Азарова И.В., Синопальникова А.А., Яворская М.В.
(Кафедра математической лингвистики СПбГУ)
Настоящий доклад посвящен уточнению методики построения RussNet, wordnet-тезауруса для русского языка, разрабатываемого сотрудниками кафедры математической лингвистики Санкт-Петербургского государственного университета.
В первой части доклада приводится перечень принципов, которые были использованы при построении wordnet-тезаурусов в широко известных проектах Принстонского WordNet, EuroWordNet и BalkaNet. Приводятся результаты апробации данных методик на материале русского языка в рамках проекта RussNet. Полученные данные имеют не только частное практическое значение при построении компьютерного тезауруса русского языка, но и общетеоретическое значение, поскольку показывают, как извлекать релевантную информацию из имеющиеся лингвистических ресурсов: толковых, идеографических и семантических словарей русского языка.
Во второй части доклада приводится схема использования лингвистических источников разного типа: результатов анализа корпуса текстов, дефиниций толковых словарей, данных ассоциативных словарей и частотных распределений лексем при построении тезауруса RussNet. Предлагаемая схема позволяет адекватно отобразить специфические для лексической системы русского языка связи лексикализованных понятий и минимизировать субъективность представления данных, т. е. верифицировать результаты проекта.
В докладе обсуждается методика присоединения RussNet к имеющимся системам национальных тезаурусов типа EuroWordNet и BalkaNet посредством связей с межъязыковым перечнем связующих концептов (ILI).
^
Guidelines for RussNet structuring
Azarova I. V., Sinopalnikova A. A., Yavorskaya M. V.
(Department of Applied Linguistics, Saint-Petersburg University, Russia)
The present paper describes methods of constructing RussNet - a wordnet-like thesaurus for the Russian language. The first part of the paper deals with the standard wordnet techniques developed in the frame of Princeton WordNet, EuroWordNet and BalkaNet projects, and their adjustment for the Russian data. The obtained results have their practical value for the RussNet project, nonetheless, they are of theoretical importance, as they allow us to estimate the existing lexical Russian resources, such as explanatory dictionaries, thesauri and semantic lexicons from the viewpoint of lexical knowledge extraction and representation. In the second part of the paper we present a general strategy of RussNet construction using various lexical resources for Russian, such as text corpora, frequency lists, conventional dictionary definitions and word association norms. The presented methods enable us to adequately represent the specific features of the Russian lexicon, and to minimize the subjectivity of lexical data differentiation, thus to make them open for verification. Furthermore, we discuss methods of linking RussNet structures to existing multilingual wordnet databases of EuroWodNet and BalkaNet projects by means of Interlingual Index (ILI).
Введение
Основной целью проекта RussNet является построение компьютерного словаря типа WordNet для лексики русского языка. В современной лингвистике термин wordnet (ставший нарицательным) употребляется применительно к особой разновидности лингвистических ресурсов (лексиконов, лексико-семантических баз данных, компьютерных тезаурусов), построенных по модели, которая была разработана в Принстонском Университете в 1985 г.
Основными структурными единицами словарей типа WordNet являются синонимический ряд (иначе, синсет) и слово. Слова (точнее лексико-семантические варианты слов) и синсеты связаны между собой различными семантическими отношениями:
на лексико-семантические вариантах слов задаются синонимические отношения,
на синсетах - различные парадигматические и синтагматические отношения такие, как антонимия, гипонимия (т. е. родовидовые отношения), меронимия (отношения типа часть-целое) и различные виды лексического вывода - каузация, пресуппозиция, и др.
Несмотря на то, что существует определенная традиция и стандарты построения словарей типа WN, зачастую мы не можем заимствовать опыт наших коллег, и напрямую воспроизводить их методику. Это обусловлено, во-первых, спецификой русского языка (синтетического, флективного языка с развитой морфологической системой), во-вторых, отсутствием некоторых источников лексической информации (например, больших корпусов текстов), служащих отправной точкой исследования, в-третьих, недостатками и недочетами стандартных методик, ставшими очевидными при практическом использовании wordnet-тезаурусов. Так, например, сейчас все чаще говорят о том, что в Принстонском WN - самом первом wordnet - приводится гораздо больше значений слов, чем реально различается носителями языка.
