
Hadoop, несомненный король анализа большой данных, ориентирован на пакетную обработку. Эта модель достаточна для решения многих задач (например, индексирования Web), но существуют и другие, в которых требуется обрабатывать информацию реального времени из высокодинамичных источников. Решение этой задачи привело к появлению системы Storm Натана Марца (теперь он работает в Twitter над BackType). Storm работает не со статическими данными, а с потоковыми, которые поступают непрерывно. Насколько полезна эта технология, легко убедиться в Twitter, где пользователи создают по 140 млн твитов в день.
Но Storm ― это не просто традиционная система анализа больших данных: это пример сложной системы обработки событий (Complex Event-Processing ― CEP). CEP-системы обычно подразделяют на вычислительные и регистрирующие, и каждый из этих классов можно реализовать в Storm с помощью пользовательских алгоритмов. Например, CEP-системы можно использовать для выявления значимых событий в потоке событий, а затем принимать меры в режиме реального времени.
Натан Марц приводит ряд примеров использования Storm в Twitter. Один из самых интересных ― получение информации о тенденциях. Twitter извлекает новые тенденции из потока твитов и отслеживает их на местном и национальном уровне. Это означает, что как только история зарождается, алгоритм поиска тенденций в темах Twitter обнаруживает ее. Этот алгоритм реального времени реализован в Storm как система непрерывного анализа данных Twitter.
Storm и традиционные большие данные
Storm отличается от других решений для обработки больших данных своей парадигмой. Hadoop представляет собой систему принципиально пакетной обработки. Данные вводятся в файловую систему Hadoop (HDFS) и распределяются между узлами для обработки. После завершения обработки полученные данные возвращается в HDFS для использования инициатором. Storm поддерживает создание топологий, которые преобразуют незавершенные потоки данных. Эти преобразования, в отличие от заданий Hadoop, никогда не прекращаются, а продолжают обрабатывать данные по мере их поступления.
Реализации систем обработки больших данных
Ядро Hadoop написано на языке Java™, но поддерживает аналитические приложения, написанные на разных языках. В последнее время появляются реализации с использованием современных языков и их особенностей. Например, система Spark Калифорнийского университета в Беркли (UC) написана на языке Scala, а Twitter Storm ― на языке Clojure.
Это современный диалект языка Lisp. Clojure, как и Lisp, поддерживает функциональный стиль программирования, но в Clojure также входят функции, упрощающие многопоточное программирование (полезная особенность для создания Storm). Clojure - это язык на основе виртуальной машины (ВМ), который работает на виртуальной машине Java. Но несмотря на то, что Storm написан на Clojure, приложения для Storm можно писать практически на любом языке. Все, что нужно ― это адаптер для подключения к архитектуре Storm. Существуют адаптеры для Scala, JRuby, Perl и PHP, а также адаптер структурированного языка запросов (SQL), который поддерживает потоковый ввод данных в топологию Storm.
Основные атрибуты Storm
Storm реализует набор характеристик, которые определяют его с точки зрения производительности и надежности. Для передачи сообщений Storm использует механизм ZeroMQ, который исключает промежуточные очереди и позволяет задачам непосредственно обмениваться сообщениями друг с другом. В основе системы обмена сообщениями лежит автоматизированный и эффективный механизм сериализации и десериализации примитивных типов Storm.
Однако наиболее интересная особенность Storm ― это его ориентированность на отказоустойчивость и управление. Storm реализует гарантированную обработку сообщений, так что каждый кортеж проходит полную обработку в рамках топологии; если кортеж оказывается не обработанным, он автоматически возвращается на вход. В Storm также реализовано обнаружение ошибок на уровне задач: в случае сбоя сообщения автоматически возвращаются на повторную обработку. Storm содержит более интеллектуальную систему управления процессом, чем у Hadoop, в которой процессами управляют супервизоры, гарантирующие адекватное использование ресурсов.
Модель Storm
Storm реализует модель передачи данных, в которой данные непрерывно проходят сквозь цепь преобразований (см. рисунок 1). Абстракция для передачи данных называется потоком (stream) и представляет собой бесконечную последовательность кортежей. Кортеж напоминает структуру, которая может содержать стандартные типы данных (массивы целых чисел, чисел с плавающей запятой и байтов) или типы, определяемые пользователем, с некоторым дополнительным кодом сериализации. Каждый поток помечается уникальным идентификатором, который можно использовать для построения топологии источников и приемников данных. Источниками потоков служат воронки (spouts), передающие данные из внешних источников в топологию Storm.
