- Преимущество онтологий в формализации знаний о предметной области
В документе, описывающем концепцию Единой Интегрированной Системы, излагаются различные аспекты целевой программы Президиума РАН "Информатизация научных учреждений и Президиума РАН". Одной из основных задач ЕИС является информационное обеспечение научных исследований. "Единая информационная система РАН - это интегрированное информационное пространство распределенных и локальных цифровых (электронных) ресурсов организаций РАН и комплекс программно-технических средств, обеспечивающий использование этих ресурсов и полнофункциональное управление ими". Отсюда следует, что задача интеграции цифровых ресурсов ЕИС РАН в единое информационное пространство, - должна быть успешно решена, т.е. необходимо разработать "единый подход к информационному наполнению и интеграции существующих и вновь создаваемых ресурсов в ЕИС РАН... для обеспечения возможности эффективного управления ими со стороны системы".
Современные модели представления и интеграции информационных ресурсов активно развиваются и внедряются в практику. Важнейшим элементом современных информационных технологий являются онтологии, которые позволяют производить автоматизированную обработку семантики информации, предоставленной через Интернет, с целью её эффективного использования (представления, преобразования, поиска). Соответствующий принцип обработки данных Интернета базируется на представлении Интернета как глобальной базы знаний и ориентирован не на осмысление информации человеком, а на обеспечение семантической интероперабельности информационных ресурсов, т.е. автоматизированную интерпретацию и обработку информации.
Однако прежде, чем перейти к рассмотрению этих новых технологий, обратимся к опыту, накопленному в программистской практике, поскольку на сегодняшний день уже имеется много средств семантического описания данных, многие из которых считаются достаточно выразительными для задач семантического моделирования данных. В качестве примера можно привести модель описания ресурсов (Resource Definition Framework), диаграммы Сущность-Связь (Entity-Relationship model). Мы опишем, в чем заключаются преимущества онтологий перед другими механизмами описания семантики предметной области, например, RDFS, ER-диаграммами.
- Ограничения традиционных моделей данных
- Модель Entity Relationship
- Архитектура ANSI/SPARC
Для начала примем некоторые договоренности об использовании терминологии. Согласно М.Р. Когаловскому, под термином "модель данных" мы понимаем инструмент моделирования, т.е. является совокупностью понятий для описания данных, для описания структуры данных. "Модель предметной области" представляет собой визуальное представление сущностей предметной области и отношений между ними, т.е. спецификацию модели предметной области, и является результатом моделирования.
Первые модели данных предметной области описывались конструкторами типов таких языков программирования, как Алгол, а также в схемах баз данных. Позднее появились сложные модели данных, историю развития которых описал в своей работе Петер Чен, вместе с тем предложив новую модель данных, называемая моделью "сущность-связь" (Entity-Relationship model), основанную на некоторой важной семантической информации о реальном мире.
ER-модель явилась основой, из которой могут быть порождены три существующие модели данных: сетевой модели, реляционной модели и модели набора сущностей, представляя данные более строго и естественно и одновременно обеспечивая независимость данных от приложений (ER- модель основывается на теории множеств и реляционной теории). С тех пор было предложено множество расширений ER-схем, чтобы обеспечить более мощные средства выражения семантики данных: механизмы задания иерархии подклассов классов сущностей, некоторых семантических ограничений типа "часть-целое", реификаций как классов сущностей, благодаря которым можно было распознавать общие характеристики сущностей различных классов. Примеры таких моделей - "semantic data modeling", "extended ER modeling", "hyper-semantic data modeling", "OMT approach" и др.
Ограничения ER-модели и её расширений в том, что они, описывая семантику "сущностей", позволяют интерпретировать данные одним единственным способом.