^ Типы источников и их применение в различных wordnet-проектах
Необходимость представлять в рамках wordnet разнообразные данные о лексических единицах в отдельности и лексической системе языка в целом требует привлечения различных источников лингвистической информации. Условно их можно разделить на две большие группы.
^ Источники первого порядка (корпусы текстов, результаты психолингвистических экспериментов) содержат эмпирические данные о реальном функционировании слов в языке (речи). Затрудняет использование этих источников то, что лексико-семантическая информация в них представлена в неявной форме, и ее извлечение требует применения специальных процедур и средств.
^ Источники второго порядка (разного рода лексикографические источники: словари, тезаурусы и т.п.) строятся на основе источников первого порядка с привлечением интуитивных знаний, интроспекции экспертов-лингвистов. Они предоставляют информацию в эксплицитной форме, что упрощает процесс ее извлечения. Однако зачастую составители словарей придерживаются иных установок, действуют в рамках различных концепций, что заставляет прибегать к дополнительной проверке или уточнению данных1.
Несмотря на существование общих принципов построения wordnet-тезаурусов, в зависимости от установки разработчиков и того, входит ли тезаурус в объединенную систему типа EuroWordNet или BalkaNet, набор источников и методики их использования существенно варьируются в рамках различных проектов. Так например, в рамках Принстонского WordNet на первом этапе работы использовались источники первого порядка, а именно результаты психолингвистических экспериментов, в дальнейшем методика была расширена за счет применения контекстного и дефиниционного анализа. С возникновением проекта EuroWordNet особую роль стали играть корпусы текстов как наиболее достоверные источники лингвистической информации, и методы их анализа, кроме того были разработаны процедуры автоматической обработки электронных толковых словарей, тезаурусов и онтологий.
Таким образом, на сегодняшний день к стандартным методам построении национальных wordnet-тезаурусов относятся дефиниционный, контекстный и словообразовательный методы анализа значений. В рамках Принстонского WordNet также учитываются психолингвистические данные, полученные при проведении собственных экспериментов или представленные в списках ассоциативных норм английского языка. Каждый из перечисленных методов имеет определенные рамки и ограничения. В частности, в процессе дефиниционного анализа предполагается обращение к традиционным толковым словарям, которые были разработаны для иных целей и в рамках совершенно иной парадигмы. Об этом свидетельствует и структура словарной статьи, в которой выделение значений и оттенков значений, порядок упорядочения значений в словарной статье, выделение первого или основного значения слова носит в большой степени субъективный характер и меняется от словаря к словарю. То, что статья толкового словаря является вариантом разметки структуры значений слова и объективно отражает в некоторой степени функционирование слова в языке, безусловно. Однако, какова степень огрубления или, наоборот, чрезмерного подразделения значений, их иерархизации, остается непонятным, часто обусловлено составом картотеки примеров и установками группы лексикографов.
Среди базовых принципов построения wordnet-тезауруса в рамках Принстонского WordNet был сформулирован принцип, по которому перечисление значений слова должно соответствовать частотному распределению значений в текстах, то есть первым должно являться значение, наиболее часто встречающееся в текстах. Этот принцип не всегда выполнялся в wordnet-проектах в силу сложности его реализации. Во-первых, следует сформулировать временную и тематическую перспективу текстов. Во-вторых, разметка значений в корпусах трудоемка, нет готовых корпусов с размеченными значениями, следовательно, проводить такую разметку практически невозможно. В-третьих, словарные картотеки зачастую задают неравноценное представительство для разных значений: количество частых значений уменьшено в силу их обычности, "тривиальности", в то время как редкие значения, возможно окказионально встретившиеся, включаются наряду с узуальными, утвердившимися в языке. Все эти факторы, на наш взгляд, значимы, их необходимо учесть при построении компьютерного тезауруса, однако следует принять четкие решения по каждому пункту, даже если это идет в разрез с традиционными лексикографическими принципами.
