предмет нашего поиска.
После выполнения приложения распределенная файловая система содержит четыре новых файла в выходном каталоге, как показано в нижней части рисунка 3.
Рисунок 3. Результаты работы приложения, сохраненные в инструменте BigInsights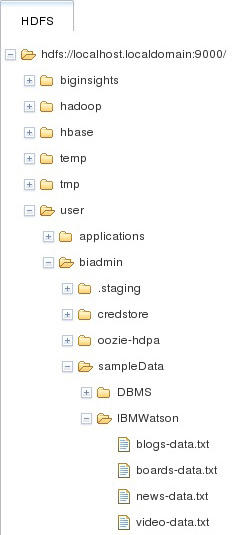
С целью упрощения материал мы будем использовать в этой статье только новостные данные и данные блогов. Если желаете следовать нашему учебному сценарию, выполните приложение BoardReader с указанными нами параметрами или загрузите учебные данные. Обратите внимание, что материалы для загрузки содержат лишь подмножество информации, которую приложение BoardReader собирает из новостных потоков и блогов. В частности, мы удалили из учебных файлов полнотекстовый контент/HTML-контент постов и новостных сообщений, а так же некоторые метаданные. Такие данные не являются необходимыми для рассматриваемых в этой статье аналитических задач, а мы хотели сохранить контроль над размерами каждого файла.
Каждый файл, возвращенный приложением BoardReader, представлен в формате JSON. Небольшую часть этих данных можно отобразить в виде текста на странице Files веб-консоли BigInsights, однако результаты будут трудны для прочтения. Через мгновение вы увидите, как преобразовать эти данные в "листы" (sheet) или в "коллекции" (collection) данных BigSheets, исследование которых осуществлять гораздо легче. Необходимо отметить, что каждый файл содержит несколько иную структуру JSON - это необходимо учитывать при моделировании коллекции, которая объединяет наборы данных из блогов и из новостей. В проектах в области "больших данных" широкое распространение получила подготовка или преобразование структур данных с целью упрощения последующего анализа.
Сбор данных из реляционной системы управления базами данных
После исследования определенных аспектов этих данных из социальных медиа мы объединяем их с данными, извлеченными из СУБД. Многие проекты в области больших данных предусматривают анализ новых источников информации (таких как данные социальных медиа) в контексте существующей корпоративной информации, включая данные, хранящиеся в реляционных СУБД. BigInsights обеспечивает подключение к различным реляционным СУБД и хранилищам данных, включая Netezza, DB2®, Informix®, Oracle, Teradata и др.
Для нашего учебного сценария мы заполнили таблицу DB2 имитированными данными о мероприятиях IBM по расширению медиаохвата. Соединение этих реляционных данных с информацией, извлеченной из социальных веб-сайтов, могло предоставить нам определенные индикаторы для оценки эффективности и охвата различных усилий по повышению известности. Хотя инструмент BigInsights обеспечивает динамический доступ к реляционным СУБД посредством запросов через интерфейс командной строки, мы воспользовались типовым приложением Data Import веб-консоли BigInsights для извлечения интересующих нас данных.
На рисунке 4 показаны входные параметры, которые мы предоставили этому приложению. Файл свойств mykeys в хранилище учетных данных BigInsights содержит необходимые входные параметры JDBC для установления соединения с базой данных, в т. ч. JDBC URL (напр., jdbc:db2://myserver.ibm.com:50000/sample), класс JDBC-драйвера (напр., com.ibm.db2.jcc.DB2Driver), а также идентификатор/пароль пользователя. Остальные входные параметры: простой SQL-оператор SELECT для извлечения интересующих нас данных из целевой базы данных, выходной формат (CSV-файл) и каталог для вывода результатов работы BigInsights.
Рисунок 4. Вызов приложения Data Import из веб-консоли инструмента BigInsights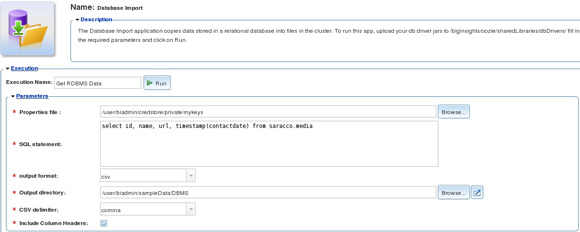
Обратите внимание, что до исполнения этого приложения мы загрузили соответствующие файлы драйвера СУБД в требуемый каталог BigInsights в распределенной файловой системе (/biginsights/oozie/sharedLibraries/dbDrivers). Поскольку в качестве системы-источника использовалась СУБД DB2 Express-C, мы загрузили файлы db2jcc4.jar и db2jcc_license_cu.jar.
Если вы хотите воспроизвести наш учебный сценарий с задействованием СУБД, загрузите бесплатный экземпляр DB2 Express-C (соответствующая ссылка приведена в разделе Ресурсы),создайте и заполните учебную таблицу, а затем исполните приложение BigInsights Data Import, как описано в этой статье. В качестве альтернативного варианта, вы можете загрузить CSV-файл, извлеченный из DB2, а затем включить этот файл непосредственно в продукт BigInsights.
Шаг 2. Создание коллекции BigSheets
Чтобы приступить к анализу своих данных с помощью BigSheets, вам необходимо создать коллекции - структуры в стиле электронных таблиц - которые будут моделировать нужные файлы в вашей распределенной файловой системе. В нашем сценарии эти файлы включают JSON-данные блогов, собранные приложением IBM BoardReader, новостные JSON-данные, собранные приложением BoardReader IBM, и CSV-данные, извлеченные из DB2 приложением IBM Data Import.
