
Первая часть статьи "Интервалы и счетчики", открыла серию материалов о временных интервалах и различных связанных с ними счетчиках. Примеры приведены в таблице Sessions, содержащей информацию о сеансах, сопоставленных приложениям. Используйте код в листинге 1, чтобы создать таблицу Sessions и заполнить ее малым набором тестовых данных для проверки корректности решения. С помощью исходного текста в листинге 2 строится вспомогательная функция GetNums, которая затем используется для заполнения таблицы Sessions большим набором тестовых данных для проверки производительности.
Первая из рассмотренных в предыдущей статье задач предложена Адамом Махаником. В ней требуется выполнить подсчет перекрывающихся дискретных интервалов. Я представил два решения. В первом из них используется агрегат для окна и функции Offset. Обработка большого набора данных на моем компьютере заняла 37 секунд. Во втором решении использовалось ранжирование окна и функция Offset; для его завершения потребовалось 22 секунды. В этой статье мы рассмотрим пути дальнейшего улучшения второго решения, а также вариант задачи с упаковкой смежных интервалов в одном подсчете.
Совершенствование решения для подсчета при дискретных интервалах
Прежде чем рассмотреть способы улучшения второго решения, представленного в первой части статьи, вспомним, каким было это решение и как выглядел его план. Исходный текст решения приведен в листинге 3, а на рисунке 1 показан его план (с использованием SQL Sentry Plan Explorer).
 |
| Рисунок 1. План для запроса в листинге 3 |
Достоинство этого плана заключается в том, что оптимизатору не требуется явных операций сортировки. Оптимизатор все время полагается исключительно на упорядоченные просмотры индексов indexes idx_start и idx_end при вычислении всех оконных функций, в том числе основанных на объединенном наборе событий. Однако этот план лишен параллелизма. Благодаря параллелизму можно существенно снизить время выполнения, особенно при больших наборах данных.
Я позаимствовал у Адама Механика прием, с помощью которого можно улучшить параллельную обработку в случаях, когда алгоритм запросов должен независимо обработать каждую группу строк. В нашем примере требуется независимо обработать каждую группу строк, связанную с одним приложением. Этот метод заключается в запросах к таблице, содержащей отдельные группы, и использовании оператора CROSS APPLY для применения алгоритма исходного запроса к группам. При наличии достаточного количества данных SQL Server обычно использует параллельный план и распределяет работу между различными потоками. Данные каждой группы обрабатываются одним потоком, и несколько групп могут параллельно обрабатываться несколькими потоками. При таком подходе работа обычно хорошо распределяется между потоками. Часто он бывает предпочтителен по сравнению с параллельными планами (когда они выбираются по умолчанию) для обработки оконных функций. Но в нашем случае оптимизатор даже не выбрал параллельный план для исходного запроса в листинге 3.
Чтобы использовать подход APPLY, следует создать встроенную табличную функцию, которая работает с интервалами только одного приложения. Это означает, что функция примет приложение как входной параметр (@app). Запрос, возвращенный функцией, основан на логике запроса в листинге 3, но необходимо внести ряд изменений:
- удалить столбец app из всех предложений SELECT;
- удалить PARTITION BY app из всех оконных функций;
- добавить фильтр WHERE app = @app к запросам в CTE C1. Эти запросы формируют хронологическую последовательность событий.
Используйте исходный текст в листинге 4, чтобы создать функцию IntervalCounts, которая реализует такую встроенную табличную функцию.
Затем примените функцию к каждому приложению из таблицы Apps с помощью следующего запроса:
SELECT A.app, IC.* FROM dbo.Apps AS A CROSS APPLY dbo.IntervalCounts(A.app) AS IC;
На рисунке 2 показан план для данного запроса. В этом плане видна эффективная организация параллелизма. Запрос был выполнен за 10 секунд на моем компьютере - вдвое быстрее, чем исходный запрос.
 |
| Рисунок 2. План для решения с использованием APPLY и функции в листинге 4 |
Подсчет в случае дискретных интервалов с упаковкой
В этом разделе рассматривается задача, которая представляет собой разновидность предыдущей задачи. Как и прежде, нужно выполнить подсчет перекрывающихся дискретных интервалов, но также необходимо упаковать смежные дискретные интервалы в один подсчет. На рисунке 3 показано графическое представление задачи.