^ Типы источников и методы их применение в проекте RussNet
RussNet является тезаурусом типа WordNet для русского языка, который разрабатывается сотрудниками кафедры математической лингвистики Санкт-Петербургского государственного университета. Основные принципы построения компьютерного словаря представлены на сайте филологического факультета СПбГУ2 и в ряде статей (Азарова и др. 2003; Материалы к компьютерному тезаурусу… 2002; Azarova et al. 2002).
В рамках проекта RussNet было принято решение о построении ядра компьютерного словаря на базе корпуса современных текстов. Этот период, на наш взгляд, начинается с середины 80-х годов (конца "советской эпохи") до настоящего времени. И хотя, наверно, и этот период имеет внутреннюю неоднородность, но ею можно пренебречь. В отношении тематического распределения текстов была выбрана достаточно стандартная схема преобладания газетных текстов (40%) как жанра, наиболее быстро откликающегося на изменения в языке, достаточно экспрессивного и вариативного; большой доли (30%) научно-популярных текстов как экспрессивно нейтральных и описывающих реалии не только обыденной жизни, но и других сфер; небольшая часть (20%) отрывков из художественной литературы, причем важным является отсутствие произведений, взятых целиком, а также больших фрагментов текстов (свыше 5 тысяч словоупотреблений), которые могли бы создавать идиолектные "флуктуации" употребления значений слов в корпусе; небольшая часть (10%) текстов законов, договоров, инструкций и проч., обеспечивающая конструкциями современных клише делового употребления слов.
Имеющийся корпус текстов, состоящий из 21 миллиона словоупотреблений, используется для отбора единиц, которые соответствуют ядру общеупотребительной лексики русского языка. Предполагается, что эти слова задают верхние уровни гипонимической иерархии и вершины деревьев в RussNet. Первоначально были отобраны слова с частотой более 120 вхождений на 1 млн. словоупотреблений (Vossen, 1998). В их число входят около 500 существительных, 200 глаголов, 200 прилагательных, и 100 наречий. Полученную совокупность была дополнена словами, соответствующими так называемому "ядру языкового сознания русских" (Уфимцева, 2002), т. е. словами, появляющимися в ответах испытуемых при ассоциативном эксперименте наиболее часто, и следовательно, связанными с наибольшим количеством других слов (более 100 обратных ассоциаций), например, человек, дом, жизнь, вода, день, лес, работа, книга, стол, город, друг, любовь, радость; есть, идти, думать, жить, большой, красивый, хороший; плохо, быстро, много и др .
Разбивая на классы полученную совокупность слов, мы получаем представление о количестве родовидовых деревьев в RussNet, однако выполнение этой задачи осложняется тем, что наиболее частотные слова русского языка являются и наиболее многозначными. Поэтому далее необходимо выделить наиболее употребительные значения этих слов. Для этой цели нами используется корпус, из которого при помощи программы Бонито3, разработанной сотрудниками Университета им. Масарика, извлекаются контексты употребления рассматриваемых лексем. Менеджер текстов Бонито позволяет осуществлять поиск контекстов для отдельной словоформы, ряда словоформ или лексемы целиком, сортировать контексты употребления относительно левой или правой частей контекста, создавать частотные словари и извлекать статистические характеристики совокупности контекстов.
Набор извлеченных контекстов для каждой лексемы размечается относительно схемы значений, представленных в толковом словаре (например, МАС). Нами были проведены исследования разметки полного набора контекстов и его подмножеств с тем, чтобы выяснить, насколько четко сохраняется схема распределения частотности значений лексемы. Опытным путем было установлено, что выборочная разметка случайным образом взятых 100-150 контекстов из разных произведений дает ту же схему распределения контекстов, что и полная совокупность, включающая 1500-2000 контекстов. Доля контекстов, являющихся реализацией наиболее частотного значения, колебалась не более, чем в интервале ±1%, при этом соотношение долей контекстов с наиболее частым значением и следующим за ним по частотности значением регулярно различались на 50%. Таким образом, при иерархизации значений по частотности достаточно разметки части контекстов, выбранных случайным образом.
