Относительно недорогие и высокопроизводительные базы данных типа NoSQL (Not Only SQL) обладают некоторыми особенностями, которые весьма полезны применительно к масштабируемости данных: горизонтальная масштабируемость; поддержка более слабых моделей согласованности, более гибких схем и моделей данных; поддержка простых низкоуровневых интерфейсов для запросов. В статье описываются возможности и функции нескольких баз данных типа NoSQL, в том числе HBase, MongoDB и SimpleDB. Кроме того, в статье рассматриваются основы проектирования облачных баз данных и баз данных типа NoSQL.
Быстрое распространение основанных на Интернете сервисов - таких как электронная почта, блоги, социальные сети, поисковые механизмы и электронная коммерция - существенно изменило поведение и склонности веб-пользователей в отношении создания, передачи и получения контента, обмена информацией и покупки товаров. ИТ-специалисты отмечают быстрый рост масштабов генерируемых и потребляемых данных в результате распространения вышеупомянутых систем; постоянно растущая потребность в масштабируемости и новые требования к приложениям породили новые проблемы для традиционных систем управления реляционными базами данных (реляционных СУБД).
Здесь на сцену выходят недорогое и высокопроизводительное программное обеспечение баз данных типа NoSQL. Основные особенности программного обеспечения баз данных типа NoSQL:
- Возможность горизонтального масштабирования данных.
- Поддержка более слабых моделей согласованности (Consistency - одно из т. н. ACID-свойств: Atomicity, Consistency, Isolation, Durability, гарантирующих надежную обработку транзакций базы данных).
- Возможность использования гибких схем и моделей данных.
- Поддержка простых низкоуровневых интерфейсов для запросов.
В статье рассматриваются современные достижения в области систем управления базами данных, обеспечивающие поддержку управление данными веб-масштаба. В статье содержится обзор возможностей и особенностей нескольких разновидностей NoSQL-систем - HBase, MongoDB и SimpleDB - и рассматривается пригодность каждой из этих систем для поддержки веб-приложений различных типов.
Основы проектирования облачных баз данных
Итак, каким образом облачные вычисления изменили способ взаимодействия пользователей с данными?
Простые транзакции данных для каждого
Благодаря современным достижениям в области веб-технологий любой пользователь может легко предоставлять и потреблять контент, представленный в любой форме. Примеры.
- Создание персональной веб-страницы (например, с помощью Google Sites).
- Создание блога (с помощью WordPress, Blogger, LiveJournal).
- Взаимодействие в онлайн-сообществах (Facebook, Twitter, LinkedIn и т. д.).
Эти возможности предоставляются "потребительскими", массовыми инструментами, которые позволили более широкому кругу людей с легкостью создавать, потреблять и передавать (осуществлять т. н. "транзакции") больше данных, представленных в более разнообразных формах (сообщений в блогах, твитов, взаимодействий в социальных сетях, видео, аудио, фотографий - т. е. структурированных и неструктурированных данных).
Приложения превращаются в распределенные масштабируемые сервисы
Очевидно, что следующая цель производителей систем и инструментов состоит в облегчении превращения приложений в распределенные, масштабируемые и широко доступные через Интернет-сервисы (см. соответствующие сервисы Facebook, Flickr, YouTube, Zoho, LinkedIn).
Характерными особенностями приложений, отвечающих этим критериям, являются высокая интенсивность обработки данных и высокая степень интерактивности. Например, на момент написания этой статьи сеть Facebook заявляла о наличии 800 млн. активных пользователей в месяц (а сейчас их, скорее всего, уже больше миллиарда). Каждый пользователь Facebook в среднем имеет 130 т. н. "дружеских связей" (friendship relation). Кроме того, имеется примерно 900 млн. объектов, с которыми взаимодействуют зарегистрированные пользователи Facebook (таких как страницы, группы, события и страницы сообществ).
Другие социальные сети имеют несколько меньший масштаб, например, сеть LinkedIn, которая используется преимущественно специалистами, недавно достигла уровня в 200 млн. зарегистрированных пользователей. Сеть Twitter заявила о наличии более 100 млн. активных пользователей в месяц. Общепризнанная конечная цель состоит в том, чтобы облегчить каждому желающему достижение столь высокого уровня масштабируемости и доступности; проблема состоит в том, как сделать это с минимальными усилиями и ресурсами.
Облачные модели облегчают развертывание сервисов
Технология облачных вычислений - это относительно новая модель хостинга приложений (хотя облачные среды настолько интегрированы, что сейчас уже практически неотделимы от остальной инфраструктуры обработки транзакций в Интернете). Облачная модель упрощает трудоемкие процессы приобретения и инициализации аппаратных средств и развертывания программного обеспечения. Это открывает новые революционные возможности для коммерциализации и доставки клиентам вычислительных ресурсов и сервисов. В частности, эта модель переносит инфраструктуру в сеть с целью уменьшения затрат, связанных с управлением аппаратными и программными ресурсами.
Другими словами, облако воплощает давнюю мечту о превращении вычислительных средств в общедоступный ресурс, позволяя за счет экономии на масштабе эффективно снизить стоимость вычислительной инфраструктуры.
Применительно к развертыванию приложений облачные вычисления сулят такие преимущества, как оплата по фактическому использованию, высокая скорость выхода на рынок, а также (практическая) неограниченность ресурсов и бесконечная масштабируемость с точки зрения потребителя.