Например, допустим, что модель данных Интегрированной Системы Информационных Ресурсов (ИСИР) РАН будет содержать тип ресурса "Научная организация" вместе с некоторыми атрибутами и соотношениями. Сущностями этого типа будут служить конкретные научные организации. С помощью механизма иерархии классов можно понять, к какому типу относится данный ресурс (к типу "Организация"), однако самому типу "Научная организация" в процессе моделирования данных обычно можно дать только одну интерпретацию. Поэтому, повторно использовать данное понятие "Научная организация" не удастся, т.к. этот термин в разных контекстах (т.е. при различных точках зрения видения предметной области) имеет разное значение. Например, с научной точки зрения нас будут интересовать такие аспекты, как направление научных исследований, список ведущих научных сотрудников и т.д. В административной структуре интересен управленческий состав, организационные вопросы. В плане внешних связей данной организации полезна информация о рейтинге и научном сотрудничестве, филиалах и т.д.
Можно с уверенностью сказать, что повторное использование знаний в различных контекстах не возможно без наличия механизмов, позволяющих фиксировать различное понимание этих знаний. Идея разработки такого механизма была представлена частично в ANSI/SPARC-архитектуре баз данных.
Эта архитектура включает три уровня:
- Логический уровень (называемый "концептуальной схемой*"), который является промежуточным уровнем и основой данной архитектуры.
- Внутреннее представление базы данных описывает способ, по которому концептуальная схема может быть реализована в терминах объектов физического уровня: файлов, индексов, хэш-таблиц и т.д.
- На верхнем уровне концептуальной модели можно определить множественное "внешнее представление". Оно будет состоять из выборок и комбинаций элементов концептуальной схемы и представлять видение схемы для каждого конкретного пользователя этого приложения. Например, база данных, содержащая административную информацию о сотрудниках организации, должна содержать два различных представления данных: для финансового отдела и для самих научных сотрудников.
Главное ограничение внешнего представления ANSI/SPARC заключается в том, что в логической модели архитектуры ANSI/SPARC должна содержаться вся имеющаяся в базе данных информация, однако новые данные, добавленные в представления верхнего уровня, нельзя перенести на логический (основной) уровень этой архитектуры. Другими словами, нет единого, унифицированного представления для всех представлений контекстов, которое было бы достаточным для любой возможной ситуации, поскольку число различных представлений контекстов практически неограниченно. Не существует также способа понять, применима ли какая-то конкретная часть знаний для другого контекста, и если неприменима, то почему.
- Модель RDFS и её применение в ИСИР
RDF Schema - это стандарт инициативы W3C для преставления онтологических знаний. RDF Schema специфицирует множество всевозможных допустимых схем данных. RDF модели предметных областей описываются посредством ресурсов, свойств и их значений. Ограничения RDFS в невозможности с его помощью выразить аксиоматические знания, т.е. задать аксиомы и правила вывода, построенные на аксиомах.
RDFS предоставляет хорошие базовые возможности для описания словарей типов предметных областей.
Однако расширение выразительных способностей инструмента RDFS возможно и чрезвычайно полезно. Механизм расширения внутренне присущ RDFS путем "уточнения" или дополнения базовых типов. Поэтому RDFS стал фундаментом для более богатых языков описания концепций предметных областей, называемых языками описания онтологий предметных областей, о которых пойдет речь позже.
- Понятие онтологии
Онтологии являются новыми интеллектуальными средствами для поиска ресурсов в сети Интернет, новыми методами представления и обработки знаний и запросов. Они способны точно и эффективно описывать семантику данных для некоторой предметной области и решать проблему несовместимости и противоречивости понятий. Онтологии обладают собственными средствами обработки (логического вывода), соответствующими задачам семантической обработки информации. Так, благодаря онтологиям, при обращении к поисковой системе пользователь будет иметь возможность получать в ответ ресурсы, семантически релевантные запросу (рис. 1).
Поэтому онтологии получили широкое распространение в решении проблем представления знаний и инженерии знаний, семантической интеграции информационных ресурсов, информационного поиска и т.д.