Анализ контекстов позволяет также выявить набор значений, которые следует представлять в компьютерном тезаурусе. В частности, единичные случаи реализации значений считаются окказиональными. Для разделения значений на окказиональные и узуальные вводится пороговое значение (1%) от общего числа контекстов, которое должна составлять доля контекстов, реализующих значение в корпусе, для включения его в структуру лексикализованных понятий компьютерного тезауруса. Для разграничения значений также используется параметр частотного представительства в совокупности контекстов, помимо которого используется еще рамка валентностей. При этом считается, что отдельное значение должно иметь отдельную схему валентностей или сочетаемости с контекстом.
Сочетаемость предикативных и признаковых слов определяется набором обязательных и факультативных активных валентностей, причем обязательной считается валентность, реализующаяся с частотой более 70-85% в контекстах рассматриваемого слова в корпусе современных текстов, а факультативной - та, которая реализуется с частотой более 15-30%. Окказиональные валентности представлены, как правило, менее, чем в 15% контекстов рассматриваемого слова. Выделение валентностей осуществляется на основе функционально-синтаксических позиций при слове, которые фиксируются тремя параметрами: (1) функцией, определяемой вопросом, на который отвечает заполняющая форма; (2) формой поверхностного выражения валентности; (3) семантическим типом слова, занимающего валентную позицию. Например, для глагола направится в нашем корпусе из 21 млн. словоупотреблений было найдено 358 контекстов употреблений в значении "двинуться в каком-л направлении", контексты составили практически 100% общего числа контекстов употребления данного слова, поскольку в другом значении это слово было употреблено лишь один раз. Употребление в этом значении предполагает 2 обязательные валентности: (1) упоминание лица (группы лиц), которое совершает движение, причем, как правило, конкретный способ передвижения указан в непосредственной близости от данного (часто в составе того же самого предложения); (2) направления движения , которое представлено конструкцией "к + N3" (44%) ( к дивану, к другу, к спуску, к нему… ), называющей чаще (36%) место локализации, а реже (8%) - лицо (лиц), по направлению к которым ориентировано движение; в небольшом числе случаев происходит сочетание этих частотных поверхностных структур (локализация + лицо); вторая частотная конструкция "в + N4" (27%) указывает на направление пространственной локализации движения ( в комнату, в деревню, в угол гостиной… ); окказионально встречаются конструкции "в сторону + N2", "на + N4", "по + N3".
Словарная дефиниция МАС "двинуться куда-л, в какую-л сторону, в каком-л направлении" перечисляет и частотные, и низкочастотные типы реализации валентности направления. Помимо лица, позицию первой валентности может занимать название транспортного средства и даже неодушевленного объекта, однако, такие примеры составляют 1% от общего числа контекстов. Окказиональные валентности (менее 10%) представлены также способом действия ( решительно, прямо, напрямик и т.п.), указанием целевого действия ( курить, изучать и т.п.), местом действия ( по берегу, через парк, по суше и т.п.), начальной точкой движения ( из Вифании ). Набор обязательных и факультативных валентностей составляет описание валентностной структуры значения слова, которая может непосредственно использоваться в синтаксических правилах формальной грамматики.
Еще один важный вопрос состоит в том, насколько валетностная схема признакового слова совпадает с собственно языковой структурой, например, со структурой статьи словаря ассоциативных реакций РАС. Ассоциативные словарьтакже предоставляет данные о сочетаемости слов, но в гораздо менее развернутой форме. В РАС информация о потенциальных или реальных контекстах слова, ограничена рамками словосочетания, многословные ассоциации достаточно редки, они составляют менее 2% от общего числа ответов. Кроме того, поскольку в ассоциативном эксперименте симулируется ситуация речевого общения, левый контекст слов ( большой дом , взять за руку ) воспроизводится чаще, чем правый ( начать работать, хочу петь ). Несмотря на эти различия и ограничения, результаты контекстного анализа текстов и материалов РАС во многом согласуются друг с другом, позволяют выделить основные и периферийные значения слова. Например, на четыре выделенных в RussNet значения глагола чувствовать приходится около 84% ассоциаций в РАС и более 94% вхождений в текстах корпуса. Однако, ассоциативный словарь не дает преимуществ на уровне выявления особенностей сочетаемости слов, но облегчает установления семантических отношений между словами.