Новая модель дистрибуции - больше новых данных и больше типов данных
На практике преимущества модели облачных вычислений состоят в том, что она открывает новые способы развертывания инновационных приложения, которые не были экономически реализуемы при традиционной организации корпоративной инфраструктуры. Поэтому облако становится все более популярной платформой для хостинга приложений в самых разных областях, включая электронную розничную торговлю, финансы, новости и социальные сети. Кроме того, быстрое увеличение количества приложений порождает огромное увеличение масштабов данных, генерируемых и используемых этими приложениями. Вот почему размещенная в облаке система управления базами данных, поддерживающая эти приложения, является критически важным компонентом в стеке программного обеспечения этих приложений.
Облачные модели порождают модель облачной базы данных
Чтобы справиться с проблемами размещения баз данных в средах облачных вычислений, предложено множество систем и подходов. На практике существуют три основные технологии, которые обычно используются для развертывания уровня баз данных в стеке программных приложений на облачных платформах.
- Виртуализированные серверы баз данных
- База данных как сервисная платформа
- Системы хранения данных типа NoSQL
Роль виртуализации
Виртуализация является ключевым компонентом технологий облачных вычислений; она позволяет абстрагироваться от физических деталей аппаратных средств и предоставляет виртуализированные ресурсы для высокоуровневых приложений.
Виртуализированный сервер обычно называется виртуальной машиной. Виртуальные машины позволяют изолировать приложения от обеспечивающих аппаратных средств и от других виртуальных машин. В идеальном случае любая виртуальная машина не воспринимается и не затрагивается другими виртуальными машинами, функционирующими на той же физической машине.
В принципе технологии виртуализации ресурсов добавляют гибкий перестраиваемый уровень программного обеспечения между приложениями и ресурсами, которые используются этими приложениями. Концепция, описывающая виртуализированный сервер баз данных, использует эти преимущества, особенно когда уровень базы данных существующего приложения, спроектированного для применения в обычном центре обработки данных, можно непосредственно портировать на виртуальные машины в публичном облаке.
Как правило, подобный процесс миграции требует лишь минимальных изменений в архитектуре и программном коде развернутого приложения. В подходе, основанном на виртуализированной базе данных, серверы баз данных (как и любые другие программные компоненты) для исполнения перемещаются на виртуальные машины. Хотя инициализация виртуальной машины для каждой копии базы данных порождает определенные издержки с точки зрения производительности, эти издержки оцениваются величиной менее 10%. На практике одно из основных преимуществ подхода на основе виртуализированной базы данных заключается в том, что при необходимости приложение может иметь полный контроль над динамическим выделением и конфигурированием физических ресурсов уровня баз данных (серверов баз данных).
В результате приложения способны полностью использовать свойство эластичности облачной среды для достижения заранее заданных или настраиваемых целевых показателей масштабируемости или снижения затрат; однако для достижения этих целей требуется компонент для управления доступом, который отвечал бы за мониторинг состояния системы и за выполнение соответствующих действий (например, за выделение увеличенного/уменьшенного объема вычислительных ресурсов) согласно заданным требованиям приложений и стратегиям. Основные обязанности этого компонента состоят в принятии решений о том, когда активировать увеличение или уменьшение количества виртуализированных серверов баз данных, выделяемых программному приложению.
Роль мультиаренды в центрах обработки данных
Во многих случаях центры обработки данных используются недостаточно вследствие таких причин, как избыточное выделение ресурсов и изменяющиеся по времени потребности в ресурсах со стороны типичных корпоративных приложений. Мультиаренда (Multi-tenancy) - это механизм оптимизации хостинговых сервисов, при котором несколько клиентов консолидируется в рамках одной операционной системы (на сервере исполняется единственный экземпляр программного обеспечения, обслуживающий несколько клиентов), благодаря чему экономия на масштабе помогает эффективно снижать стоимость вычислительной инфраструктуры.
В частности мультиаренда позволяет объединять ресурсы в пул, что повышает коэффициент использования ресурсов благодаря избавлению от необходимости выделения ресурсов каждому арендатору в соответствии с его максимальной нагрузкой. Это делает мультиаренду привлекательным механизмом для следующих сторон.
- Поставщики облачных сервисов (получают возможность обслужить больше клиентов уменьшенным количеством машин)
- Потребители облачных сервисов (избавляются от обязанности оплачивать аренду всех ресурсов сервера).
База данных как сервис- это концепция, согласно которой сторонний поставщик осуществляет хостинг реляционной базы данных и предоставляет ее как сервис. Такие сервисы в значительной степени избавляют пользователей от необходимости приобретать дорогие аппаратные и программные средства, заниматься обновлениями программного обеспечения, а также привлекать специалистов для выполнения административных задач и технического обслуживания.
Как ожидается, реальная миграция любого приложения на уровне базы данных в сервис реляционной базы данных потребует минимальных усилий, если обеспечивающая реляционная СУБД для существующего приложения будет совместима с предложенным сервисом. Однако поставщик услуг по различным причинам может наложить определенные ограничения или создать те или иные препятствия (например, ограничения по максимальному размеру хостинговой базы данных, максимальному количеству возможных параллельных соединений и т. д.). Кроме того, программные приложения не обладают достаточной гибкостью для управления ресурсами, выделенными другим приложениям (например, для динамического выделения дополнительных ресурсов с целью обслуживания увеличивающейся рабочей нагрузки или для динамического уменьшения выделенных ресурсов с целью уменьшения операционных расходов). Весь процесс управления ресурсами и их распределения контролируется на стороне поставщика сервиса, что требует точного планирования распределяемых вычислительных ресурсов для уровня баз данных и ограничивает способность приложений заказчика в максимальной степени использовать потенциальные преимущества посредством задействования таких особенностей облачной среды, как эластичность и масштабируемость.