Известны несколько подходов к определению понятия онтологии, но общепринятого определения до сих пор нет, поскольку в зависимости от каждой конкретной задачи удобно интерпретировать этот термин по-разному: от неформальных определений до описаний онтологий в понятиях и конструкциях логики и математики. Мы будем понимать этот термин следующим образом:
Онтология - формальная спецификация разделяемой концептуализации, которая имеет место в некотором контексте предметной области. При этом под концептуализацией будем иметь ввиду, кроме сбора понятий, также всю информацию, касающуюся понятий - свойства, отношения, ограничения, аксиомы и утверждения о понятиях, необходимые для описания и решения задач в избранной предметной области.
Онтология предметной области определяет формальное приближение концептуализации. В онтологии зафиксирована та часть концептуализации, которая зависит от взгляда на мир применительно к конкретной области интересов.
Неформально онтология состоит из терминов и правил использования этих терминов, ограничивающих их значения в рамках конкретной области. На формальном же уровне, онтология это система, состоящая из набора понятий и набора утверждений об этих понятиях, на основе которых можно строить классы, объекты, отношения, функции и теории.
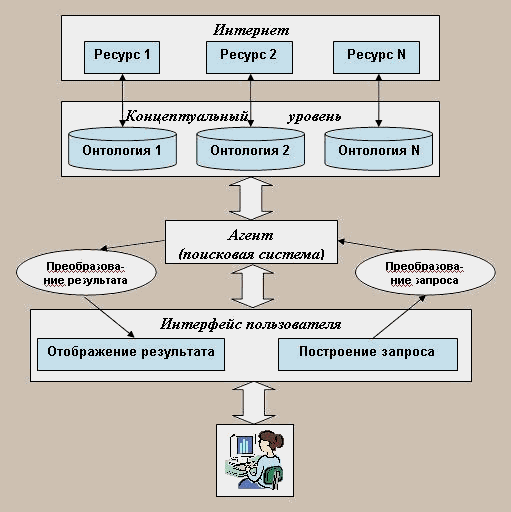
Рис. 1: Схема поиска на основе онтологий.
Поскольку в каждой области могут существовать различные понимания одних и тех же терминов, онтология определяет соглашение о значении терминов и является посредником между человеко- и машинно-ориентированным уровнем представления информации. Онтология существует в рамках договоренностей между членами сообщества, например, между пользователями некоторой информационной системы.
Концептуальное (или онтологическое) моделирование имеет дело с вопросом о том, как декларативным образом, допускающим повторное использование, описать предметную область, соответствующие словари типов, как ограничить использование этих данных, в предположении понимания того, что может быть выведено из этого описания.
Из данного определения также следует, что частными случаями онтологий являются простой словарь (например, Dublin Core), тезаурус (в котором ограничено число отношений между терминами) и т.д.
Онтологию можно применять в качестве компоненты баз знаний, схемы объектов в объектно-ориентированных системах, концептуальной схемы базы данных, структурированного глоссария взаимодействующих сообществ, словаря для связи между агентами, определения классов для программных систем.
Онтологии в том числе позволяют соответствующим программным средствам (интеллектуальным агентам) автоматически (без участия человека) определять смысл терминов использованных при описании ресурсов и сопоставлять его со смыслом поставленной задачи.
- Типы онтологий
Для онтологий характерны две особенности: они могут быть множественными (составными), в которых различаются представления контекста одного и того же домена, а могут идентифицировать абстрактные уровни онтологий (быть уровнем выше других онтологий). Что касается второго случая, то возможно идентифицировать несколько уровней абстракции, на каждом из которых могут быть определены онтологии. Например, в области каждой научной дисциплины можно определить онтологии, еще уровнем выше можно описать онтологии научных областей, находящихся на стыке отдельных научных дисциплин. Еще выше поставим онтологию научной дисциплины вообще. Следующим уровнем абстракции мы поставим общие категории структур знаний. Такого рода обобщение приводит нас к необходимости различать виды онтологий, чтобы организовывать их в библиотеки онтологий. Ниже приведена типология онтологий с примерами из области медицины.