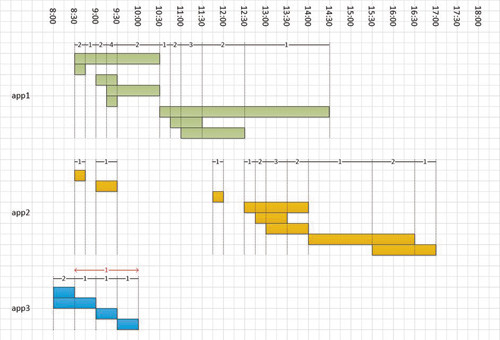 |
| Рисунок 3. Подсчет в случае дискретных интервалов с?упаковкой |
Обратите внимание на интервалы для app3. В исходной задаче требовалось сформировать четыре дискретных интервала. В новой задаче нужно упаковать три смежных интервала в один подсчет, что приводит к двум дискретным интервалам: один начинается в 8:00 и завершается в 8:30 с подсчетом 2; другой начинается в 8:30 и завершается в 10:00 с подсчетом 1. На рисунке 4 показан желаемый результат для малого набора тестовых данных (для простоты отсортированный по приложению и времени начала, хотя от решения не требуется возвращать сортированный результат).
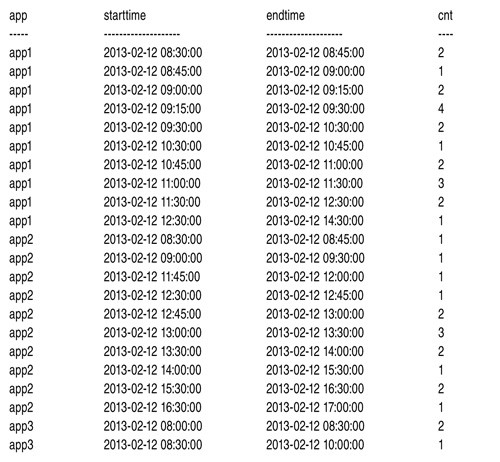 |
| Рисунок 4. Желаемый результат запроса с показом подсчетов при дискретных интервалах с?упаковкой |
В листинге 5 показано полное решение, в том числе алгоритм упаковки. Я объясню его по частям. Исходный текст в обобщенных табличных выражениях C1 и C2 похож на исходный текст в решении без упаковки. Этот фрагмент формирует хронологическую последовательность событий, а также порядковый номер событий начала (s), порядковый номер событий завершения (e) и объединенный порядковый номер всех событий se). Затем следующий запрос используется для определения обобщенного табличного выражения C3:
SELECT *, (COALESCE( s - (se - s), - count of active intervals after start event (se - e) - e) - count of active intervals after end event ) AS cnt, LEAD(ts) OVER(PARTITION BY app ORDER BY ts, type, keycol) AS nextts FROM C2
Запрос ведет подсчет активных интервалов после начальных событий (s - (se - s)) и подсчет после событий завершения ((se - e) - e). Затем функция COALESCE возвращает то из двух значений, которое не равно NULL. Результат этого вычисления (с именем cnt) - просто подсчет активных интервалов после текущего события.
В запросе также используется функция LEAD, чтобы возвратить метку времени (ts) следующего события; полученный в результате столбец имеет имя nextts. На рисунке 5 показан выход этого запроса для приложения app3.
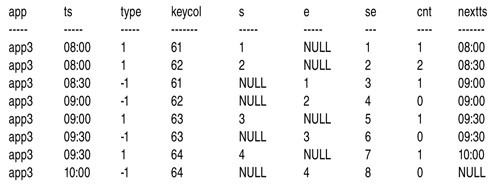 |
| Рисунок 5. Результат запроса в CTE C3 для app3 |
Затем следующий запрос определяет CTE C4:
SELECT app, ts AS starttime, nextts AS endtime, cnt, CASE WHEN cnt = LAG(cnt) OVER(PARTITION BY app ORDER BY ts) THEN NULL ELSE 1 END isstart FROM C3 WHERE ts <> nextts AND nextts IS NOT NULL
Запрос фильтрует только события, в которых текущее значение ts отличается от nextts, так как это события, представляющие интересующие нас дискретные интервалы. Упорядочение, используемое в оконных функциях, гарантирует, что в случае нескольких одновременных событий начала или завершения последнее событие перед изменением временной метки будет иметь подсчет активных интервалов после того, как все применены. Этот подсчет отражает количество перекрывающихся сеансов во время дискретного интервала.
Запрос также фильтрует только события, в которых значение nextts отличается от NULL. Самое последнее событие завершения будет иметь NULL в столбце nextts, и оно нас не интересует.
