
Несмотря на то, что Hadoop лежит в основе механизмов прореживания данных некоторых крупнейших поисковых систем, лучше описывать его в качестве фреймворка для распределенной обработки данных. Здесь нужно заметить, что обрабатываются не просто данные, а огромные массивы данных, которыми оперируют поисковые системы. Являясь распределенным фреймворком, Hadoop позволяет создавать приложения, использующие преимущества параллельной обработки данных.
Эта статья не преследует цели познакомить вас с фреймворком Hadoop и его архитектурой - в ней будет рассмотрен простой практический пример настройки Hadoop. Поэтому давайте не будем откладывать и сразу приступим к установке и настройке Hadoop.
В этой статье предполагается, что в вашей системе установлена библиотека cURL, а также имеется поддержка технологии Java™ (версии не ниже 1.6). Если эти условия не выполняются, необходимо добавить требуемый функционал, прежде чем вы сможете начать работу.
Поскольку я работаю с операционной системой Ubuntu (выпуск Intrepid), для получения дистрибутива Hadoop я использую утилиту apt. Это простая процедура позволяет мне получить готовый бинарный пакет и избавляет от необходимости загрузки и компиляции сходного кода. Сначала я сообщаю утилите apt о сайте Cloudera: создаю новый файл /etc/apt/sources.list.d/cloudera.list и добавляю в него следующий текст:
deb http://archive.cloudera.com/debian intrepid-cdh3 contrib deb-src http://archive.cloudera.com/debian intrepid-cdh3 contrib |
Если вы работаете с Jaunty или другим дистрибутивом операционной системы, просто замените слово intrepid на имя вашего дистрибутива (на данный момент поддерживаются Hardy, Intrepid, Jaunty, Karmic и Lenny).
Далее, я получаю ключ apt-key от Cloudera для проверки подлинности загруженного пакета:
$ curl -s http://archive.cloudera.com/debian/archive.key / sudo apt-key add - sudo apt-get update |
После этого я устанавливаю Hadoop, используя псевдораспределенную конфигурацию (все демоны Hadoop запускаются на одном узле):
$ sudo apt-get install hadoop-0.20-conf-pseudo $ |
Обратите внимание на то, что эта конфигурация занимает на жестком диске около 23 МБ (не считая других пакетов, которые могут быть установлены утилитой apt в процессе загрузки). Этот вариант установки идеально подходит для тех случаев, когда вы хотите познакомиться с Hadoop с целью изучения его элементов и интерфейсов.
Наконец, я настраиваю беспарольный SSH. Если при использовании команды ssh localhost система запрашивает у вас пароль, выполните следующие шаги (листинг 1). Поскольку эти действия затрагивают некоторые аспекты безопасности, я предполагаю, что мой компьютер будет полностью выделен под работу Hadoop.
Листинг 1. Настройка беспарольного SSH
$ sudo su - # ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa # cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys |
Напоследок необходимо убедиться в том, что на вашем компьютере достаточно свободного дискового пространства для размещения узла DataNode (узел этого типа является кэшем). Если места на диске окажется недостаточно, система может начать вести себя странным образом (например, выдавать ошибки с сообщениями о невозможности репликации на этот узел).
Теперь все готово к запуску Hadoop - нужно лишь запустить каждый из его демонов. Но сначала отформатируем файловую систему Hadoop File System (HDFS) с помощью команды hadoop. У этой команды существует несколько предназначений, и некоторые из них мы вскоре рассмотрим.
Сначала обратимся к узлу NameNode с запросом на форматирование файловой системы DFS. Это действие является частью установки, но о нем полезно знать на тот случай, если вам когда-нибудь потребуется создать чистую файловую систему.
# hadoop-0.20 namenode -format |
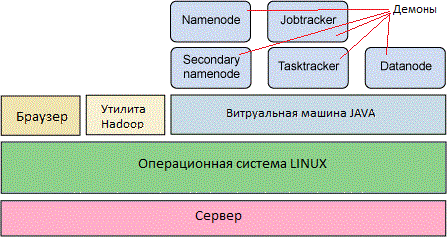
После подтверждения запроса файловая система будет отформатирована, а также будет возвращена некоторая информация. Далее запустим демоны Hadoop. В данной псевдораспределенной конфигурации запускается пять демонов Hadoop: namenode, secondarynamenode, datanode, jobtracker и tasktracker. При запуске каждого демона вы увидите несколько строк текста (указывающих, где будут храниться log-файлы). Каждый запускаемый демон будет работать в фоновом режиме. На рисунке 1 показано, как выглядит узел в псевдораспределенной конфигурации после запуска Hadoop.