Рассмотрим базовую процедуру пошагового создания одной такой коллекции.
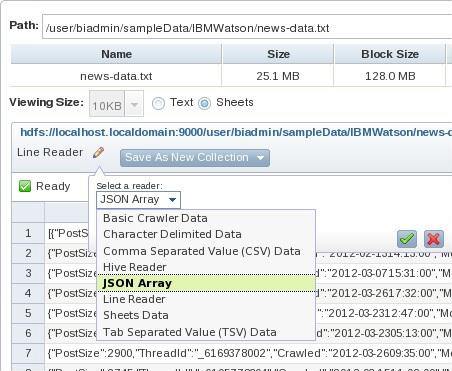
- На странице Files веб-консоли с помощью навигатора файловой системы выберите файл news-data.txt (см. рисунок 3).
- В правой стороне панели выберите кнопку Sheets для изменения формата отображения с Text на Sheets. Как показано на рисунке 5, эта кнопка расположена справа от спецификации Viewing Size.
- Задайте для своего файла соответствующий механизм чтения (reader) или преобразователь форматов данных. Как показано на рисунке 5, инструмент BigSheets предоставляет несколько разных встроенных механизмов чтения для работы с распространенными форматами данных. Для этого учебного файла хорошо подходит механизм JSON Array.
- Сохраните свою новую коллекцию под именем Watson_sorted.
Рисунок 5. Создание коллекции с соответствующим механизмом чтения (reader)
С помощь вышеописанной процедуры создайте для файла blogs-data.txt отдельную коллекцию и присвойте ей имя Watson_blogs. И, наконец, создайте третью коллекцию для CSV-файла с данными из СУБД и в качестве механизма чтения укажите для нее BigSheets Comma-Separated Values (CSV) Data. Присвойте этой коллекции имя Media_Contacts.
Следует отметить, что коллекцию можно создать на основе контента всего каталога, а не только на основе единственного файла. Для этого с помощью навигатора файловой системы укажите целевой каталог, нажмите на кнопку Sheets в правой панели и выберите соответствующий механизм чтения для применения ко всем файлам в этом каталоге. Тем не менее, описываемый в этой статье сценарий использует три раздельных коллекций, как было указано выше.
Довольно часто перед исследованием различных аспектов самих данных аналитики желают настроить формат, контент и структуру своих коллекций. Инструмент BigSheets предоставляет несколько макросов и функций для поддержки подобной подготовки данных. В этом разделе мы исследуем две таких опции: устранение ненужных данных посредством удаления столбцов и консолидация данных из двух коллекций посредством операции union.
Приложение BigInsights BoardReader возвращает данные новостей и блогов, которые заполняют различные столбцы в каждой коллекции BigSheets. Для аналитической работы, которую мы рассматриваем в этой статье, нам нужно лишь подмножество этих столбцов, поэтому важным начальным этапом является создание новых коллекций, которые содержат лишь необходимые нам столбцы.
- На главной странице BigSheets откройте коллекцию Watson_news, которую вы создали из файла news-data.txt.
- Нажмите Build New Collection.
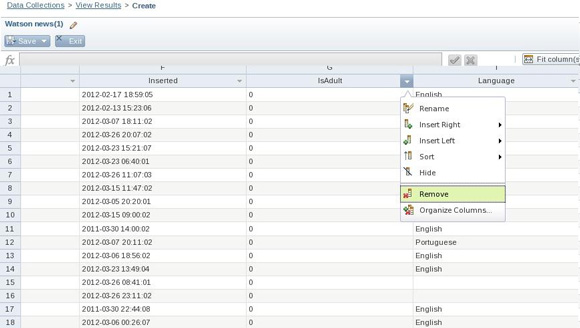
- Перейдите к столбцу IsAdult, как показано на рисунке 6. Нажмите на направленную вниз стрелку в заголовке столбца, а затем на опцию Remove (Удалить столбец). Сделайте это для всех столбцов в коллекции, кроме следующих столбцов: Country, FeedInfo, Language, Published, SubjectHtml, Tags, Type, Url.
- Сохраните коллекцию под именем Watson_news_revised и выйдите из нее. После появления подсказки запустите коллекцию. Обратите внимание, что строка текущего состояния справа от кнопки Run позволяет контролировать протекание работы. (В процессе исполнения вашей коллекции инструмент BigSheets на заднем плане исполняет Pig-скрипты, которые инициируют задания MapReduce. Нетрудно догадаться, что производительность исполнения зависит от объема данных, связанных с вашей коллекцией, и от доступных системных ресурсов)
Рисунок 6. Удаление столбцов из коллекции
Поскольку наша конечная цель состоит в консолидации данных из блогов и новостей в одну коллекцию для последующего анализа, примените аналогичный подход для создания новой коллекции для данных из блогов, которая будет содержать только следующие столбцы: Country, FeedInfo, Language, Published, SubjectHtml, Tags, Type, Url. Присвойте новой коллекции блогов имя Watson_blogs_revised.
Объединение двух коллекций в одну с помощью операции union
Теперь объедините недавно отредактированные коллекции (Watson_news_revised и Watson_blogs_revised) в одну коллекцию, на основе которой будет исследоваться охват системы IBM Watson. Для этого воспользуйтесь оператором инструмента BigSheets под названием union. Обратите внимание, что этот оператор требует, чтобы все листы имели одинаковую структуру. После выполнения инструкций из предшествующего раздела вы обладаете двумя такими коллекциями для объединения, каждая из которых имеет столбцы Country, FeedInfo, Language, Published, SubjectHtml, Tags, Type, Url (именно в таком порядке).