В запросе используется выражение CASE с функцией LAG, чтобы проверить, равен ли счетчик текущего интервала счетчику предыдущего смежного интервала. Если они одинаковы, результат вычисления равен 1; в противном случае возвращается NULL. Имя результирующего столбца - isstart. Если текущий интервал начинает новую упакованную группу, даже если группа состоит только из самого интервала, флаг имеет значение 1. Если интервал продолжает упакованную группу, то значение флага flag - NULL. На рисунке 6 показан выход этого запроса для app3.
 |
| Рисунок 6. Результат запроса в CTE C4 для app3 |
Следующий шаг - вычислить идентификатор для каждого упакованного интервала. Это делается с помощью запроса, определяющего CTE C5:
SELECT *, COUNT(isstart) OVER(PARTITION BY app ORDER BY starttime ROWS UNBOUNDED PRECEDING) AS grp FROM C4
Идентификатор упакованного интервала просто вычисляется как текущий подсчет флага isstart до текущего интервала. На рисунке 7 показан выход этого запроса, здесь можно увидеть два идентифицированных упакованных интервала, отмеченных как grp 1 и grp 2.
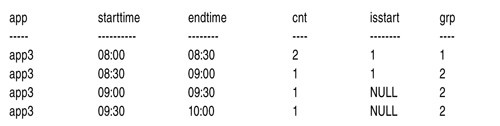 |
| Рисунок 7. Результат запроса в CTE C5 для app3 |
Наконец, внешний запрос к C5 удаляет все интервалы со значением подсчета, равным 0, и группирует оставшиеся строки по приложению и идентификатору упакованного интервала, возвращая времена начала и завершения для каждого упакованного интервала. Обратите внимание, что очень важно не удалить интервалы со значением подсчета, равным 0, пока вычисляется флаг isstart. Это может привести к тому, что будут упакованы вместе несмежные интервалы с одинаковым подсчетом. После того, как вычислен флаг isstart, не интересующие вас интервалы можно спокойно удалить. Выход этого запроса представляет собой желаемый результат, показанный на рисунке 4.
На рисунке 8 показан план для запроса в листинге 5, для выполнения которого на моем компьютере потребовалось 88 секунд.
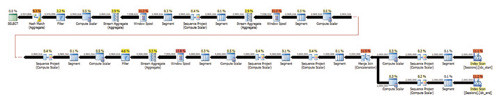 |
| Рисунок 8. План запроса в листинге 5 |
Чтобы повысить производительность этого решения, можно использовать метод APPLY, как при увеличении производительности решения для предыдущей задачи. Используйте программный код в листинге 6, чтобы создать встроенную функцию IntervalCounts, реализуя ту же логику, что и в запросе в листинге 5, но для единственного входного приложения (@app). Затем задействуйте следующий программный код, чтобы применить функцию к каждому приложению из таблицы Apps:
SELECT A.app, IC.* FROM dbo.Apps AS A CROSS APPLY dbo.IntervalCounts(A.app) AS IC;
При запуске этого программного кода на моем компьютере с восемью логическими процессорами, к сожалению, у меня не было параллельного плана. У меня был последовательный план, показанный на рисунке 9, для выполнения которого потребовалось 54 секунды.
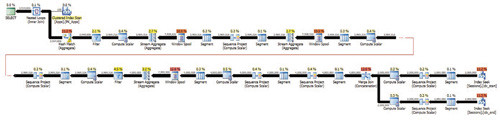 |
| Рисунок 9. Последовательный план решения с APPLY для функции в листинге 6 |
Любопытно, что быстродействие этого решения все же выше, чем решения в листинге 5, хотя параллелизм не использовался. Но скорость должна существенно увеличиться, если удастся составить параллельный план. Было бы хорошо, если бы язык T-SQL поддерживал указание MINDOP, но это не так. Однако проблему можно решить, добавив искусственное перекрестное объединение с табличным выражением, которое возвращает только одну строку; результат не изменится, но оптимизатор обнаруживает, например, 100 строк. Сделать это можно следующим образом:
DECLARE @n AS BIGINT = 1; SELECT A.app, IC.* FROM dbo.Apps AS A CROSS APPLY dbo.IntervalCounts(A.app) AS IC CROSS JOIN (SELECT TOP (@n) * FROM dbo.Apps) AS B OPTION (OPTIMIZE FOR (@n = 100));
Этого достаточно, чтобы оптимизатор выбрал параллельный план, как показано на рисунке 10. На этот раз выполнение программного кода заняло 24 секунды.
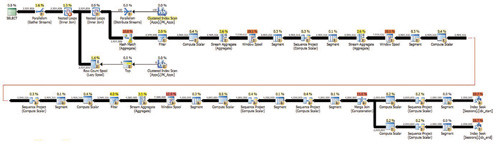 |
| Рисунок 10. Параллельный план решения с APPLY для функции в листинге 6 |
Много интересного впереди
С интервалами и счетчиками связано много задач. В данной статье мы рассмотрели две важные темы: усовершенствованное решение, использующее оператор APPLY для подсчетов при дискретных интервалах, и счетчики при дискретных интервалах с использованием алгоритма упаковки. В следующей статье речь пойдет о дополнительных задачах, в которых задействованы интервалы и счетчики.