Рисунок 1. Псевдораспределенная конфигурация Hadoop
Hadoop имеет несколько вспомогательных инструментов для упрощения запуска. Эти инструменты разделены на две категории - запуск (например, start-dfs) и останов (stop-dfs). Следующий небольшой сценарий показывает, как запустить узел Hadoop.
# /usr/lib/hadoop-0.20/bin/start-dfs.sh # /usr/lib/hadoop-0.20/bin/start-mapred.sh # |
Для проверки того, что все демоны запущены, можно использовать команду jps (эта команда является аналогом утилиты ps для процессов JVM), которая должна вывести список из пяти демонов и соответствующие им идентификаторы процессов.
Теперь, когда демоны Hadoop запущены, давайте посмотрим на них и разберемся, какие функции они выполняют. Демон namenode является главным сервером Hadoop и управляет пространством имен файловой системы, а также доступом к файлам, хранящимся в кластере. Существует также демон secondary namenode, который не является избыточным по отношению к namenode, а вместо этого выполняет ведение контрольных точек и прочие вспомогательные задачи. В кластере Hadoop вы обнаружите один узел типа namenode и один узел типа secondary namenode.
Демон datanode управляет хранилищем, подключенным к отдельному узлу кластера (в кластере может быть несколько узлов). На каждом узле, который хранит данные, всегда будет запущен демон datanode.
Наконец, в каждом кластере будет запущен один экземпляр демона jobtracker, который отвечает за распределение задач между узлами datanode, и по одному экземпляру демона tasktracker для каждого узла datanode, который непосредственно выполняет всю работу. Демоны jobtracker и tasktracker работают по схеме "главный-подчиненный": jobtracker распределяет задачи между узлами datanode, а tasktracker выполняет полученные задания. Кроме того, jobtracker проверяет результаты выполнения назначенных заданий, и если узел datanode по какой-то причине выходит из строя, незавершенное задание переназначается на другой узел.
В нашей простой конфигурации все узлы располагаются на одном физическом хосте (рисунок 1). Тем не менее, из предыдущих рассуждений легко понять, как Hadoop обеспечивает параллельную обработку задач. Хотя архитектура является достаточно простой, Hadoop предоставляет надежный, отказоустойчивый способ реализации распределения данных, балансировки нагрузки и параллельной обработки больших объемов данных.
Проверка файловой системы HDFS
Чтобы убедиться в том, что Hadoop (по крайней мере, узел namenode) работает без ошибок, можно выполнить ряд тестов. Зная о том, что все процессы доступны, вы можете использовать команду hadoop для проверки локального пространства имен (листинг 2).
Листинг 2. Проверка доступа к файловой системе HDFS
# hadoop-0.20 fs -ls / Found 2 items drwxr-xr-x - root supergroup 0 2010-04-29 16:38 /user drwxr-xr-x - root supergroup 0 2010-04-29 16:28 /var # |
Из вывода команды видно, что узел namenode поднят и может обслуживать локальное пространство имен. Обратите внимание на то, что для проверки файловой системы вы используете утилиту, которая называется hadoop-0.20. С помощью этой утилиты осуществляется взаимодействие с кластером Hadoop - начиная от проверки файловой системы и заканчивая выполняющимися в кластере заданиями. Обратите внимание на структуру команд: после ввода имени утилиты hadoop-0.20 указывается команда (в данном случае общая оболочка файловой системы) и необходимые параметры (в данном случае с помощью параметра ls был запрошен список файлов). Поскольку утилита hadoop-0.20 является одним из основных интерфейсов взаимодействия с кластером Hadoop, в этой статье вы будете часто использовать ее. В листинге 3 перечислены некоторые дополнительные операции с файловой системой, с помощью которых вы можете глубже изучить этот интерфейс (создание новой директории с именем test,, получение списка ее содержимого и удаление этой директории).