Для объединения коллекций выполните следующие действия.
- Откройте коллекцию Watson_news_revised и нажмите на Build New Collection.
- Нажмите Add sheets > Load для добавления контента другой коллекции к своей действующей модели (см. рисунок 7). При появлении подсказки выберите Watson_blogs_revised collection, присвойте своему листу имя Blogs, а затем нажмите на зеленую контрольную отметку ("галочку") для применения этой операции.
Рисунок 7. Подготовка к загрузке коллекции в новый лист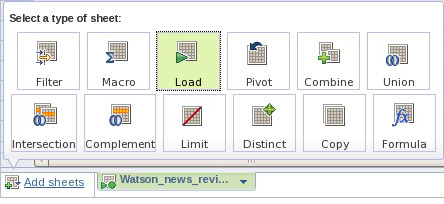
- Теперь ваш экран должен содержать новый лист. Обратите внимание, что в левом нижнем углу вашей коллекции имеется новая вкладка для этого листа (см. рисунок 8).
Рисунок 8. Просмотр нового листа
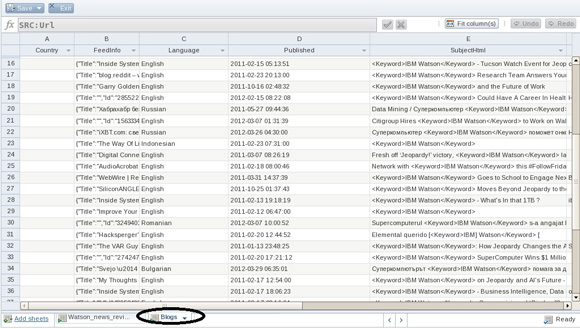
- Нажмите Add sheets > Union с целью создания другого листа для объединения данных из блогов с данными новостей. После появления подсказки нажмите на ниспадающее меню и выберите Watson_news_revised в качестве листа, который вы будете объединять с данными из блогов, только что загруженных вами (см. рисунок 9). Нажмите на знак (+) рядом с полем, а затем на зеленую галочку в нижней части окна для запуска операции union.
Рисунок 9. Указание листов для операции Union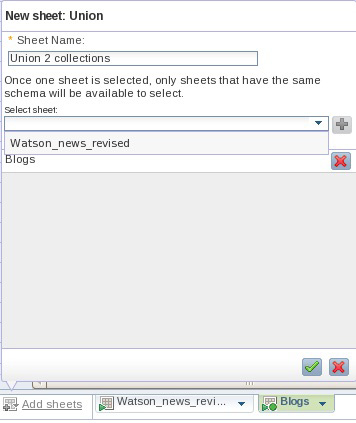
- Сохраните коллекцию под именем Watson_news_blogs и выйдите из нее. Запустите коллекцию на исполнение.
Затем проанализируйте данные в этой новой коллекции.
Шаг 4. Исследование коллекции с целью рассмотрения глобального охвата IBM Watson
Одна из областей, которую мы хотели бы исследовать - глобальный интерес к системе IBM Watson и ее охват в медийной среде. Сначала у вас может возникнуть искушение отсортировать коллекцию Watson_news_blogs по значениям столбца Country (страны). Однако, проинспектировав данные, вы заметите, что многие строки содержат пустые позиции для этого столбца. Это типичная ситуация для данных, собранных с социальных веб-сайтов и из других источников. Во многих случаях нужные данные отсутствуют, что вынуждает аналитиков прибегать к другим средствам для получения сведений об интересующих их областях.
Для большинства постов в блогах и новостей указывается исходный язык, поэтому будем мы сортировать свои записи по языкам и по типам. Это поможет нам исследовать глобальный охват системы IBM Watson в постах блогов и в новостях:
- Откройте коллекцию Watson_news_blogs и нажмите на Build New Collection.
- В разделе Language раскройте ниспадающее меню и нажмите Sort > Advanced. После появления подсказки выберите столбцы Language и Type из меню Add Columns to Sort. В разделе Language измените значение сортировки на Descending и убедитесь в том, что Language является первичным столбцом сортировки (см. рисунок 10). Нажмите на зеленую стрелку для применения операции к подмножеству своих данных.
Рисунок 10. Подготовка коллекции к сортировке по двум столбцам (столбец Language является первичным)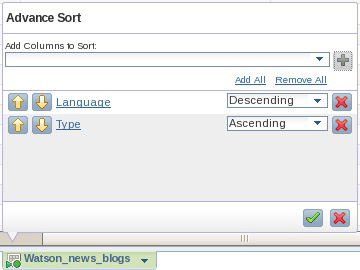
- Проинспектируйте 50 показанных записей и обратите внимание на множество упомянутых языков.
- Сохраните коллекцию под именем Watson_sorted и выйдите из нее. После этого исполните эту коллекцию с полным набором данных. При рассмотрении возвращенных результатов вы увидите больше записей для определенных языков, таких как вьетнамский, чем на предыдущем шаге.
Графическое представление результатов
Вы можете просматривать свою коллекцию постранично для исследования охвата тематики IBM Watson на различных языках, однако самый простой способ для визуализации международного интереса к этой тематике - представить результаты в графическом виде. Это обеспечит "широкий обзор", что, в свою очередь, будет способствовать последующим исследовательским и аналитическим мероприятиям. Инструмент BigSheets поддерживает различные типы диаграмм, в т. ч. гистограммы, секторные диаграммы, облака тегов и т. д. Мы будем пользоваться простой секторной диаграммой.