Количество различаемых в компьютерном тезаурусе значений слова определяется набором схем сочетаемости. В отдельных случаях сложно определить, насколько детально следует их описывать. Рассмотрим эту проблему на примере схем сочетаемости прилагательного большой . Три первых значения для этого слова в МАС сформулированы следующим образом:
Значительный по величине, размерам; противоп. Малый, маленький ║ Значительный по количеству, многочисленный ║ Появляющийся, находимый или производимый в большом количестве ║ Продолжительный по времени, охватывающий значительный промежуток времени.
Значительный по силе, интенсивности, глубине ║ Важный по значению.
при существительных, характеризующих качество человека, имеет усилительный смысл: В высокой степени, чрезвычайный ║ Замечательный в каком-то отношении, выдающийся.
Просмотр контекстов употребления в корпусе прилагательного большой позволяет определить частотность реализации значений: основное значение "значительный по величине, размерам" является самым частотным (38%). Среди существительных, сочетающихся с прилагательным в этом значения подавляющая часть (19%) обозначает артефакты (то, что создано человеком), среди которых есть и бытовые предметы ( матрац, пульт, печка ), и контейнеры различного рода ( кувшин, коробка, резервуар ), и помещения ( дом, зал, ресторан ), и ряд объектов, имеющих не столько пространственные измерения, сколько плоскостные ( карта, снимок, атлас ), причем выделение артефактов, как наиболее частотных определяемых объектов, не носит характер противопоставления естественным или природным объектам ( камень, залив, океан ), которых все-таки меньше (13%) и среди которых на удивление мало (3%) названий животных и растений ( птица, кошка, ромашка ). Две другие группы существительных, обладающих достаточно четким значением, являются небольшими по объему (по 4%). Одна обозначает части тела человека или животного ( голова, рука, лапа ), а также другие части: текста ( параграф ), вещества ( капля ). Вторая - собственно измерения ( размеры, расстояние, рост, высота ).
Оттенок первого значения "значительный по количеству" (24%) реализуется у прилагательного в сочетаниях с существительными обозначающими совокупности людей ( семья, совет, оркестр ), предметов ( коллекция, ряд ), финансов ( деньги, выигрыш, потери ), причем синоним в определении "многочисленный" сочетается не со всеми существительными. По частотности употребления в контекстах и особенностям сочетаемости с существительными это значение прилагательного является самостоятельным.
Следующим по частотности (20%) значением является "значительный по силе, интенсивности, глубине". Основная группа существительных, сочетающихся с указанным прилагательным в этом значении, как правило, представлена транспозитами от глаголов или прилагательных. Причем прилагательное большой является своеобразным трансформом наречий-адъюнктов признаковых слов, например, сильно давить => большое давление , сильно разочароваться => большое разочарование , очень редкий => большая редкость , которые в основном выражают значение интенсификатора признака или действия. Помимо этого значения, встречаются трансформы количественных значений, повторяемости действий: меняться часто => большая изменчивость, много потратить => большие траты . Это значение прилагательного совпадает с формулировкой 3-го значения, за исключением того, что в последнем случае определяются качественные характеристики людей: очень демократичный человек => большой демократ. В таком случае, возможно ли объединение этих значений? Учитывая, что для отглагольных существительных возможно сочетание с антонимичными прилагательными (ср. маленькие радости, маленькое давление ), а для обозначений качеств такое сочетание невозможно ( *маленькая редкость, *маленький демократ, *маленький мастер ), очевидно, что значения должны быть сформулированы как два лексикализованных понятия с четким указанием семантических типов существительных, сочетающихся с прилагательными в данных значениях.
При корректировке методики построения синсетов была установлена следующая закономерность: элементы синсета (синонимы) обладают однотипной сочетаемостью (совпадение обязательных и/или факультативных валетностей) в корпусе современных текстов, при этом форма поверхностного выражения валентностей у синонимов может различаться, окказиональные валентности также могут быть различны.