Почему реляционные базы данных могут оказаться неоптимальными
Вообще говоря, системы управления реляционными базами данных на протяжении нескольких десятилетий рассматривались как универсальное решение для обеспечения сохранения и извлечения данных. Они достигли высокого уровня зрелости в результате обширных научно-исследовательских усилий и породили большой успешный рынок и множество решений для различных областей бизнеса.
Постоянно растущая потребность в масштабируемости и в новых приложениях породила новые проблемы для традиционных реляционных СУБД, в т. ч. определенную неудовлетворенность результатами применения такого универсального решения в некоторых приложениях веб-масштаба. Ответом на эту проблему было новое поколение недорогого высокопроизводительного программного обеспечения управления базами данных, призванного преодолеть доминирование систем управления реляционными базами данных. Одна из причин перехода к NoSQL-решениям состоит в том, что различные реализации веб-приложений, корпоративных приложений и облачных приложений предъявляют различные требования к своим базам данных, - например, не каждому приложению требуется жесткая согласованность данных.
Еще один пример. Для веб-сайтов с большим объемом трафика, таких как eBay, Amazon, Twitter и Facebook, масштабируемость и высокая доступность - это важнейшие требования, которые должны соблюдаться в обязательном порядке. Для этих приложений даже малейшая остановка может иметь существенные финансовые последствия и отрицательно повлиять на доверие потребителей.
Теперь рассмотрим базовые принципы конструирования базы данных типа NoSQL.
Известная теорема CAP (Consistency, Availability, Tolerance to Partitions - Согласованность, Доступность, Устойчивость к разделению) показывает, что распределенная система управления базами данных на практике способна обеспечить выполнение не более двух из трех указанных свойств. Большинство подобных систем жертвует требованием строгой согласованности (дополнительная информация по эволюции теоремы CAP приведена на врезке). В частности, в этих системах применяется политика ослабленной согласованности под названием согласованность в конечном счете (eventual consistency), которая гарантирует, что если к реплицированному объекту не будут применяться никакие новые обновления, то в конечном счете каждое обращение к этому объекту будет возвращать последнее обновленное значение. В отсутствие ошибок максимальный размер окна несогласованности может быть определен на основе таких факторов, как коммуникационные задержки, нагрузка на систему и количество копий, затрагиваемых схемой репликации.
Новые NoSQL-системы обладают несколькими общими конструктивными особенностями.
- Возможность горизонтального масштабирования пропускной способности с охватом множества серверов.
- Простой интерфейс/протокол уровня вызова (в отличие от SQL-связывания).
- Поддержка более слабых моделей согласованности, чем ACID-транзакции в большинстве традиционных реляционных СУБД.
- Эффективное использование распределенных индексов и оперативной памяти для хранения данных.
- Возможность динамического описания новых атрибутов или схемы данных.
Перечисленные конструктивные особенности этих систем ориентированы в первую очередь на достижение следующих системных характеристик.
- Доступность: Система должна быть доступной даже в ситуации отказа сети или отключения всего центра обработки данных.
- Масштабируемость: Система должна быть в состоянии поддерживать очень большие базы данных с очень высокой частотой запросов при очень низкой задержке.
- Эластичность: Система должна быть в состоянии удовлетворять меняющиеся требования к приложениям в обоих направлениях (увеличение масштаба или уменьшение масштаба). Кроме того, система должна быть способна корректно реагировать на эти меняющиеся требования и быстро восстанавливать свое устойчивое состояние.
- Выравнивание нагрузки: Система должна быть в состоянии автоматически перемещать нагрузки между серверами с целью эффективного использования большей части аппаратных ресурсов и избежания любых ситуаций с перегрузкой ресурсов.
- Отказоустойчивость: Система должна быть в состоянии учитывать тот факт, что даже самые потенциально редкие аппаратные проблемы могут однажды воплотиться в реальность. Хотя аппаратный отказ остается серьезной проблемой, эта проблема должна решаться на архитектурном уровне базы данных, а не требовать привлечения разработчиков, администраторов и техников с целью создания собственных резервированных решений.
И действительно, продукты Google BigTable и Amazon Dynamo подтвердили реализуемость этой концепции, что вдохновило и инициировало разработку всех NoSQL-систем.
- Продукт BigTable продемонстрировал, что персистентное хранилище записей способно масштабироваться до уровня в тысячи узлов.
- Продукт Dynamo первым реализовал идею "согласованности в конечном счете" как способа достижения более высокого уровня доступности и масштабируемости.
Сообщество разработчиков ПО с открытым исходным кодом отреагировало на это созданием таких систем, как HBase, Cassandra, Voldemort, Riak, Redis, Hypertable, MongoDB, CouchDB, Neo4j, а также множеством других проектов. Эти проекты отличаются друг от друга преимущественно принятыми в них решениями относительно альтернативных подходов к проектированию.
- Модель данных: Ключ/значение, хранилище строк, ориентация на граф или ориентация на документ.
- Оптимизация маршрута доступа: Высокая интенсивность операций чтения - высокая интенсивность операций записи или один ключ - несколько ключей.
- Секционирование данных: Ориентация на строку, ориентация на столбец, ориентация на несколько столбцов.
- Управление совместным исполнением: Сильная согласованность, согласованность в конечном счете, слабая согласованность.