Листинг 1. Код DDL для создания таблицы Sessions и ее заполнения
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.Sessions', N'U') IS NOT NULL DROP TABLE dbo.Sessions; IF OBJECT_ID(N'dbo.Apps', N'U') IS NOT NULL DROP TABLE dbo.Apps; CREATE TABLE dbo.Apps ( app VARCHAR(10) NOT NULL, CONSTRAINT PK_Apps PRIMARY KEY(app) ); CREATE TABLE dbo.Sessions ( keycol INT NOT NULL, app VARCHAR(10) NOT NULL, starttime DATETIME2(0) NOT NULL, endtime DATETIME2(0) NOT NULL, CONSTRAINT PK_Sessions PRIMARY KEY(keycol), CONSTRAINT CHK_Sessions_et_st CHECK(endtime > starttime) ); CREATE UNIQUE INDEX idx_start ON dbo.Sessions(app, starttime, keycol); CREATE UNIQUE INDEX idx_end ON dbo.Sessions(app, endtime, keycol); - code to fill Sessions with small set of sample data TRUNCATE TABLE dbo.Sessions; TRUNCATE TABLE dbo.Apps; INSERT INTO dbo.Apps(app) VALUES('app1'),('app2'),('app3'); INSERT INTO dbo.Sessions(keycol, app, starttime, endtime) VALUES (2, 'app1', '20130212 08:30:00', '20130212 10:30:00'), (3, 'app1', '20130212 08:30:00', '20130212 08:45:00'), (5, 'app1', '20130212 09:00:00', '20130212 09:30:00'), (7, 'app1', '20130212 09:15:00', '20130212 10:30:00'), (11, 'app1', '20130212 09:15:00', '20130212 09:30:00'), (13, 'app1', '20130212 10:30:00', '20130212 14:30:00'), (17, 'app1', '20130212 10:45:00', '20130212 11:30:00'), (19, 'app1', '20130212 11:00:00', '20130212 12:30:00'), (23, 'app2', '20130212 08:30:00', '20130212 08:45:00'), (29, 'app2', '20130212 09:00:00', '20130212 09:30:00'), (31, 'app2', '20130212 11:45:00', '20130212 12:00:00'), (37, 'app2', '20130212 12:30:00', '20130212 14:00:00'), (41, 'app2', '20130212 12:45:00', '20130212 13:30:00'), (43, 'app2', '20130212 13:00:00', '20130212 14:00:00'), (47, 'app2', '20130212 14:00:00', '20130212 16:30:00'), (53, 'app2', '20130212 15:30:00', '20130212 17:00:00'), (61, 'app3', '20130212 08:00:00', '20130212 08:30:00'), (62, 'app3', '20130212 08:00:00', '20130212 09:00:00'), (63, 'app3', '20130212 09:00:00', '20130212 09:30:00'), (64, 'app3', '20130212 09:30:00', '20130212 10:00:00');Листинг 2. Вспомогательная функция GetNums для большого набора данных
IF OBJECT_ID(N'dbo.GetNums', N'IF') IS NOT NULL DROP FUNCTION dbo.GetNums; GO CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN WITH L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)), L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B), L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B), L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B), L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B), L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B), Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L5) SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n FROM Nums ORDER BY rownum; GO - Code to fill Sessions with large set of sample data TRUNCATE TABLE dbo.Sessions; TRUNCATE TABLE dbo.Apps; DECLARE @numrows AS INT = 2000000, - total number of rows @numapps AS INT = 100; - number of applications INSERT INTO dbo.Apps WITH(TABLOCK) (app) SELECT 'app' + CAST(n AS VARCHAR(10)) AS app FROM dbo.GetNums(1, @numapps) AS Nums; INSERT INTO dbo.Sessions WITH(TABLOCK) (keycol, app, starttime, endtime) SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS keycol, D.*, DATEADD( second, 1 + ABS(CHECKSUM(NEWID())) % (20*60), starttime) AS endtime FROM ( SELECT 'app' + CAST(1 + ABS(CHECKSUM(NEWID())) % @numapps AS VARCHAR(10)) AS app, DATEADD( second, 1 + ABS(CHECKSUM(NEWID())) % (30*24*60*60), '20130101') AS starttime FROM dbo.GetNums(1, @numrows) AS Nums ) AS D;