Для подключения русского wordnet-тезауруса к структуре межъязыкового индекса (ILI) используются специальные отношения, которые были предложены в рамках EuroWordNet: EQ-синонимия, EQ-гипонимия и проч. Собственно элементы ILI представляют собой набор понятий, распределенных по областям, но не упорядоченных полностью в структуры деревьев. Если устанавливается отношение тождества между синсетом RussNet и элементом ILI, то синсет присоединяется к элементу одиночной связью EQ-синоним. Например, {продукт1} EQ-синоним {artefact, artifact}. В противном случае, синсет присоединяется как минимум двумя связями, например, EQ-гипоним и EQ-мероним. Например, для русского синсета {запеканка1} не существует прямого эквивалента в ILI, поэтому он связывается отношением EQ-гипоним с элементом {baked goods} и EQ-мероним-субстанция {dairy product}.
Библиография
Vossen, 1998 - Vossen, P. (ed.): EuroWordNet: A Multilingual Database with Lexical Semantic Network. Dodrecht, Kluwer.
Уфимцева, 2002 - Уфимцева Н.В. Ядро языкового сознания русских (по данным массовых ассоциативных экспериментов) // Доклады научной конференции "Корпусная лингвистика и лингвистические базы данных". СПб, 2002. С. 157-164.
Азарова и др. 2002 - ^ Азарова И.В., Митрофанова О.А., Синопальникова А.А. Компьютерный тезаурус русского языка типа WordNet // Компьютерная лингвистика и интеллектуальные технологии. Труды Международной конференции Диалог 2003 (Протвино, 11-16 июня 2003 г.) М., 2003. C. 43-50.
Материалы к компьютерному тезаурусу… 2002 - Материалы к компьютерному тезаурусу лексики русского языка / Сост. И.В. Азарова, О. А. Митрофанова. СПб., 2002. 232 с.;
Azarova et al. 2002 - Azarova I., Mitrofanova O., Sinopalnikova A., Yavorskaya M., Oparin I. RussNet: Building a Lexical Database for the Russian Language // Workshop Proceedings: Workshop on WordNet Structures and Standardisation, and how these affect Wordnet Application and Evaluation. 28th May 2002. Las Palmas de Gran Canaria, 2002. P. 60-64.
Источники
МАС - Словарь русского языка / Под. ред. А.П. Евгеньевой. Т. 1-4. М., 1985-88.
РАС - Караулов Ю. Н. и др. Русский ассоциативный словарь. Т. 1-6. М., 1994, 1996, 1998.
РСС - Русский семантический словарь: Толковый словарь, систематизированный по классам слов и значений / Российская академия наук. Ин-т рус. яз. им. В. В. Виноградова; Под общей ред. Н. Ю. Шведовой. - М., 1998.
ТСРГ - Толковый словарь русских глаголов: Идеографическое описание. Английские эквиваленты. Синонимы. Антонимы / Под ред. Л. Г. Бабенко. М., 1999.
1 Например, в ходе работы с лексикографическими источниками было обнаружено, что в ТСРГ (Бабенко, 1999) отношения синонимии и антонимии не являются симметричными. Для глагола беситься в качестве синонимов указываются злиться, неистовствовать , при этом беситься не включен в синонимические ряды для каждого из них: злиться - син. сердиться; а неистовствовать - син. бесноваться, буйствовать, бушевать. В ходе анализа материалов РСС (Шведова, 1998) нами была выявлена неравномерность в членении семантических классов, одни из них оказались описаны излишне подробно, тогда как для других степень детализации была явно недостаточной. В эксперименте это было продемонстрировано тем, что на долю одного класса пришлось около 80% существительных, извлеченных из текстов, тогда как для ряда других не было найдено ни одного представителя.