Рисунок 1. Концептуальная архитектура тривиальной топологии Storm
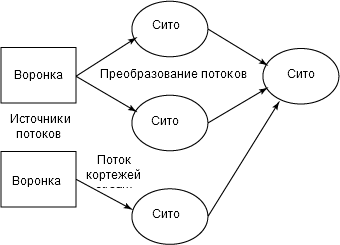
Приемники (или объекты, производящие преобразования) называются ситами (bolts). Они выполняют отдельные преобразования потока и всю обработку в топологии Storm. Сита могут решать традиционные задачи, такие как MapReduce, или выполнять более сложные действия (одношаговые функции), такие как фильтрация, агрегирование или связь с внешними объектами типа баз данных. Типичная топология Storm реализует несколько преобразований и поэтому требует нескольких сит с независимыми потоками кортежей. Воронки и сита реализованы в виде одной или нескольких задач в рамках Linux®-системы.
Storm можно использовать для простой реализации функциональности MapReduce с целью определения частотности слов. Как показано на рисунке 2, воронка генерирует поток текстовых данных, а сито реализует функцию Map (для маркировки слов в струе). Затем результирующий поток из сита Map попадает в отдельное сито, которое реализует функцию Reduce (для суммирования слов).
Рисунок 2. Простая топология Storm для выполнения функции MapReduce

Обратите внимание, что сито может направлять поток данных в несколько других сит, а также принимать данные из нескольких источников. Storm поддерживает понятие группирования потоков, реализуя перетасовку (случайное, но равномерное распределение кортежей между ситами) или группирование полей (деление потока в соответствии с его полями). Существуют и другие способы группирования потоков, включая возможность для инициатора направлять кортежи с использованием свой собственный внутренней логики.
Одна из наиболее интересных особенностей архитектуры Storm ― это концепция гарантированной обработки сообщений. Storm гарантирует, что каждый кортеж, испускаемый из воронки, будет обработан; если он не обработан в течение некоторого времени, то Storm вновь выпускает его из воронки. Для этой функциональности требуются некоторые хитроумные трюки, позволяющие отслеживать прохождение кортежа сквозь топологию, и это одно из достопримечательностей Storm.
Помимо поддержки надежного обмена сообщениями, Storm использует механизм ZeroMQ для достижения максимальной производительности обмена сообщениями (исключая промежуточные очереди и реализуя прямой обмен сообщениями между задачами). ZeroMQ содержит механизм обнаружения заторов и изменяет сообщения для оптимизации пропускной способности.
Пример прохождения через топологию Storm
Рассмотрим пример кода для реализации в Storm простой топологии MapReduce (см. листинг 1). Здесь используется красиво построенный пример подсчета слов из предложенного Натаном на GitHub комплекта документации storm-starter kit. Этот пример иллюстрирует топологию, показанную на рисунке 2, которая реализует map-преобразование, состоящее из сита, и reduce-преобразование, состоящее из отдельного сита.
Листинг 1. Построение топологии Storm для рисунка 2
01 TopologyBuilder builder = new TopologyBuilder();
02
03 builder.setSpout("spout", new RandomSentenceSpout(), 5);
04
05 builder.setBolt("map", new SplitSentence(), 4)
06 .shuffleGrouping("spout");
07
08 builder.setBolt("reduce", new WordCount(), 8)
09 .fieldsGrouping("map", new Fields("word"));
10
11 Config conf = new Config();
12 conf.setDebug(true);
13
14 LocalCluster cluster = new LocalCluster();
15 cluster.submitTopology("word-count", conf, builder.createTopology());
16
17 Thread.sleep(10000);
18
19 cluster.shutdown();Листинг 1 (номера строк добавлены для справок) начинается с объявления новой топологии с использованием TopologyBuilder. Далее, в строке 3 определена воронка (с именем spout), которая состоит из класса RandomSentenceSpout. Класс RandomSentenceSpout (а именно, метод nextTuple) выдает в качестве данных одно из пяти случайных предложений. Аргумент 5 в конце метода setSpout ― намек на параллелизм (это количество задач для организации данной деятельности).