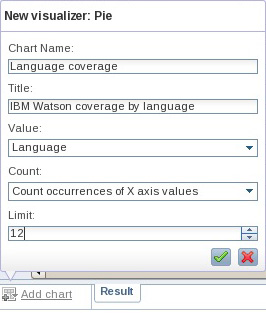
- Откройте коллекцию Watson_sorted и нажмите Add chart > Chart > Pie. (Вкладка Add chart находится в левом нижнем углу коллекции около вкладки Result)
- После появления подсказки введите нужные вам значения параметров Chart Name (название диаграммы) и Title (заголовок). Выберите столбец Language в качестве значения, которое вы хотите визуализировать, а в поле Count оставьте его значение по умолчанию. Установите значение параметра Limit равным 12, вследствие чего секторная диаграмма отразит данные о 12 наиболее часто встречающихся языках в этой коллекции (см. рисунок 11).
Рисунок 11. Входные параметры для создания секторной диаграммы
- Нажмите на кнопку с зеленой галочкой и после появления подсказки запустите диаграмму.
Как и следовало ожидать, результирующая секторная диаграмма демонстрирует, что почти 79% собранных нами данных из новостей и блогов было опубликовано на английском языке. Однако сможете ли вы догадаться, как следующий по популярности язык для тематики IBM Watson? Секторная диаграмма на рисунке 12 позывает, что это русский язык. Перемещая курсор мыши над любой частью секторной диаграммы, показанной в инструменте BigSheets, вы сможете определить его опорное значение (в данном случае, это значение столбца Language).
Рисунок 12. Оценка глобального интереса к тематике IBM Watson по разным языкам, основанная на доступных данных из новостей и из блогов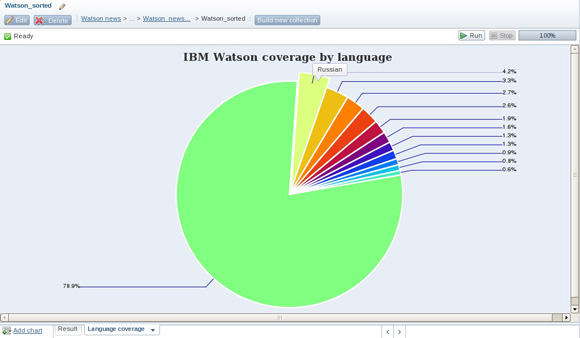
При перемещении курсора по пятому и шестому по величине секторам диаграммы на рисунке 12 (2,6% и 1,95%, соответственно), вы обнаружите, что они соответствуют различным диалектам китайского языка. Этот факт иллюстрирует другую распространенную ситуацию, связанную со сбором данных из различных источников, таких как социальные веб-сайты - значения данных, которые вы хотели бы рассматривать как идентичные, часто представляются несколько по-иному.
Рассмотрим использование инструмента BigSheets для изменения этих значений таким образом, чтобы все вариации китайского языка были заменены единственным значением "Chinese" (китайский язык).
- Откройте коллекцию Watson_sorted и нажмите на кнопку Edit (расположена под именем коллекции в левом верхнем углу).
- Перейдите к столбцу Language и нажмите на направленную вниз стрелку в заголовке столбца с целью вывода ниспадающего меню. Выберите Insert Right > New Column с целью создания нового столбца для размещения очищенных данных. После появления подсказки присвойте новому столбцу имя LanguageRevised и нажмите на зеленую галочку для завершения операции.
- Разместите курсор на столбце LanguageRevised и введите в верхней части листа в поле fx (formula specification - спецификация формулы) следующую формулу
IF(SEARCH('Chin*', #Language) > 0, 'Chinese', #Language)(см. рисунок 13).
Рисунок 13. Задание формулы для извлечения значения столбца
Эта формула заставляет инструмент BigSheets искать в столбце Language листа такие значения, которые начинаются с символов "Chin". Если этот инструмент находит такие значения, он записывает значение "Chinese" (китайский язык) в столбец LanguageRevised; в противном случае он копирует в столбец LanguageRevised значение из столбца Language. Информационный центр по продукту BigInsights (см. раздел Ресурсы) содержит подробные сведения по заданию формул BigSheets. Нажмите на зеленую галочку для применения формулы. - Сохраните результаты своей работы и выйдите из нее. При появлении предупреждение о рассинхронизации данных запустите пересмотренное определение этой коллекции.
- Создайте новую диаграмму с 12 секторами на основе значений в столбце LanguageRevised и сравните результаты с созданной ранее секторной диаграммой (основанной на необработанных данных в столбце Language). Обратите внимание, что согласно новой секторной диаграмме, вторым по распространенности языком теперь является Chinese (китайский язык), за которым следуют Russian (русский язык), Spanish (испанский язык) и German (немецкий язык).
Углубление анализа: Фильтрация результатов и извлечение данных из URL-адреса
Просмотренные вами данные способны породить множество разнообразных вопросов, которые нуждаются в дальнейшем исследовании. Это весьма характерно для анализа больших данных, который по своей природе часто является итеративным и исследовательским. Теперь мы несколько углубим наш анализ охвата тематики IBM Watson в англоязычных новостях и в постах блогов, чтобы точнее оценить охват в Великобритании.
В соответствии с вводным характером нашей статьи мы применяем простой подход к исследованию этой темы. В частности, мы создаем из коллекции Watson_sorted новую коллекцию, хранящую англоязычные записи, у которых доменное имя в URL-адресе заканчивается на ".uk" или у которых параметр Country имеет значение "GB" (Великобритания). С этой целью нам придется использовать оператор BigSheets Filter, а так же макрос для извлечения данных хоста из полной URL-строки.