Листинг 3. Выполнение действий с файловой системой в Hadoop
# hadoop-0.20 fs -mkdir test # hadoop-0.20 fs -ls test # hadoop-0.20 fs -rmr test Deleted hdfs://localhost/user/root/test # |
Теперь, когда вы установили Hadoop и изучили основы работы с файловой системой, пришло время протестировать работу Hadoop в реальном приложении. В этом примере вы увидите, как работает процесс MapReduce с небольшим объемом данных. Названия операций map и reduce заимствованы от названий соответствующих операций в функциональном программировании и предоставляют базовые возможности для прореживания данных (обработки данных с целью уменьшения их объема). Операция map означает процесс разбивки входных данных на более мелкие подмножества с целью их последующей обработки (эти подмножества распределяются между параллельными обработчиками). Операция reduce означает процесс компоновки полученных от обработчиков результатов в единый набор выходных данных. Заметьте, что здесь я не упомянул, что же означает обработка, поскольку фреймворк позволяет определять это вам самим. В канонической форме MapReduce - это подсчет количества слов, встречающихся в наборе документов.
Согласно предыдущим рассуждениям, вам потребуется создать набор входных данных и получить результирующий набор. На первом шаге необходимо создать в файловой системе поддиректорию input, с которой вы будете работать. Для этого выполните следующую команду:
# hadoop-0.20 fs -mkdir input |
Далее поместите в директорию input какой-нибудь файл. В нашем примере мы будем использовать команду put, которая перемещает файл из локальной файловой системы в файловую систему HDFS (листинг 4). Обратите внимание на формат команды: здесь исходный файл перемещается в директорию HDFS (input). Теперь в файловой системе HDFS у вас появилось два текстовых файла, с которыми можно работать.
Листинг 4. Перемещение файлов в файловую систему HDFS
# hadoop-0.20 fs -put /usr/src/linux-source-2.6.27/Doc*/memory-barriers.txt input # hadoop-0.20 fs -put /usr/src/linux-source-2.6.27/Doc*/rt-mutex-design.txt input # |
Вы можете проверить наличие данных файлов с помощью команды ls (листинг 5).
Листинг 5. Проверка наличия файлов в HDFS
# hadoop-0.20 fs -ls input Found 2 items -rw-r--r-- 1 root supergroup 78031 2010-04-29 17:35 /user/root/input/memory-barriers.txt -rw-r--r-- 1 root supergroup 33567 2010-04-29 17:36 /user/root/input/rt-mutex-design.txt # |
Теперь вы можете выполнить над данными операцию MapReduce. Для этого требуется запустить единственную, но длинную команду (листинг 6). Данная команда вызывает на исполнение JAR-файл, который обладает различным функционалом, но в нашем примере просто выполняет подсчет слов (функция wordcount). Демон jobtracker посылает узлу datanode запрос на выполнение задания MapReduce, в результате чего будет получен объемный вывод (в нашем примере этот объем невелик, поскольку мы обрабатываем всего лишь два файла), который покажет нам ход работы функций map и reduce, а также некоторую полезную статистику операций ввода/вывода как для файловой системы, так и для обработки записей.