- Теорема CAP: CP, CA или AP.
Теперь рассмотрим возможности и функции основных представителей для различных альтернативных реализаций NoSQL-систем, а именно SimpleDB, HBase и MongoDB.
SimpleDB
SimpleDB - это коммерческий сервис инфраструктуры AWS (Amazon Web Services), предназначенный для использования в качестве хранилища структурированных данных в облаке и поддерживаемый кластерами серверов баз данных, управление которым осуществляет Amazon. Это высоконадежное и гибкое нереляционное хранилище данных, которое берет на себя работу по администрированию баз данных. На практике SimpleDB представляет собой размещенный в облаке (хостинговый) сервис хранения данных, поддерживающий различные прикладные интерфейсы (такие как REST API), что обеспечивает удобство использования и получение доступа любому приложению, хостинг которого осуществляется сервисом IBM® SmartCloud® Enterprise.
Для хранения данных в SimpleDB не требуется никакой информации о заранее заданной схеме. Разработчики просто сохраняют и запрашивают элементы данных посредством запросов к веб-сервисам, а SimpleDB делает все остальное. Не существует никакого правила, которое заставляло бы каждый элемент данных (запись данных) иметь одинаковые поля; однако отсутствие схемы означает также отсутствие типов данных, поскольку все значения данных рассматриваются как символьные данные переменной длины.
К недостаткам хранилища данных без схемы также относятся отсутствие автоматической проверки на целостность в базе данных (внешние ключи отсутствуют) и повышение нагрузки на приложение в связи с форматированием и преобразованием типов.
Структура калькуляции цен за пользование SimpleDB предусматривает плату за хранение данных, за передачу данных и за использование процессоров; при этом базовая плата и минимальная плата отсутствуют. Подобно большинству AWS-сервисов, SimpleDB предоставляет простой API-интерфейс, который следует правилам и принципам протоколов REST и SOAP, согласно которым для выполнения какой-либо операции пользователь отправляет сообщение с соответствующим запросом. Сервер SimpleDB выполняет операции, если нет ошибки, и возвращает код успеха и данные ответа. Данные ответа представляют собой пакет HTTP-ответа в формате XML, который имеет заголовки, метаданные хранения и определенную полезную нагрузку.
Высшим уровнем абстрактного элемента хранения данных в SimpleDB является т. н. домен (domain). В качестве грубой аналогии можно сказать, что домен похож на таблицу базы данных, в которой можно создавать и удалять домены по мере необходимости. Для создания домена не предоставляется никаких проектировочных или конфигурационных опций. Единственным параметром, который можно задать, является имя домена.
Все данные, хранящиеся в домене SimpleDB, принимают форму пар атрибутов "значение-ключ". Каждая пара атрибутов связана с элементом, который играет роль строки таблицы. Имя атрибута подобно имени столбца базы данных, однако различные элементы (строки) могут содержать различные имена атрибутов, что позволяет свободно хранить различные атрибуты в некоторых элементах без изменения расположения других элементов, которые не имеют таких же атрибутов. Подобная гибкость позволяет безболезненно добавлять новые поля данных в типичной ситуации изменения схемы или развития схемы.
Кроме того, каждый атрибут может иметь не одно значение, а массив значений (многозначные атрибуты). В этом случае разработчику достаточно добавить другой атрибут к элементу и использовать это же имя атрибута, но с иным значением. Каждое значение автоматически индексируется при его добавлении, однако нет никаких явных индексов, подлежащих техническому сопровождению, и соответственно нет необходимости в техническом сопровождении индексов. С другой стороны, разработчик не имеет прямого контроля над созданными индексами.
Следующий фрагмент кода на Java™ представляет собой пример создания домена SimpleDB.
SimpleDB simpleDB = new SimpleDB(accessKeyID, secretAccessKey);
try {
simpleDB.createDomain("employee");
System.out.println("create domain succeeded");
} catch (SDBException e) {
System.err.printf("create domain failed");
}В этом примере переменные accessKeyID и secretAccessKey представляют собой учетные данные AWS для подключающегося пользователя, а employee представляет собой создаваемое доменное имя. Другие доменные операции, поддерживаемые SimpleDB:
- Операция
DeleteDomain- удаляет навсегда все данные, ассоциированные с существующим именованным доменом. - Операция
ListDomains- возвращает список всех доменов, ассоциированных с учетной записью пользователя. - Операция
DomainMetadata- возвращает подробную информацию об одном конкретном домене, например:ItemCount- возвращает количество всех элементов в домене.AttributeNameCount- возвращает количество всех уникальных имен атрибутов в домене.AttributeValueCount- возвращает количество всех пар "имя/значение" в домене.
Следующий фрагмент кода представляет собой пример сохранения данных с помощью операции PutAttribute:
SimpleDB simpleDB = new SimpleDB(accessKeyID, secretAccessKey);
ItemAttribute[] employeeData = new empAttribute[] {
new ItemAttribute("empID", "JohnS"),
new ItemAttribute("first_name", "John"),
new ItemAttribute("last_name", "Smith"),
new ItemAttribute("city", "Sydney"),
};
try {
Domain domain = simpleDB.getDomain("employee");
Item newItem = domain.getItem("E12345");
newItem.putAttributes(Arrays.asList(employeeData));
System.out.println("put attributes succeeded");
} catch (SDBException e) {
System.err.printf("put attributes failed");
}В следующем фрагменте Java-кода показано получение ранее сохраненных данных.