- Откройте коллекцию Watson_sorted и сформируйте новую коллекцию.
- Добавьте лист, применяющий операцию Filter.
- После появления подсказки выберите Match all и с помощью трех ниспадающих меню задайте опцию Language is English (см. рисунок 14. Затем нажмите на зеленую галочку с целью применения операции к подмножеству данных коллекции.
Рисунок 14. Фильтрация на основе значений одного столбца
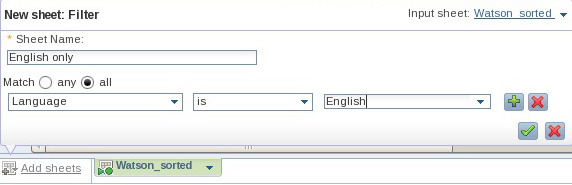
- Сохраните свою текущую работу (присвойте листу имя Watson_sorted_English_UK), но не осуществляйте выход, поскольку вы продолжите очищать эту коллекцию.
- Добавьте другой лист, который осуществляет вызов макроса. После появления подсказки нажмите Categories > url > URLHOST. Выберите столбец URL своей коллекции в качестве целевого столбца, содержащего значения URL-адресов. (Макрос прочитает значения в этом столбце и извлечет информацию об имени хоста в URL-адресе из более длинной строки. В качестве примера предположим, что полная URL-строка имеет вид "http://www.georgeemsden.co.uk/2011/09/how-long-before-your-laptop-finds-a-cure-for-cancer/". В этом случае макрос возвратит значение "www.georgeemsden.co.uk" в качестве имени хоста в URL-адресе.)
- Нажмите на закладку Carry Over в нижней части панели (см. рисунок 15). Это важно, поскольку позволяет вам указать, какие столбцы существующей коллекции вы хотите сохранить (или перенести).
Рисунок 15. Работа с макросом URLHOST
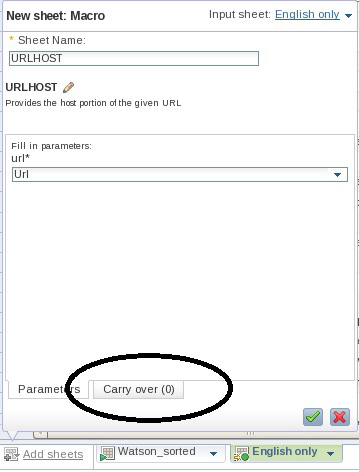
- Нажмите Add all для сохранения всех существующих столбцов и применения операции. Сохраните свою работу, но не выходите из инструмента.
- Добавьте другой лист для дальнейшей фильтрации данных. После появления подсказки выберите любой из следующих двух критериев совпадения: "URLHOST ends with uk" и "Country is GB," (см. рисунок 16). (Учитывая разреженную природу данных в этой коллекции, для обнаружения находящихся в Великобритании веб-сайтов нам нужно обеспечить соответствие любому из этих условий) Примените операцию.
Рисунок 16. Фильтрация данных на основе значений двух столбцов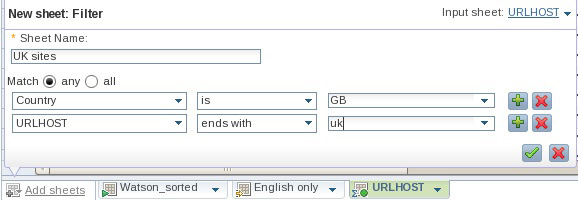
- Сохраните коллекцию и выйдите из нее, а затем запустите ее на исполнение.
Сортировка результатов в столбце URLHOST или вывод диаграммы позволит вам быстро установить, какие британские веб-сайты в результирующей коллекции чаще всего затрагивают тематику IBM Watson. Например, на рисунке 17 показано облако тегов, которое мы создали для первой десятки таких веб-сайтов. Как и в случае любого другого облака тегов BigSheets, более крупный шрифт указывает на более высокую частоту употребления значения данных, а прокрутка по значениям данных отображает количество их употреблений в соответствующей коллекции.
Рисунок 17. Десятка ведущих веб-сайтов Великобритании по охвату тематики IBM Watson
Шаг 5. Дальнейшие исследования, сочетающие данные социальных медиа и структурированные данные
Перед завершением этого введения в инструмент BigSheets исследуем несколько других интересных областей, затрагивающих наш учебный набор данных.
- Количество отдельных веб-сайтов, охватывающих тематику IBM Watson, и 12 международных веб-сайтов, охватывающих тематику IBM Watson. Для исследования этой области мы применим дополнительные макросы и диаграмму иного типа.
- Охват веб-сайтов, которые были объектом мероприятий IBM по расширению медиаохвата. Для исследования этой области мы соединим данные, извлеченным из реляционной базы данных, с данными социальных медиа в инструменте BigInsights (для этой статьи мы создали фиктивные (имитированные) данные о деятельности IBM по связям с общественностью).
И, наконец, мы рассмотрим, как экспортировать контент коллекции в распространенный формат данных, который может с легкость использоваться сторонними приложениями.
Выявление широты охвата и двенадцати ведущих веб-сайтов
Один из аспектов оценки эффективности кампании по расширению медиаохвата - измерение широты охвата. В этом примере вы будете использовать инструмент BigSheets для выявления отдельных новостей и веб-сайтов для блогов, которые упоминают тематику IBM Watson.
- Откройте коллекцию Watson_news_blogs и создайте новую коллекцию.
- Добавьте лист с именем Url Hosts, который использует макрос URLHOST для извлечения имени хоста из полной URL-строки, предоставленной в столбце URL. Перенесите только столбец URL (в случае необходимости обратитесь к шагу 4, который содержит детальные инструкции по макросу URLHOST).