В строках 5 и 6 я определяю первое сито (или объект алгоритмического преобразования)- в данном случае сито распределения (или разделения). Это сито использует метод SplitSentence для маркировки входного потока и выдает на выходе отдельные слова. Обратите внимание на использование метода shuffleGrouping в строке 6, который определяет входную подписку на это сито (в данном случае, spout), а также на то, что группирование потоков определено как тасование (shuffle). Это означает, что входные данные из воронки будут перетасовываться, то есть распределяться случайным образом между задачами внутри данного сита (где есть намек на параллелизм решения четырех задач).
В строках 8 и 9 я определяю последнее сито, которое служит эффективным элементом сокращения, на вход которого подаются данные из сита распределения. Метод WordCount реализует необходимое действие подсчета слов (группирование похожих слов для получения общей суммы), но без тасования, так что на его выходе будут последовательные данные. Если несколько задач выполняют действие сокращения, то в итоге получатся отдельные суммы, а не общая сумма.
В строках 11 и 12 создается и определяется объект конфигурации и включается режим Debug. Класс Config содержит большое количество возможных конфигураций.
Строки 14 и 15 создают локальный кластер (в данном случае, определение использования режима Local). Я определяю имя своего локального кластера, свой объект конфигурации и топологию (извлекается через элемент createTopology класса builder).
Наконец, Storm ожидает некоторое время в строке 17, а затем в строке 19 выключает кластер. Помните, что Storm ― это операционная система непрерывного действия, поэтому задачи могут существовать продолжительное время, обрабатывая все новые кортежи в потоках, на которые они подписаны.
Подробнее об этой удивительно простой реализации, включая детали строения воронки и сита, можно прочесть в документации storm-starter kit.
Применение Storm
Натан Марц составил документацию с описанием процесса установки Storm как на кластеры, так и на локальные узлы. Локальный режим позволяет использовать Storm без большого кластера. Если Storm нужно использовать в кластере, но узлов не хватает, можно реализовать также кластер Storm в облаке Amazon Elastic Compute Cloud (EC2).
Другие решения с открытым исходным кодом для обработки больших данных
С тех пор как компания Google в 2004 году ввела парадигму MapReduce, появилось несколько решений, использующих оригинальную парадигму MapReduce (или обладающих аналогичными качествами). Оригинальное приложение Google MapReduce было предназначено для индексации World Wide Web. Хотя это приложение остается популярным, число задач, решаемых с помощью этой простой модели, растет.
В таблице 1 предоставлен список доступных решений с открытым исходным кодом для обработки больших данных, включая традиционные приложения пакетной и потоковой обработки. Почти за год до появления открытого исходного кода Storm в проекте Apache появился открытый исходный код распределенной платформы потоковых вычислений Yahoo! S4. Он был выпущен в октябре 2010 года и представляет собой платформу высокопроизводительных вычислений (HPC), которая скрывает от разработчика приложения всю сложность параллельной обработки. S4 реализует децентрализованную кластерную архитектуру, которая масштабируется и включает частичную отказоустойчивость.
Таблица 1. Решения с открытым исходным кодом для обработки больших данных
| Решение | Разработчик | Тип | Описание |
|---|---|---|---|
| Storm | Потоковая | Новое решение для потокового анализа больших данных Twitter | |
| S4 | Yahoo! | Потоковая | Распределенная платформа потоковой обработки Yahoo! |
| Hadoop | Apache | Пакетная | Первая реализация парадигмы MapReduce с открытым исходным кодом |
| Spark | UC Berkeley AMPLab | Пакетная | Новая аналитическая платформа, поддерживающая наборы данных в оперативной памяти и отказоустойчивость |
| Disco | Nokia | Пакетная | Распределенная среда MapReduce Nokia |
| HPCC | LexisNexis | Пакетная | HPC-кластер для больших данных |
Заключение
Hadoop продолжает оставаться наиболее популярным аналитическим решением для обработки большой данных, но существуют многие другие системы с разными характеристиками. В предыдущих статьях я рассказал о платформе Spark с возможностью хранения наборов данных в оперативной памяти (и восстановления потерянных данных). Но Hadoop и Spark ориентированы на пакетную обработку больших наборов данных. Storm же предоставляет собой новую модель для анализа больших данных, и так как эта платформа недавно представлена в виде открытого исходного кода, она вызывает значительный интерес.
В отличие от Hadoop, Storm ― это вычислительная система без хранения данных. Это позволяет использовать Storm в различных контекстах независимо от того, поступают ли данные динамически из нетрадиционных источников или хранятся в базе данных (или же вводятся для манипуляций реального времени контроллером некоторого другого устройства, такого как торговая система).