Листинг 6. Выполнение задания MapReduce для подсчета слов (wordcount)
# hadoop-0.20 jar /usr/lib/hadoop-0.20/hadoop-0.20.2+228-examples.jar wordcount input output 10/04/29 17:36:49 INFO input.FileInputFormat: Total input paths to process : 2 10/04/29 17:36:49 INFO mapred.JobClient: Running job: job_201004291628_0009 10/04/29 17:36:50 INFO mapred.JobClient: map 0% reduce 0% 10/04/29 17:37:00 INFO mapred.JobClient: map 100% reduce 0% 10/04/29 17:37:06 INFO mapred.JobClient: map 100% reduce 100% 10/04/29 17:37:08 INFO mapred.JobClient: Job complete: job_201004291628_0009 10/04/29 17:37:08 INFO mapred.JobClient: Counters: 17 10/04/29 17:37:08 INFO mapred.JobClient: Job Counters 10/04/29 17:37:08 INFO mapred.JobClient: Launched reduce tasks=1 10/04/29 17:37:08 INFO mapred.JobClient: Launched map tasks=2 10/04/29 17:37:08 INFO mapred.JobClient: Data-local map tasks=2 10/04/29 17:37:08 INFO mapred.JobClient: FileSystemCounters 10/04/29 17:37:08 INFO mapred.JobClient: FILE_BYTES_READ=47556 10/04/29 17:37:08 INFO mapred.JobClient: HDFS_BYTES_READ=111598 10/04/29 17:37:08 INFO mapred.JobClient: FILE_BYTES_WRITTEN=95182 10/04/29 17:37:08 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=30949 10/04/29 17:37:08 INFO mapred.JobClient: Map-Reduce Framework 10/04/29 17:37:08 INFO mapred.JobClient: Reduce input groups=2974 10/04/29 17:37:08 INFO mapred.JobClient: Combine output records=3381 10/04/29 17:37:08 INFO mapred.JobClient: Map input records=2937 10/04/29 17:37:08 INFO mapred.JobClient: Reduce shuffle bytes=47562 10/04/29 17:37:08 INFO mapred.JobClient: Reduce output records=2974 10/04/29 17:37:08 INFO mapred.JobClient: Spilled Records=6762 10/04/29 17:37:08 INFO mapred.JobClient: Map output bytes=168718 10/04/29 17:37:08 INFO mapred.JobClient: Combine input records=17457 10/04/29 17:37:08 INFO mapred.JobClient: Map output records=17457 10/04/29 17:37:08 INFO mapred.JobClient: Reduce input records=3381 |
После завершения обработки данных можно проверить результаты. Вспомните, что целью задания было подсчитать, сколько раз во входных данных встретилось каждое слово. Результаты помещаются в файл в виде строк, каждая из которых содержит слово и число, показывающее, сколько раз это слово было найдено. После того как вы найдете сгенерированный файл, используйте команду cat в составе утилиты hadoop-0.20, чтобы вывести результаты на экран (листинг 7).
Листинг 7. Просмотр результатов операции MapReduce для функции wordcount
# hadoop-0.20 fs -ls /user/root/output Found 2 items drwxr-xr-x - root supergroup 0 2010-04-29 17:36 /user/root/output/_logs -rw-r--r-- 1 root supergroup 30949 2010-04-29 17:37 /user/root/output/part-r-00000 # # hadoop-0.20 fs -cat output/part-r-00000 / head -13 != 1 "Atomic 2 "Cache 2 "Control 1 "Examples 1 "Has 7 "Inter-CPU 1 "LOAD 1 "LOCK" 1 "Locking 1 "Locks 1 "MMIO 1 "Pending 5 # |
С помощью утилиты hadoop-0.20 можно также извлечь файл из файловой системы HDFS (листинг 8). Для этого используется команда get (по аналогии с командой put, предназначенной для записи файлов в HDFS). Для команды get вы должны указать имя файла, который необходимо извлечь из системы HDFS (из подкаталога output), а также указать, под каким именем он будет записан в локальную файловую систему (output.txt).
Листинг 8. Извлечение результирующего файла из файловой системы HDFS
# hadoop-0.20 fs -get output/part-r-00000 output.txt # cat output.txt / head -5 != 1 "Atomic 2 "Cache 2 "Control 1 "Examples 1 # |
Рассмотрим другой пример, в котором используется тот же JAR-файл, но выполняющий уже другую функцию - параллельное выполнение команды grep. Для этого будем использовать уже имеющиеся входные файлы, а директорию output удалим - она будет создана заново в процессе выполнения.
# hadoop-0.20 fs -rmr output Deleted hdfs://localhost/user/root/output |
Далее отправим запрос на выполнение задания MapReduce для функции grep. В этом случае grep работает в параллельном режиме (операция map), после чего результаты отдельных процессов собираются в единое целое (операция reduce). В листинге 9 представлен вывод, полученный в результате использования данной модели (для краткости здесь опущена некоторая его часть). Обратите внимание на синтаксис запроса: вы указываете команде grep взять входные данные из директории input и поместить результаты в директорию output. Последний параметр - это строка поиска ('kernel').