- Добавьте другой лист посредством применения оператора Distinct к листу, который вы только что создали.
- Сохраните эту коллекцию и выйдите из нее (запуск коллекции на исполнение необходимо осуществлять после появления соответствующей подсказки). Обратите внимание на наличие немногим более 2800 отдельных веб-сайтов, как показано в правом нижнем углу рисунка 18. Откроете коллекцию Watson_news_blogs и увидите, что в общей сложности имеется более 7200 записей.
Рисунок 18. Установление количества отдельных веб-сайтов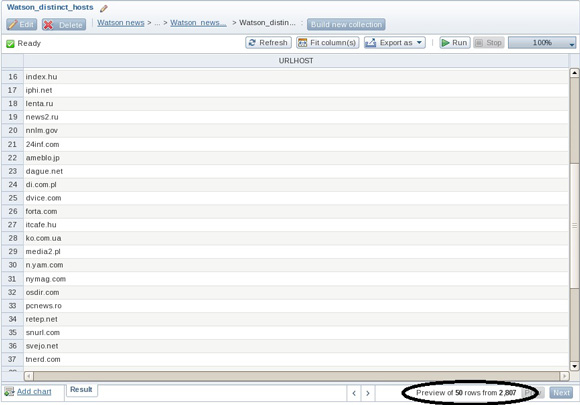
Теперь, когда вы знаете, что многие веб-сайты содержат по несколько постов, вы можете выявить 12 ведущих веб-сайтов (содержащих большую часть постов по тематике IBM Watson), а затем визуализировать полученные результаты в виде гистограммы. Это несложно сделать, а результаты могут оказаться удивительными.
- В случае необходимости откройте коллекцию, которую вы только что создали.
- Нажмите Add chart > Chart > Column. Введите предпочтительные значения для имени и названия диаграммы. Сохраните значения по умолчанию для осей X и Y. Присвойте параметру Limit значение 12. Примените эти настройки и запустите диаграмму. Результаты показаны на рисунке 19. Как видим, в первую тройку не вошел ни сайт корпорации IBM, ни какой-либо веб-сайт, спонсируемый IBM.
Рисунок 19. Графическое представление 12 ведущих веб-сайтов по охвату тематики IBM Watson (по количеству постов)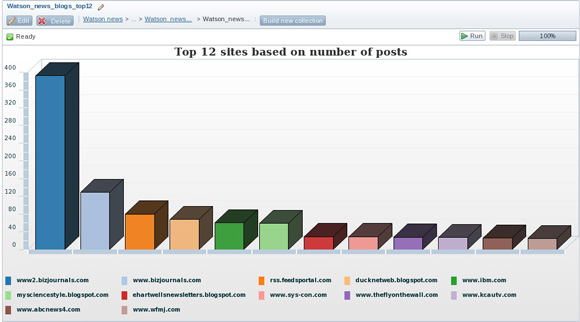
Проинспектируйте URL-адреса двух ведущих веб-сайтов. Вы увидите, что они представляют собой вариации адреса bizjournals.com. Это позволяет вам вернуться к коллекции и преобразовать или очистить эти данные. Как указывалось выше, во многих случаях анализ больших данных требует итеративных опереций по исследованию, обработке и очистке данных.
И, наконец, после выявления12 ведущих веб-сайтов вас может заинтересовать такой аспект, как количество постов на каждом из этих сайтов. Реализуем простой способ получения такой информации.
- При необходимости откройте коллекцию и отредактируйте ее.
- Нажмите Add Sheet > Pivot. Присвойте листу имя Pivot, укажите лист URL-адресов в качестве входного листа и выберите URLHOST в качестве столбца Pivot (см. рисунок 20).
Рисунок 20. Создание листа Pivot, который будет содержать агрегированные данные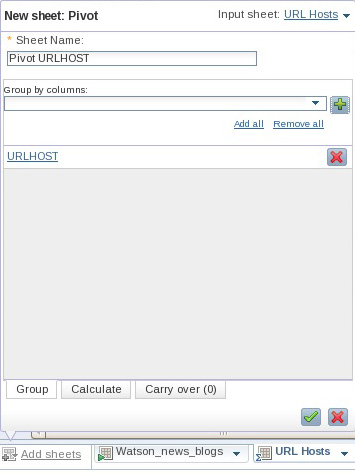
- Нажмите на вкладку Calculate в нижней части меню. Задайте имя для нового столбца, который будет содержать агрегированные данные (например, CountURLHOST), и нажмите на знак (+). В качестве значения нового столбца выберите COUNT и укажите столбец URLHOST в качестве целевого столбца для операции Count (см. рисунок 21.)
Рисунок 21. Задание начальных параметров вычислений для нового листа Pivot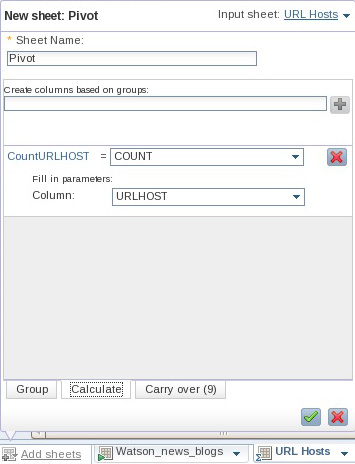
- Оставайтесь на вкладке Calculate и создайте другой столбец с именем MergeURL, который будет содержать объединенный список полных URL-адресов, ассоциированных со значениями URLHOST в первом столбце вашей коллекции. Такой список может пригодиться нам позднее. Для генерации этого списка и включения его в качестве нового столбца в результирующую коллекцию, нажмите на знак (+), выберите MERGE в качестве значения нового столбца, Url в качестве целевого столбца и символ (,) в качестве разделителя полей. Убедитесь в том, что ваша спецификация выглядит как на рисунке 22 и примените операцию.