1. Предметно-ориентированные (Domain-oriented)
- Специфичные для данного домена (Domain-specific)
- Медицина => кардиология => сердечная аритмия
- система управления светофорами
- Обобщение предметной области (Domain generalizations)
- компоненты, органы, документы
2. Ориентированные на прикладную задачу (Task-oriented)
- Специфичные для данной задачи (Task-specific)
- дизайн конфигурации, инструкция, планирование
- Обобщающие задачи (Task generalizations)
- решение проблем, напрмер, UPML
3. Базовая техническая онтология. (Basic technical ontology)
- тепло, энергия, сила
4. Общие онтологии (Generic ontologies)
- Категории верхнего уровня ("Top-level categories")
- Элементы и измерения (Units and dimensions)
Поясним четыре основных типа онтологий.
Предметно-ориентированные онтологии (Domain-oriented ontology)
Предметно-ориентированная онтология специфична для определенного типа артефактов. Примером может служить онтология для кораблей, нефтяных платформ, электрических цепей. Онтология предметной области обобщает понятия использующиеся в некоторых задачах домена, абстрагируясь от самих задач. Так онтология предметной области для конструирования кораблей должна быть независима от любых видов прикладных задач.
Онтологии, ориентированные на задачу (Task-oriented ontology).
Онтология, ориентированная на задачу - это обычно онтология, используемая приложением. Она содержит термины, которые мы используем при разработке системы прикладных программ выполняющих задачу. Она может отражать специфику приложения, а может также содержать некоторые общие характеристики. Часто нужно определить, как понять значение частей онтологии задачи для их повторного использования, и как построить часть онтологии задачи из существующей предметно-ориентированной онтологии.
Базовая техническая онтология. (Basic technical ontology)
Базовая техническая онтология описывает общие характеристики артефактов. Базовая техническая онтология обычно определяет знание, связанное c видами физических процессов: струя, тепло, энергия, мощность, электричество.
Обобщающие онтологии (Generic ontologies)
Обобщающая онтология описывает категории - понятия верхнего уровня. Это базовый механизм "разделения мира". Она связана с понятиями из онтологии (в философском смысле), например Аристотеля. Пример: такие понятия как физические, функциональные, поведенческие, отношение "часть-целое".
Ключевым моментом в проектировании онтологий является выбор соответствующего языка спецификации онтологий (Ontology specification language). Цель таких языков - предоставить возможность указывать дополнительную машинно-интерпретируемую семантику ресурсов, сделать машинное представление данных более похожим на положение вещей в реальном мире, существенно повысить выразительные возможности концептуального моделирования слабоструктурованных Web-данных.
Существуют традиционные языки спецификации онтологий (Ontolingua, CycL, языки, основанные на дескриптивных логиках, такие как LOOM, и языки, основанные на фреймах - OKBC, OCML, Flogic). Более поздние языки основанные на Web-стандартах, такие как XOL, SHOE или UPML, RDF(S), DAML, OIL, OWL созданы специально для обмена онтологиями через Web.
В целом, различие между традиционными и Web- языками спецификации онтологий заключается в выразительных возможностях описания предметной области и некоторых возможностях механизма логического вывода для этих языков. Типичные примитивы языков дополнительно включают:
- Конструкции для агрегирования, множественных иерархий классов, правил вывода и аксиом;
- Различные формы модуляризации для записи онтологий и взаимоотношений между ними;
- Возможность мета-описания онтологий. Это полезно при установлении отношений между различными видами онтологий.
Первыми предложениями по описанию онтологий на базе RDFS были DARPA DAML-ONT (DARPA Agent Markup Language) и European Commission OIL (Ontology Inference Layer). Эти стандарты спецификации и обмена онтологиями были разработаны для достижения наилучших результатов в поддержке процесса обмена знаниями и интеграции знаний. DAML обеспечивает примитивы для объявления пересечений, объединений, дополнений классов и т.д. OIL основан на description logics. Другое расширение RDFS - DRDFS. Также как OIL, он дает возможность для выражения классов и определения свойств, однако выразительная мощность языков DRDFS и OIL такова, что ни один из них не может быть рассмотрен как фрагмент другого.