SimpleDB simpleDB = new SimpleDB(accessKeyID, secretAccessKey);
try {
Domain domain = simpleDB.getDomain("users");
Item item = domain.getItem("E12345");
String fname = user.get("first_name ");
String lname = user.get("last_name ");
String city = user.get("city");
System.out.printf("%s %s %s", fname, lname, city);
} catch (SDBException e) {
System.err.printf("get attributes failed");
}Другие операции манипулирования данными, которые поддерживаются в SimpleDB:
- Операция
BatchPutAttributes- позволяет хранить данные для нескольких элементов в одном вызове. - Операция
DeleteAttributes- удаляет данные для элементов, которые ранее хранились в SimpleDB.
API-интерфейс SimpleDB Select API использует язык запросов, подобный SQL-оператору Select. Благодаря этому операции SimpleDB Select оказываются хорошо знакомыми пользователю, что упрощает его обучение. Необходимо учитывать, что этот язык поддерживает запросы только в масштабе одного домена (т. е. без соединений, без нескольких доменов и без запросов sub-Select). Например, следующий оператор SimpleDB Select выбирает фильмы с самым высоким рейтингом в обеспечивающем домене.
SELECT * FROM movies WHERE rating > '04' ORDER BY rating LIMIT 10
В показанном выше примере movies- это имя домена, а rating- атрибут фильтрации для элементов этого домена. Поскольку в SimpleDB имеется индекс для каждого атрибута, этот индекс можно использовать для оптимизации оценки по каждому предикату запроса. В рамках плана исполнения запроса SimpleDB пытается автоматически выбрать наилучший индекс для каждого запроса.
В SimpleDB реализованы сложные внутренние механизмы репликации и переключения при отказе, поэтому SimpleDB гарантирует высокую доступность данных за счет автоматической репликации своих данных в различные местоположения. Для достижения целевого уровня высокой доступности пользователю нет необходимости прилагать какие-либо дополнительные усилия или становиться специалистом по обеспечению высокой доступности или по технологиям репликации.
Для каждого пользовательского запроса на чтение SimpleDB поддерживает две опции - "согласованность в конечном счете" или "сильная согласованность". В общем случае использование опции согласованного чтения устраняет необходимость в окне согласованности для запроса. Результаты согласованного чтения гарантированно возвращают большинство актуальных значений. В большинстве случаев согласованное чтение происходит не медленнее, чем согласованное чтение в конечном счете, однако согласованные запросы чтения в некоторых случаях могут иметь более высокую задержку и меньшую пропускную способность (например, в случае тяжелых рабочих нагрузок). SimpleDB не предлагает гарантий относительно окна согласованности в конечном счете, однако достаточно часто продолжительность окна составляет менее одной секунды.
При работе с сервисом SimpleDB пользователю необходимо учитывать лишь несколько ограничений.
- Максимальный размер хранилища в пересчете на домен составляет 10 ГБ.
- Максимальное количество значений атрибутов в домене составляет 1 млрд.
- Максимальное количество значений атрибутов в элементе составляет 256.
- Максимальная длина имени элемента, имени атрибута или значения составляет 1024 Б.
- Для запросов:
- Максимальное время исполнения запроса составляет 5 секунд.
- Максимальное количество результатов запроса составляет 2500.
- Максимальный размер ответа на запрос составляет 1 МБ.
HBase
Apache HBase - база данных экосистемы Hadoop - представляет собой распределенную систему хранения структурированных данных, которая спроектирована в расчете на горизонтальное масштабирование до очень больших размеров с использованием массовых компьютеров. Это проект Apache, в котором честно реализован клон архитектуры хранения BigTable (к числу других клонов BigTable относятся проект Apache Cassandra и проект Hypertable). На практике кластеры HBase могут устанавливаться и исполняться на любом облачном IaaS-сервисе поставщика, таком как IBM SmartCloud Enterprise. Построенный поверх Hadoop продукт IBM InfoSphere® BigInsights™ обеспечивает возможности, соответствующие требованиям корпоративных пользователей .
Продукт HBase, выпущенный в 2007 г., представляет собой разреженную распределенную персистентную многомерную сортированную таблицу. Эта таблица индексируется по ключу строки, по ключу столбца и по метке времени. Каждое значение в этой таблице представляет собой неинтерпретируемый массив байтов, поэтому клиентам обычно приходится сериализовать различные формы структурированных и полуструктурированных данных в виде соответствующих строк. Рассмотрим конкретный пример, который демонстрирует ряд основных проектировочных решений HBase. В этом сценарии мы хотим сохранить копию большой коллекции веб-страниц в виде единственной таблицы.
На рис. 1 показан пример таблицы, в которой URL-адреса используются в качестве ключей строк, а различные аспекты веб-страниц используются в качестве имен столбцов. Содержимое веб-страниц хранится в единственном столбце, который сохраняет несколько версий страницы с метками момента времени, в который они были выбраны.
Рисунок 1. Пример записи в таблице HBase
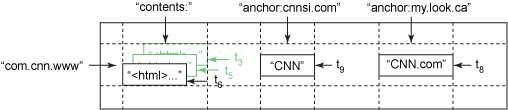
Ключи строк в таблице представляют собой произвольные строки; каждая операция чтения/записи данных с одним ключом строки является атомарной. HBase поддерживает лексикографическое упорядочение данных по ключам строк, при этом диапазон строк для таблицы динамически секционируется. Наличие всегда отсортированных ключей строк может служить аналогом индекса первичного ключа, применяемого в реляционных базах данных.