Рисунок 22. Добавление второго вычисления к листу Pivot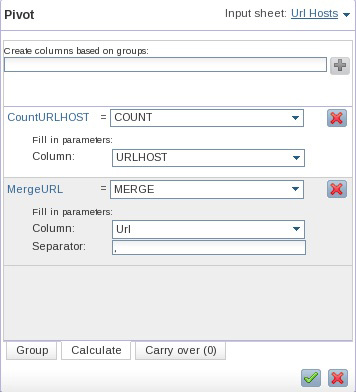
- При необходимости отсортируйте значения в объединенном столбце (CountURLHOST) в порядке убывания.
- Сохраните коллекцию и выйдите из нее, а затем запустите ее на исполнение. Просмотрите результаты, подмножество которых показано на рисунке 23.
Рисунок 23. Агрегированные данные, содержащиеся в листе Pivot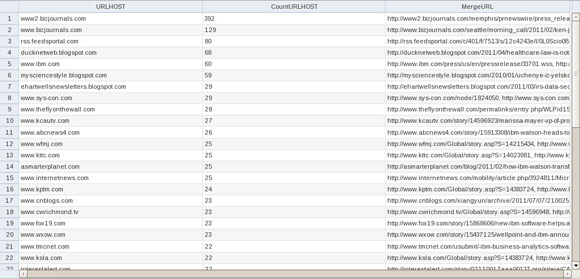
Корреляция внутренних мероприятий по расширению медиаохвата с внешним охватом
Вплоть до настоящего момента наша работа с инструментом BigSheets затрагивала только данные, собранные с внешних веб-сайтов. Однако многие проекты в области больших нуждаются в объединение внешних данных с внутренними корпоративными данными, такими как данные в реляционных СУБД. В этом разделе вы будете использовать инструмент BigSheets для объединения двух коллекций: одна из которых предназначена для моделирования данных социальных медиа, а другая - для моделирования реляционных данных. Объединив эти две коллекции, вы сможете исследовать, как корпоративные мероприятия по расширению медиаохвата коррелируют с охватом со стороны веб-сайтов других организаций. Обратите внимание, что учебные реляционные данные, которые мы предоставляем с этой статьей в виде CSV-файла, содержат имитируемую информацию о медийных контактах корпорации IBM. Для объединения коллекций и последующей визуализации результатов выполните следующие действия.
- Откройте коллекцию Watson_news_blogs и создайте новую коллекцию.
- С помощью макроса URLHOST добавьте новый лист для извлечения информации об именах хостов. Перенесите все существующие столбцы и присвойте этому листу имя URLHOST.
- Добавьте другой лист, который загружает коллекцию Media_Contacts, уже созданную вами на основе импортированных данных реляционной СУБД (вы создали эту коллекцию на шаге 2.) Присвойте этому новому листу имя Contacts.
- Переименуйте заключительный столбец листа Contacts - присвойте ему имя LastContact (Этот столбец был создан посредством применения функции
SQL TIMESTAMP()к исходным данным реляционной СУБД. Его значения показывают, когда имел место последний контакт с соответствующим целевым медиапровайдером.) - Добавьте другой лист, который объединяет листы URLHOST и Contacts на основе значений столбцов URLHOST и URL, соответственно (см. рисунок 24). Присвойте новому листу имя Combine.
Рисунок 24. Объединение данных с двух листов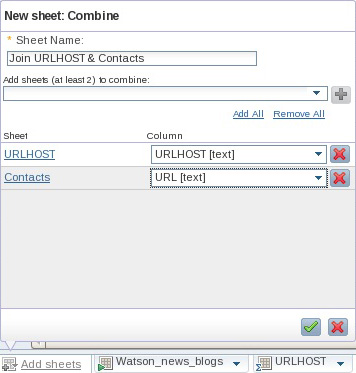
- Для упрощения инспектирования результатов удалите столбцы ID и URL, которые первоначально присутствовали в листе Media_Contacts. Реорганизуйте оставшиеся столбцы таким образом, чтобы они демонстрировались в интуитивно понятном порядке: URLHOST, NAME, Published, LastContact, FeedInfo, Country, Language, SubjectHtml, Tags, Type, Url.
- Сохраните коллекцию и запустите ее на исполнение. Просмотрите результаты или представьте их в графическом виде (при необходимости) для оценки количества постов на каждом целевом медиасайте (на рисунке 25 показана горизонтальная гистограмма, обобщающая эти данные).
Рисунок 25. Оценка количества постов по тематике IBM Watson на различных веб-сайтах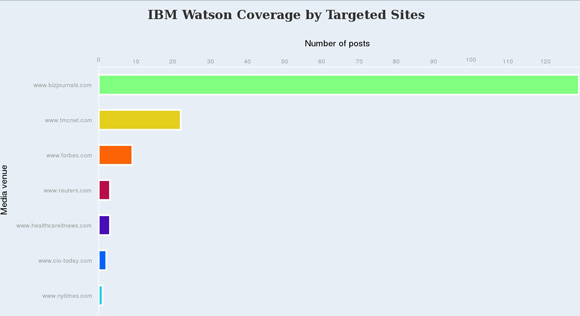
В некоторых случаях результаты вашего анализа с помощью инструмента BigSheets могут оказаться полезными для других приложений или для коллег, не обладающих полномочиями для непосредственной работы с BigInsights. К счастью, вы можете с легкостью экспортировать одну или несколько своих коллекций в распространенные форматы данных. Просто откройте целевую коллекцию, задействуйте функцию Export As (слева от кнопки Run) и выберите формат JSON, CSV, ATOM, RSS или HTML в качестве целевого формата. Результаты будут показаны в вашем браузере, а вы сможете сохранить выходные результаты в своей локальной файловой системе.