На базе этих предложений DAML и OIL возникло совместное решение - DAML+OIL, которое послужило толчком для создания в рамках инициативы Semantic Web отдельной группы по пересмотру этого решения и стандартизации языка описания Web-онтологий (OWL - Web Ontology Language). Адаптация к Web систем логики и искусственного интеллекта составляет вершину "пирамиды Semantic Web", обеспечивая адекватный семантически поиск информации и машинную интерпретацию семантики.
OIL также можно рассматривать в сравнении с Ontolingua, разработанной в рамках инициативы On-To-Knowledge. По сравнению с Ontolingua, OIL менее выразителен, но все же позволяет делать логические выводы: поддержка вывода обеспечивается системой FaCT - классификатором, который работает на основе description logic.
Однако в целом можно сказать, что ориентированность языков описания онтологий на системы математической логики делает их слишком тяжеловесными для огромного количества приложений, которым достаточно простого языка описания словарей - RDFS. И это правильно, каждая ступень в пирамиде - это ступень, на которой многие приложения могут остановиться, согласно своим собственным требованиям к данным и их использованию.
- Место онтологий в архитектуре системы ЕИС
К настоящему времени в организациях РАН уже созданы значительные цифровые ресурсы. Это научные публикации, базы и банки данных в различных областях науки, алгоритмы и программы, структурные и кадровые сведения и т.д. Онтологии могут занять важное место среди средств интеграции, обеспечив семантическую интеграцию этих ресурсов.
Всякий ресурс, использующий услуги инфраструктуры ЕИС РАН, имеет метаданные - описание, представленное в электронной форме и доступное для автоматизированной обработки. Описание терминов, используемых в метаданных, в виде онтологий позволит повысить точность машинной обработки метаданных до семантического уровня.
Предоставляемые о накопленных ресурсах сведения должны быть унифицированными, непротиворечивыми, точными, подробными и т.д. Это требование ЕИС, характерное для современных интегрирующих систем, может быть удовлетворено применением подхода и технологии создания и использования онтологий.
Уже из разнообразия ресурсов видно, что формирование их метаданных потребует многих онтологий (схем) причем разного типа.
- Состав цифровых ресурсов
Обобщенная классификация цифровых ресурсов ЕИС РАН:
- научные информационные ресурсы (научные публикации ученых РАН, труды научных конференций; научные издания РАН; информация о научных проектах, конкурсах и грантах; информация о научных коллективах и их разработках; научная переписка; информация о материально-технической базе фундаментальных исследований РАН; экспериментальные данные);
- административные информационные ресурсы (информация о структуре РАН, о структуре её подразделений, адресно-справочные и контактные сведения; кадровая информация; нормативно-правовые документы; финансовые документы; хозяйственно-административные документы и переписка; внутренний документооборот);
- программные ресурсы (программные компоненты вычислительных комплексов РАН и отдельных учреждений РАН);
- алгоритмические ресурсы (экспертные системы; пакеты прикладных программ; имитационные модели).
В характеристике цифровых ресурсов РАН и финансовых или государственных корпораций существует ряд принципиальных отличий. Первое отличие заключается в том, что основная часть данных финансовых или государственных корпораций является литерной или вербальной информацией. А научная информация может быть литерной, вербальной и/или невербальной (математические и структурные химические формулы, биоинформационные последовательности, таблицы, схемы, чертежи, рисунки, карты, аудио и видео объекты и т.д.). Второе отличие заключается в том, что научная информация является, как правило, слабоструктурированной или неструктурированной.
- Текущее состояние информационных ресурсов РАН
Из характеристики состояния информационного пространства, используемого научными организациями РАН и административным аппаратом:
- Информационные ресурсы слабо систематизированы, существенно разрознены, как логически, так и физически.