Хотя в исходной реализации BigTable имеется лишь один индекс, в HBase добавлена поддержка вторичных индексов. Каждый диапазон строк в каждой таблице, т.н. таблет (tablet), представляет собой минимальный блок для распределения и выравнивания нагрузки. Операции чтения коротких диапазонов строк являются эффективными и обычно требуют обмена данными лишь с небольшим количеством машин.
HBase может иметь неограниченное число столбцов, сгруппированных в наборы под названные column families (семейства столбцов). Семейства столбцов представляют собой базовую единицу управления доступом. Данные хранятся по столбцам, при этом нет необходимости хранить значения, если они равны нулю, поэтому HBase хорошо подходит для разреженных наборов данных. К каждому значению столбца (каждой ячейке) добавляется метка времени - это делает система неявным образом или пользователь явным образом. Это означает, что каждая ячейка в BigTable может содержать несколько версий одних и тех же данных, индексированных своими метками времени. Пользователь может гибко задавать количество версий конкретного значения, подлежащих сохранению. Версии хранятся в порядке уменьшения метки времени, поэтому более новые версии всегда могут быть прочитаны в первую очередь. Таким образом, доступ к данным можно представить следующим образом.
(Table, RowKey, Family, Column, Timestamp) --> Value
Тот факт, что операции чтения коротких диапазонов строк требуют передачи небольшого объема данных, может повлиять на разработку запросов, чтобы они соответствовали имеющимся сетевым ресурсам. На физическом уровне HBase использует распределенную файловую систему Hadoop вместо файловой системы Google. HBase помещает обновления в память и периодически записывает их в файлы на диск.
Базовая единица масштабируемости и выравнивания нагрузки в HBase называется region (регион). По существу регионы - это непрерывные диапазоны строк, хранящихся вместе. Когда регионы становятся слишком большими, система осуществляет их динамическое секционирование; регионы также могут объединяться с целью уменьшения их количества и количества файлов хранения, требующихся для их хранения.
Первоначально в таблице имеется лишь один регион; когда вы начинаете добавлять в него данные, система следит за его размером, чтобы исключить превышение заданного максимума. При превышении этого предела регион делится на две части по среднему ключу региона, в результате чего создаются две примерно равные половины. Каждый регион обслуживается ровно одним сервером региона, а каждый из этих серверов в любой момент времени способен обслуживать несколько регионов.
Разделение и обслуживание региона может рассматриваться как аналог автоматического шардинга (sharding) - метода, предлагаемого другими системами. Серверы региона можно добавлять и удалять без прекращения работы системы. Мастер-система отвечает за присвоение регионов серверам регионов; для выполнения этой задачи используется Apache ZooKeeper - надежный, обладающий высокой доступностью, персистентный и распределенный координационный сервис. Этот же сервис обрабатывает изменения схемы, такие как создание таблиц и семейств столбцов.
В HBase все операции, изменяющие данные, гарантированно являются атомарными на построчной основе. HBase использует т.н. оптимистичное управление параллелизмом, которое прерывает любые операции в случае конфликтов с другими обновлениями. Это затрагивает все остальные параллельные операции чтения/записи в одной и той же строке, поскольку эти операции или читают согласованную последнюю "мутацию", или дожидаются возможности применения своих изменений. Для хранения данных и доступа к ним HBase предоставляет API-интерфейсы Java API, Thrift API, REST API и JDBC/ODBC-соединение.
В следующем фрагменте кода показан пример сохранения данных в HBase.
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, "employee");
Put put = new Put(Bytes.toBytes("E12345"));
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("first_name"),
Bytes.toBytes("John"));
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("last_name"),
Bytes.toBytes("Smith"));
put.add(Bytes.toBytes("colfam1"), Bytes.toBytes("city"),
Bytes.toBytes("Sydney"));
table.put(put);В этом примере создается строка в таблице employee, добавляется семейство столбцов с тремя столбцами (first_name, last_name и city), значения данных сохраняются в создаваемых столбцах, а затем добавляется строка в таблицу HBase. В следующем фрагменте кода показан пример извлечения данных из HBase.
Configuration conf = HBaseConfiguration.create();
HTable table = new HTable(conf, " employee");
Get get = new Get(Bytes.toBytes("E12345"));
get.addColumn(Bytes.toBytes("colfam1"), Bytes.toBytes("first_name "));
Result result = table.get(get);
byte[] val = result.getValue(Bytes.toBytes("colfam1"),
Bytes.toBytes("first_name "));
System.out.println("Employee's first name is: " + Bytes.toString(val));Кроме того, HBase предоставляет обширный набор API-функций, таких как функция Delete, удаляющая значение атрибута любого ключа, функция DeleteColumn, удаляющая весь столбец, и функция DeleteFamily, удаляющая все семейство столбцов, включая все содержащиеся в нем столбцы. Кроме того, имеется набор пакетных функций Put, Get и Delete, и результирующие операции сканирования.
MongoDB
MongoDB - это распределенная, не имеющая схемы, ориентированная на документы база данных, созданная компанией 10gen. Она хранит двоичные JSON-документы (BSON), которые представляют JSON в двоичном коде, подобно объектам. BSON поддерживает вложенные структуры объектов со встроенными объектами и массивами. Подобно HBase, кластеры MongoDB и CouchDB могут устанавливаться и исполняться на любой IaaS-платформе провайдера, такой как IBM SmartCloud Enterprise.