Краткий экскурс за пределы базового уровня
Итак, вы получили определенное представление о возможностях инструмента BigSheets. Вы увидели, как встроенные макросы, функции и операторы позволяют исследовать, преобразовывать и анализировать различные формы больших данных без написания кода на языке Java™ или на языке подготовки скриптов.
Мы стремились упростить свой сценарий, чтобы вы смогли быстрее освоить базовые возможности BigSheets, однако эта технология - а также дополнительные технологии продукта BigInsights - предлагают гораздо больше, чем мы способны охватить во вводной статье. Например, многие проекты по анализу социальных медиа должны углубляться в контент постов, чтобы оценивать мнения, категоризировать контент, устранять ошибочные результаты и т. д. Такие проекты требуют извлечения контекста из текстовых данных. Эта возможность предлагается другим компонентом BigInsights, который будет предметом рассмотрения в будущей статье. К счастью, подобные возможности по анализу текста могут сочетаться с инструментом BigSheets с помощью специальных подключаемых модулей.
Кроме того, некоторые аналитические задачи могут потребовать применения языка запросов, позволяющего с легкостью выражать различные условия, обрабатывать и преобразовывать вложенные структуры данных, применять сложные условные логические конструкции и т.д. И, действительно, продукт BigInsights поддерживает Jaql - язык запросов на базе JSON, который программисты часто используют для чтения данных и для их подготовки к последующему анализу в BigSheets. Язык Jaql будет рассматриваться в будущей статье.
В статье было показано, как инструмент BigInsights позволяет бизнес-аналитикам работать с "большими данными" без написания программного кода или скриптов. В частности, статья рассмотрела два типовых приложения для сбора данных из социальных медиа и из реляционных СУБД, а также объяснила, как аналитики смогут моделировать, обрабатывать, анализировать, сочетать и визуализировать эти данные с помощью BigSheets - инструмента в стиле электронной таблицы, ориентированного на бизнес-аналитиков. С целью упрощения излагаемого материала в этой статье рассматривалось лишь подмножество операторов и функций BigSheets, наиболее релевантное нашему учебному сценарию по исследованию медиаохвата исследовательского проекта IBM Watson, который применяет сложные аналитические механизмы для получения ответа на вопросы, представленные на естественном языке.
Если вы готовы приступить к проекту в области больших данных, обратитесь в раздел Ресурсы для получения ссылок на загрузки программного обеспечения, на онлайновые образовательные курсы и на другие материалы, связанные с BigInsights.
Выражаем особую благодарность Стефену Додду (Stephen Dodd), вице-президенту компании Effyis Inc., который санкционировал предоставление образца выходных данных приложения BoardReader для загрузки вместе с этой статьей. Кроме того, выражаем благодарность сотрудникам IBM Диане Пупонс-Викхем (Diana Pupons-Wickham) и Гэри Робинсону (Gary Robinson) за рецензирование этой статьи.
|
Описание |
Имя |
Размер |
Метод загрузки |
|---|---|---|---|
| Образец данных | sampleData.zip | 1030 КБ | HTTP |
- Оригинал статьи: Analyzing social media and structured data with InfoSphere BigInsights.
- Статья Understanding InfoSphere BigInsights содержит более подробную информацию по архитектуре продукта и по обеспечивающим технологиям.
- Видеоролик Big Data: Frequently Asked Questions for IBM InfoSphere BigInsights -Синтия Саракко (Cynthia M. Saracco) отвечает на некоторые типичные вопросы по платформе IBM Big Data и по продукту InfoSphere BigInsights.
- Демонстрация Cинтии Саракко (Cynthia M. Saracco), посвященная некоторым сценариям, которые были описаны этой статье: Big Data -- Analyzing Social Media for Watson.
- Статья Exploring your InfoSphere BigInsights cluster and sample applications содержит дополнительные сведения о веб-консоли этого продукта.
- Посмотрите следующие видеоролики, в которых Аншул Давра (Anshul Dawra) и Cинтия Саракко (Cynthia M. Saracco) объясняют инструмент BigSheets: Big Data Patent Data Analysis with BigSheets, Big Data for Business Users - an introduction to BigSheets for InfoSphere BigInsights, Big Data - BigSheets in Action.
- Ознакомьтесь с исследовательским проектом IBM Watson и с мероприятиями серии post-Jeopardy!.
- Образовательный ресурс Big Data University предлагает бесплатные курсы по технологиям Hadoop и Big Data.
- Информационный центр по продукту IBM InfoSphere BigInsights предоставляет необходимую документацию.
- Закажите книгу Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data, в которой подробно описываются две ключевых технологии IBM в области Big Data.
- Подробнее о продукте IBM InfoSphere BigInsights
- Продукты IBM Big Data
- Обратится в "Интерфейс" за дополнительной информацией/по вопросу приобретения продуктов
- Подробнее о Решениях IBM для управления большими данными (IBM Big Data)
- Статьи по теме Big Data
- Новости по теме Big Data
- Услуги по внедрению решений для обработки больших объемов данных
- Заказать проведение презентации
- Консультация по выбору решений и технологий для обработки больших объемов данных