2 http://www.phil.pu.ru/depts/12/RN/
3 http://nlp.muni.cz./projects/bonito
|
Использование схемы наследования рамок валентностей в тезаурусе RussNet для автоматического анализа текста И. В. Азарова (Санкт-Петербургский государственный университет) azic@bsr.spb.ru В. Л. Иванов (ООО "Идеограф") artifex.i@gmail.com Е. А. Овчинникова (ООО "Идеограф") e.ovchinnikova@gmail.com В докладе рассматривается процедура автоматического анализа текста Идеограф, которая использует формально-грамматическое описание русского текста Rus4IR и ресурсы компьютерного тезауруса RussNet. Рамки валентностей RussNet позволяют разрешать лексическую и грамматическую неоднозначность. Рамки содержат спецификацию контекстных маркеров для валентностей, которые определены на материале текстового корпуса. Семантическая интерпретация текста задается в виде структур пропозиций, ядерными элементами которых являются субъектно-объектные позиции, соотнесенные с семантическими деревьями тезауруса RussNet. На примере трех семантических деревьев описывается схема наследования рамок валентностей в RussNet, которая используется для уточнения анализа предложения, ранжирования вариантов анализа, унификации позиций при семантическом выводе. На сайте ACL Anthology1 (архива исследовательских работ по компьютерной лингвистике), где представлены исследовательские материалы начиная с 1979 г., можно выделить две основные тенденции разработок: (1) системы с традиционными лингвистическими модулями, которые ориентированы на всеохватывающий анализ текст, причем анализ осуществляется "снизу-вверх" от наименьших единиц типа морфем или основ к наибольшим (предложениям, текстам); (2) эвристические системы с "распределенной" архитектурой и комплексным описанием, объединяющим данные нескольких лингвистических уровней. Очевидны недостатки этих подходов. Для первого типа характерна высокая неоднозначность анализа на каждом из последовательных уровней, которая дополнительно возрастает при переходе от одного уровня к другому. Второй тип систем может показывать высокую эффективность в некоторой ограниченной области, однако отсутствие понимания глубинных механизмов и реализация типа "ad hoc" не дает возможности расширения частных случаев (чаще всего, предметных областей) на другие области.
В подходе ИДЕОГРАФ2 мы постарались совместить преимущества двух типов анализа: система имеет модульный принцип, при этом модули "низшего" лингвистического уровня встроены в модули следующего уровня, так что внешним модулем является семантический. Эта система "встраивания" структур низшего уровня в высшие позволяет существенно понизить неоднозначность анализаторов и облегчает передачу данных между модулями. Основными компонентами системы ИДЕОГРАФ являются Грамматический анализатор построен на базе контекстно-свободной грамматики AGFL, дополненной уровнем "признаков" с заданными значениями (в терминологии К. Костера они называются аффиксами). В качестве признаков используются бесспорные грамматические категории (например: вид и залог глаголов, падеж существительных и проч.), различные вспомогательные словоизменительные признаки (например: подтипы склонения, словоизменительные классы глаголов, возвратность и проч.), а также более сложные характеристики фразовых структур (например: отрицательный/ неотрицательный предикат, признак малого и большого количества для описания сочетаний количественных числительных с существительными и проч.). Хотя генеративное описание считается прямой противоположностью статистического подхода к анализу текста, мы исходим из концепции "гибридного разбора" ("hybrid parsing" - Beinema, Koster 2004), при котором предполагается использовать частотные параметры синтаксических конструкций в корпусе современных текстов с тем, чтобы ускорить вычисления и придать грамматическому анализу стереотипный характер. Таким образом, мы добиваемся того, чтобы в качестве "первого" разбора в подавляющем количестве случаев (95%) выдавались наиболее правдоподобные варианты.
Морфологический модуль использует словарь основ, который охватывает все слова, включенные в RussNet. Опознанная основа морфологического словаря отсылает к синонимическим рядам (синсетам) тезауруса RussNet, в которые входит данное слово. Такие связи являются "проекцией" леммы на тезаурус. Если грамматическая форма слова не совместима с каким-либо значением, то оно не будет входить в ее "проекцию". Например, леммы слова гусеница (1) 'личинка бабочки' и (2) 'замкнутая металлическая цепь, состоящая из звеньев, служащая вместо колес у тракторов, танков и т.п.' морфологически различаются формой вин. падежа мн. ч., поэтому во фразе " его кидают под гусеницы танков " лемма однозначно указывает на значение (2), напротив, во фразе " выращивать гусениц плодожорки можно на среде …" - на значение (1), а во фразах " место на коже, к которому прикасалась гусеница , надо обдуть… " или " из темноты послышался грохот и лязг гусениц " отбор подходящего значения будет осуществляться на других этапах анализа.