Основой MongoDB является концепция документа (document), который представляется в виде упорядоченного набора ключей с ассоциированными значениями; коллекция (collection) - это группа таких документов. Если документ является MongoDB-аналогом строки в реляционной базе данных, то коллекция может считаться аналогом таблицы.
Коллекции не имеют схем. Это означает, что документы в рамках одной коллекции могут иметь любое количество различных форм. Например, оба следующих документа могли бы храниться в одной коллекции.
{"empID" : "E12345", "fname" : "John", "lname" : "Smit", "city" : "Sydney", "age": 32}
{"postID" : "P1", "postText" : "This is my blog post"}Обратите внимание, что предыдущие документы не только имеют разные структуры и типы своих значений, они также имеют совершенно разные ключи.
MongoDB группирует коллекции в базы данных. Один экземпляр MongoDB может поддерживать несколько баз данных, каждая из которых может рассматриваться как практически независимая. Функция insert добавляет документ к коллекции. В следующем фрагменте кода показан пример вставки документа с сообщением в коллекцию блога.
post = {"title" : "MongoDB Example", "content" : "Insertion Example ", "author" :
:"John Smith"}
db.blog.insert(post)После сохранения сообщения блога в базе данных его можно будет получить посредством вызова метода find для коллекции: db.blog.find("title" : "MongoDB Example").
Метод find возвращает все документы в коллекции, удовлетворяющие условиям фильтрации. Если вы хотите увидеть только один документ из коллекции, можно использовать метод findOne: db.blog.findOne().
Если вы хотите изменить сообщение, можно использовать метод update, который имеет два параметра (не менее):
- Критерии для отыскания документа, подлежащего обновлению.
- Новый документ.
В следующем фрагменте кода показан пример обновления содержимого сообщения в блоге:
post = {"content" : "Update Example"}
blog.update({{title : " MongoDB Example "}, post }Обратите внимание, что MongoDB гарантирует только "согласованность в конечном счете", поэтому процесс может прочитать старую версию документа, даже если другой процесс уже выполнил операции обновления этого документа. Кроме того, MongoDB не предоставляет механизма управления транзакциями, поэтому если процесс читает документ и записывает его измененную версию обратно в базу данных, то другой процесс имеет возможность записать новую версию этого документа в промежутке времени между операцией чтения и операцией записи первого процесса.
Метод remove навсегда удаляет документы из базы данных. Если этот метод был вызван без параметров, он удаляет все документы из коллекции. Если при вызове этого метода были заданы параметры, он удаляет только документы, соответствующие критерию удаления. В следующем фрагменте кода производится удаление примера сообщения в блоге. db.blog.remove({title : " MongoDB Example "}).
Можно создать индексы с помощью метода ensureIndex. В следующем фрагменте кода показан пример индексации сообщений в блоге с использованием информации из их заголовков. db.people.ensureIndex({"title " : 1}).
Кроме того, MongoDB поддерживает индексацию документов, состоящих из нескольких файлов. API-интерфейс продукта MongoDB является функционально насыщенным; он поддерживает различные функции пакетной обработки и агрегации. Продукт MongoDB реализован на языке C++; он предоставляет драйверы для многих языков программирования включая C, C#, C++, Erlang, Haskell, Java, JavaScript, Perl, PHP, Python, Ruby и Scala. Кроме того, предусмотрен интерфейс командной строки для JavaScript.
Проект Apache CouchDB - это еще один пример ориентированной на документы базы данных, которая подобна MongoDB с точки зрения модели данных и механизма управления данными. Он написан на языке Erlang, но на данный момент не является распределенной базой данных, хотя и может использоваться для приложений, написанных на JavaScript. Хранение и извлечение документов осуществляется как для JSON-объектов. CouchDB не имеет поддержки типов документов или какого-либо эквивалента таблиц, поэтому разработчик должен самостоятельно формировать различия документов по типам. Эта задача может быть решена посредством помещения атрибута type в каждый документ.
Интересная функция CouchDB - поддержка задания функций валидации. Например, при обновлении или при создании документа функции валидации вызываются для утверждения или проверки этих операций. Кроме того, продукт CouchDB может быть настроен на гарантированное поддержание сильной согласованности или согласованности в конечном счете.
Полезно знать: шардинг
Шард базы данных (shard) - это горизонтальный сегмент в базе данных или в поисковом механизме. Каждый отдельный раздел трактуется как шард. Строки таблицы базы данных хранятся раздельно, без разбиения на столбцы (т. е. без нормализации), а каждый раздел (шард) может быть размещен в отдельном сервисе базы данных или даже в отдельном физическом местоположении.
Преимущества шардинга.
- Сокращение количества строк в каждой таблице каждой базы данных.
- Уменьшение размера индекса обычно повышает производительность поиска.
- База данных может быть распределена по большому количеству машин (что также может повысить производительность).
- Хотя сегментация на шарды и не столь распространена, она может соответствовать реальным шаблонам доступа к данным (например, данные о европейских клиентах, к которым обращаются европейские подразделения продаж, данные об азиатских клиентах, к которым обращаются азиатские подразделения продаж и т.д.; каждому подразделению достаточно запросить лишь соответствующий ему шард, что существенно повышает эффективность).
На практике механизм шардинга оказывается довольно сложным. Эндрю Гловер (Andrew Glover), разработчик и технический писатель, предлагает хороший обзор технологии шардинга в статье на веб-сайте developerWorks.