- Научная информация слабо представлена для доступа по телекоммуникационным каналам, хотя в некоторых организациях РАН проведена работа по публикации в сети Интернет.
В большинстве случаев под публикацией в Интернет подразумевается наличие собственного Web-сайта организации РАН (отделения, института, библиотеки), представляющего собой набор статических HTML-страниц. При этом имеющиеся представления информации не только преимущественно статические, но и используют разные способы визуализации, обладают разнообразными интерфейсами, плохо структурированы, не имеют средств интеграции и поиска. Использование разных способов структурирования информации и, как следствие, разных систем навигации, ставит практически неразрешимые проблемы идентификации местоположения ресурсов и возможности распределенного поиска.
В редких случаях организациями используются специализированные Web-системы, более подготовленные с точки зрения задач распределенной среды. Это различные информационно-справочные, экспертные и другие системы, эксплуатируемые и вновь разрабатываемые в организациях РАН. Такие ресурсы содержат существенные объемы представляющей интерес информации в структурированном виде. Как правило, в них используются системы управления базами данных для представления и манипуляций с информацией, что позволяет сравнительно легко включать их в единое информационное пространство, в частности, обеспечивать высокую релевантность результатов поисковых запросов. Важнейшими представителями таких систем являются библиотечные и справочные системы, хранящие наукоемкую информацию - данные о публикациях, конференциях, проектах, структуре РАН, сотрудниках отдельных организаций, связях, совместных программах и т.п.
- Научная информация организаций РАН не имеет стандартизированного электронного представления, и, как следствие, отсутствует централизованная специализированная система поиска научной информации и доступа к ней.
- Отсутствуют средства интеграции информационных ресурсов различных отраслей науки.
- Алгоритмические ресурсы РАН, как правило, "привязаны" к локальным сетям организаций-разработчиков и практически недоступны для пользователей сторонних организаций и вычислительных сетей.
Практически отсутствуют электронные каталоги издательств РАН и электронные библиотеки электронных версий изданий, хотя авторы в основном предоставляют электронные варианты публикаций.
"Интеграция поиска"
Имеющиеся механизмы поиска на динамических сайтах, содержащих всю информацию в базах данных, неудовлетворительны и мало пригодны к интеграции, в частности, в связи с трудностями индексирования данных, отсутствия поддержки механизмов обмена метаданными, требованиями выполнения сложных процедур регистрации пользователей и т.п.
Частично созданы и продолжают развиваться в составе системы средства определения, формирования и трансформирования схем метаданных (онтологий), преобразования метаданных, описателей коллекций, поисковых индексов и запросов;
Онтологии являются важнейшим компонентом средств обеспечения семантической интероперабельности, извлечения метаданных и их интерпретации.
- Задачи ЕИС, решаемые с помощью онтологий
В ЕИС поставлена задача разработки единой корпоративной модели метаданных и реализация на основе этой модели глобальной поисковой системы - модель метаданных в настоящий момент представлена в виде онтологии нижнего уровня - RDFS-схемы.
"Системные функции информационно-управляющего ядра ЕИС РАН"
Перечислим те функции, в которых могут быть применены онтологии:
- Ведение и поддержка в актуальном состоянии метаданных системы - схема хранилища и описание сервисов в виде онтологий;
- Хранилище метаданных - схема хранилища в виде онтологии;
- Сбор и поддержка в актуальном состоянии данных о службах ЕИС РАН - данные о службах записываются с помощью терминов из опубликованных онтологий;
- Сбор и поддержка в актуальном состоянии метаданных цифровых ресурсов ЕИС РАН - сведения о ресурсах записываются с помощью терминов из опубликованных онтологий;
- Предоставление данных о зарегистрированных цифровых ресурсах и службах - сведения о ресурсах записываются с помощью терминов из опубликованных онтологий.