Листинг 9. Выполнение задания MapReduce для подсчета количества совпадений при поиске строки (grep)
# hadoop-0.20 jar /usr/lib/hadoop/hadoop-0.20.2+228-examples.jar grep input output 'kernel' 10/04/30 09:22:29 INFO mapred.FileInputFormat: Total input paths to process : 2 10/04/30 09:22:30 INFO mapred.JobClient: Running job: job_201004291628_0010 10/04/30 09:22:31 INFO mapred.JobClient: map 0% reduce 0% 10/04/30 09:22:42 INFO mapred.JobClient: map 66% reduce 0% 10/04/30 09:22:45 INFO mapred.JobClient: map 100% reduce 0% 10/04/30 09:22:54 INFO mapred.JobClient: map 100% reduce 100% 10/04/30 09:22:56 INFO mapred.JobClient: Job complete: job_201004291628_0010 10/04/30 09:22:56 INFO mapred.JobClient: Counters: 18 10/04/30 09:22:56 INFO mapred.JobClient: Job Counters 10/04/30 09:22:56 INFO mapred.JobClient: Launched reduce tasks=1 10/04/30 09:22:56 INFO mapred.JobClient: Launched map tasks=3 10/04/30 09:22:56 INFO mapred.JobClient: Data-local map tasks=3 10/04/30 09:22:56 INFO mapred.JobClient: FileSystemCounters 10/04/30 09:22:56 INFO mapred.JobClient: FILE_BYTES_READ=57 10/04/30 09:22:56 INFO mapred.JobClient: HDFS_BYTES_READ=113144 10/04/30 09:22:56 INFO mapred.JobClient: FILE_BYTES_WRITTEN=222 10/04/30 09:22:56 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=109 ... 10/04/30 09:23:14 INFO mapred.JobClient: Map output bytes=15 10/04/30 09:23:14 INFO mapred.JobClient: Map input bytes=23 10/04/30 09:23:14 INFO mapred.JobClient: Combine input records=0 10/04/30 09:23:14 INFO mapred.JobClient: Map output records=1 10/04/30 09:23:14 INFO mapred.JobClient: Reduce input records=1 # |
После завершения задания давайте найдем результирующий файл в директории output и выполним команду cat, чтобы просмотреть его содержимое (листинг 10).
Листинг 10. Просмотр результатов операции MapReduce для функции grep
# hadoop-0.20 fs -ls output Found 2 items drwxr-xr-x - root supergroup 0 2010-04-30 09:22 /user/root/output/_logs -rw-r--r-- 1 root supergroup 10 2010-04-30 09:23 /user/root/output/part-00000 # hadoop-0.20 fs -cat output/part-00000 17 kernel # |
Из этого материала вы узнали, как работать с HDFS, но если вы захотите посмотреть статистику работы Hadoop, в этом вам помогут Web-интерфейсы. Вспомните, что в основе кластера Hadoop лежит узел типа NameNode, который управляет файловой системой HDFS. Обратившись по адресу http://localhost:50070, вы можете получить подробную информацию о файловой системе (например, о доступном и используемом дисковом пространстве и доступных узлах типа DataNode), а также о выполняющихся задачах. Обратившись по адресу http://localhost:50030, вы можете детально исследовать работу демона jobtracker (статус заданий). Обратите внимание на то, что в обоих случаях вы указываете адрес localhost, поскольку все демоны запущены на одном хосте.
В этой статье были рассмотрены установка и первоначальная настройка простого (псевдораспределенного) кластера Hadoop (мы использовали дистрибутив Hadoop от компании Cloudera). Я выбрал этот дистрибутив по той причине, что он упрощает процесс установки и настройки Hadoop. Вы можете найти различные дистрибутивы Hadoop (включая исходный код) на сайте apache.org.
Что, если для выполнения ваших задач вам потребуется масштабировать кластер Hadoop, но ваших аппаратных ресурсов окажется недостаточно? Оказывается, популярность Hadoop обусловлена именно тем, что вы можете легко запускать его в инфраструктуре облачных вычислений на арендованных серверах с использованием предварительно собранных виртуальных машин Hadoop. Компания Amazon предоставляет в ваше распоряжение образы Amazon Machine Images (AMIs), а также вычислительные ресурсы облака Amazon Elastic Compute Cloud (Amazon EC2). В дополнение к этому корпорация Microsoft объявила о том, что ее платформа Windows® Azure Services Platform также будет поддерживать Hadoop.
Прочитав эту статью, легко увидеть, как Hadoop упрощает распределенные вычисления для обработки больших массивов данных. В следующей статье этой серии будет рассказано, как настраивать Hadoop в многоузловой конфигурации, и будут приведены дополнительные примеры. До встречи!