Поддержка NoSQL продуктом DB2
При стремлении к эффективному управлению данными в облачной среде конечной целью является применение наиболее подходящей модели данных для каждой задачи управления данными. Поэтому имеет смысл упомянуть, что даже традиционные реляционные базы данных поддерживают различные версии NoSQL для достижения этой цели (я поговорю об этом в заключении статьи).
Например, IBM DB2 поддерживает хранилище NoSQL-графа с помощью API-интерфейса, который поддерживает множественные вызовы и программный стек NoSQL-решения. Граф хранит данные хранилища лишь в трех столбцах (т.н. triple - тройка), которые представляют данные как существительное/глагол/существительное. Простой запрос может совместно извлекать любые тройки данных, которые имеют совпадающие существительные. DB2 поддерживает функции, повышающие производительность хранилища графа, такие как возможность отображения троек графа на реляционные таблицы (с неограниченным количеством столбцов), сжатие данных, параллельное исполнение и выравнивание нагрузки.
Кроме того, благодаря технологии DB2 pureXML продукт DB2 поддерживает NoSQL-подобный тип базы данных, которая способна хранить XML-данные, что упрощает управление веб-данными в их нативном иерархическом формате. Для обработки XML-документов пользователи DB2 могут применять такие языки запросов, как XPath и XQuery. Эта модель данных удобна в сценариях применения, в которых подлежащая управлению информация непрерывно изменяется.
Заключение
На протяжении более чем четверти века системы управления реляционными базами данных были основной моделью в области управления базами данных. Эти системы предоставляют чрезвычайно привлекательный интерфейс для доступа к данным и манипулирования ими; они подтвердили свою успешность во многих приложениях для финансового сектора, для ведения бизнеса и для Интернета. После возникновения потребности в управлении данными в веб-масштабе эти системы стали страдать от определенных ограничений.
NoSQL-системы обладают следующими основными преимуществами в качестве альтернативной модели для управления базами данных.
- Эластичное масштабирование. На протяжении многих лет администраторы баз данных применяли подход на основе вертикального, а не горизонтального масштабирования; на фоне нынешнего повышения интенсивности транзакций и усиления потребностей в высокой доступности экономические преимущества горизонтального масштабирования становятся весьма привлекательными (особенно при использовании массовых аппаратных средств). NoSQL-системы разрабатываются с возможностью прозрачного расширения с целью использования таких преимуществ, как возможность добавления любого количества новых узлов.
- Уменьшение объема администрирования. В общем случае базы данных типа NoSQL проектируются для поддержки таких возможностей, как автоматическое исправление и более простая модель данных, которые снижают потребности в администрировании и настройке.
- Улучшение экономических показателей. Чтобы справиться с взрывным ростом объемов информации и транзакций, базы данных типа NoSQL обычно используют кластеры из недорогих массовых серверов.
- Гибкие модели данных. Базы данных типа NoSQL имеют более слабые ограничения на модели данных (или вообще не имеют ограничений), что позволяет более плавно вносить изменения в приложения и в схемы базы данных.
Прежде чем базы данных NoSQL станут привлекательными для основной массы корпоративных пользователей, им еще предстоит преодолеть множество препятствий.
- Модели программирования. Базы данных типа NoSQL предлагают не слишком много средств для запросов и оперативного анализа. Даже простой запрос требует значительной квалификации в области программирования. Отсутствие поддержки декларативного выражения важной операции
joinвсегда рассматривалось как одно из основных ограничений этих систем. - Поддержка транзакций. Управление транзакциями является одной из мощных функций реляционных СУБД. Нынешняя - ограниченная или вообще отсутствующая - поддержка понятия транзакции в NoSQL-системах управления базами данных рассматривается как препятствие для применения этих систем при реализации ответственных решений.
- Степень зрелости. Системы реляционных СУБД хорошо известны высокой стабильностью и обширной функциональностью. В отличие от них большинство NoSQL-альтернатив представлено "допроизводственными" версиями, многие ключевые функции которых недостаточно стабильны или пока не реализованы. В результате предприятия по-прежнему применяют эту "новую волну" средств управления данными с максимальной осторожностью.
- Поддержка. Предприятиям необходима уверенность, что в случае отказа системы они смогут получить своевременную и компетентную поддержку. Поставщики реляционных СУБД тратят много сил на то, чтобы обеспечить столь высокий уровень поддержки. Многие NoSQL-системы, напротив, являются проектами с открытым исходным кодом и не обеспечивают подобного уровня поддержки.
- Компетентность. Почти каждый разработчик NoSQL-системы действует в режиме обучения; не вызывает сомнения, что со временем эта ситуация изменится. Однако в настоящее время гораздо легче найти опытных программистов или администраторов по реляционным СУБД, чем специалистов по NoSQL.
По всей вероятности, дебаты между сторонниками NoSQL и реляционных СУБД никогда не дадут однозначного ответа. Наиболее вероятный наилучший ответ будет заключаться в том, что различные решения для управления данными будут сосуществовать в рамках одного приложения. Например, можно представить себе приложение, которое использует разные хранилища данных в разных целях.
- Реляционная СУБД типа SQL для хранения малых объемов данных высокой ценности, таких как профили пользователей и биллинговая информация.
- Хранилище пар "ключ/значение" для хранения больших объемов данных низкой ценности, таких как количество случаев выполнения той или иной функции, журналы и т. д.
- Сервис файлового хранилища для загруженных пользователями активов, таких как фотографии, аудиофайлы и большие двоичные файлы.
- Документная база данных для хранения таких документов приложения, как счета.