- Предоставление пользователям ЕИС РАН данных о зарегистрированных цифровых ресурсах и службах - сведения о ресурсах записываются с помощью терминов из опубликованных онтологий;
- Поиск по каталогу цифровых ресурсов и служб по данным о службах и по метаданным зарегистрированных ресурсов - каталог в виде онтологии;
- Предоставление интерфейсов для поиска и отображения данных цифровых ресурсов ЕИС РАН - данные о интерфейсах записываются с помощью терминов из опубликованных онтологий;
"Хранилище метаданных"
Хранилище метаданных обслуживает потребности по хранению данных служб информационно-управляющего ядра ЕИС РАН и, таким образом, само по себе является цифровым ресурсом ЕИС РАН. К функциям этого ресурса относится хранение и предоставление метаданных, собираемых службой каталога, ведение классификаторов и рубрикаторов ресурсов, ключевых слов и индексов, используемых службой поиска, списков пользователей и их атрибутов, управляемых службой безопасности. Этот ресурс представляет собой объектное хранилище данных, что обеспечивает возможности гибкого расширения состава хранимой информации и возможности эффективного масштабирования системы при расширении её состава.
Схема хранилища предоставляет собой онтологию (в настоящей момент на RDFS), часть которой (внешняя схема) публикуется в Web.
"Профиль ЕИС РАН"
К объектам, стандартизируемым профилем ЕИС РАН с помощью онтологий, могут быть отнесены: функциональные и эталонные информационные модели; форматы электронного обмена данными для различных областей науки (интерфейсы взаимодействия приложений); форматы метаданных; форматы представления данных; стандарты баз данных; стандарты геоинформационных данных; классификаторы и рубрикаторы.
- Пример онтологии из ЕИС
Онтология, описывающая структуру хранилища метаданных, представляет собой RDFS схему, описывающую взаимосвязь и атрибуты основных видов ресурсов ЕИС: организация, подразделение, персона, публикация, проект, награда, мероприятие, новость, сервис, Web-система. RDFS-cхема описывает объектно-ориентированную модель хранилища метаданных и является логической основой для объектно-ориентированного доступа к нему.
Таким образом, использование уже RDFS возможностей дает возможность создать объектно-ориентированную схему предметной области. Использование онтологических языков более высокого уровня даст возможность формализовать еще больше семантики предметной области.
Литература
- Концепция создания Единой информационной системы РАН (ЕИС РАН). Вторая редакция
- Christopher Welty. Towards a Semantics for the Web. Padova, Italy
- Когаловский М.Р. Абстракции и модели в системах баз данных // Журнал "СУБД", Издательский дом "Открытые системы", 4-5/1998.
- Петер Пин-Шен Чен. Модель "сущность-связь" - шаг к единому представлению о данных. 1986.
- I. Laresgoiti, A. Anjewierden, A. Bernaras, J. Corera, A. TH. Schreiber, B. J. Wielinga. Ontologies as Vehicles for Reuse: a mini-experiment. Amsterdam, The Netherlands
- Alexandre Delteil, Catherine Faron-Zucker, Rose Dieng. Extension of RDF(S) with Contextual and Definitional Knowledge. INRIA, ACACIA Project, 2004 route des Lucioles, BP 93,06902 Sophia Antipolis, France
- Бездушный А.А., Бездушный А.Н., Серебряков В.А. RDFS-система - практическое использование RDFS.
- Клещев А.С., Артемьева И.Л.. Математические модели онтологий предметных областей. Часть 1. Существующие подходы к определению понятия "онтология"
- Alexander S. Kleshchev, Irene L. Artemjeva. Mathematical Models Of Domain Ontologies. // Technical Report, Vladivostok 2000
- Guus Schreiber. Requirements for Ontology Specification. SWI, University of Amsterdam.
- Смирнов А.В., Пашкин М.П., Шилов Н.Г., Т.В. Левашова. Онтологии в системах искусственного интеллекта: способы построения и организации (часть 1) // "Новости искусственного интеллекта" № 1 (49) 2002 г.
- Oscar Corcho, Asunciуn Gуmez-Pйrez. A Roadmap to Ontology Specification Languages. Madrid. Spain
- OIL in a nutshell.