Выявленный через проекцию синсет в тезарусе активирует стандартную для wordnet-словаря окрестность - набор синсетов с установленными семантическими связями: родовидовыми (гипонимы-гиперонимы), связями часть-целое (меронимы-холонимы), анотонимы и проч. Последовательность гиперонимов синсета определяет его принадлежность к тому или иному семантическому дереву. Так значение (1) в предыдущем примере входит в дерево "животные", а значение (2) - дерево "артефакт" (предмет, созданный человеком). В семантическом блоке можно задавать объединения деревьев, регулярно используемые группировки получают стандартные обозначения совокупности, например "одушевленные" ("человек", "люди", "животные"). Вопрос о самостоятельности некоторого дерева, во-первых, связан с набором образующих его синсетов (деревья имеют сопоставимые объемы), и во-вторых, с тем, насколько часто данная совокупность синсетов может выступать в качестве семантической спецификации валентной позиции (см ниже).
Поскольку в тезауруса RussNet заданы значения только для основных частей речи (существительных, глаголов, прилагательных и наречий), для слова других частей речи, в частности местоимений, в семантическом блоке определяется проекция на структуру тезаурусных значений: личные местоимения 1 и 2-го лица указывают на вершину дерева "человек", а местоимение 3-го лица в м. и ж. роде ед. ч. или во мн. ч. имеет проекцию на ряд деревьев из более широкой совокупности "сущность".
Словарь основ может быть расширен за счет деривационного модуля, который порождает новые основы от имеющихся при помощи продуктивных префиксов и суффиксов. Сгенерированная основа получает "привязку" к синсетам RussNet посредством семантико-деривационных отношений. Например, префикс "анти-" образует новые основы для прилагательных и существительных, которые присоединяются к членам имеющихся синсетов отношением der_antonym_opposite (деривационный антоним комплементарного типа). Слова с данным префиксом, которые регулярно встречаются в корпусе ( анти со вет ски й 10.2 ipm, антивоенный 1.48 ipm, антитело 2.14 ipm и проч.), входят в RussNet, а следовательно, и в словарь основ, но такие образования как антигерой считаются потенциальными словами и получают грамматическую и семантическую интерпретацию лишь в деривационном блоке. Использование процедуры деривационного анализа носит ограниченный характер, поскольку она увеличивает время обработки одного слова на 10%, уменьшая количество неопознанных слов лишь на 3 %. В нашей системе рамки валентностей выявляются и описываются на этапе подготовки данных для тезауруса RussNet. Чтобы разграничить значения полисемантичного слова, размечается случайная выборка его контекстов из корпуса современных текстов. В качестве "нулевой" гипотезы используется структура значений в толковом словаре МАС. Количество контекстов в выборке на каждое из значений используется для новой нумерации значений в тезаурусе RussNet (это часть стандартной процедуры подготовки wordnet-словарей). Перечисляются синтаксические и семантические параметры маркеров, занимающих одну и ту же функционально-синтаксическую позицию. Регулярно встречающиеся параметры задают валентности. Таким образом, валентности в RussNet определяются через частотность реализации маркеров, а не спекулятивно. Минимальным порогом частотности является 35% от совокупности контекстов, реализующих данное значение. Те валентности, которые встречаются с высокой частотностью (68-100%), считаются обязательными, менее частотные - факультативными.
Мы провели исследование количества контекстов3, которые необходимы для разграничения значений и определения контекстных маркеров, и выяснили, что 100 случайных контекстов из корпуса дают такую же схему валентностей, что и 1000 контекстов; минимальным набором является 25 контекстов. Проблемным для описанного подхода являются редко встречающиеся в корпусе значения, возможность приписывания валентностей для них связана со схемой наследования рамок валентностей в семантических деревьях, которая будет описана ниже.
Разметка частотности употребления значений в выборках контекстов показала, что в довольно большом числе случаев (около 80%) распределение частот носит весьма четкий характер: первое значение (которое, правда, не всегда совпадает с первым значением в толковом словаре) представлено в 50-70% контекстов, напротив, низкочастотные значения довольно плохо противопоставлены по частоте и регулярно составляют долю от 1 до 5% контекстов. Для общей характеристики рамки валентностей используется параметр (main_segment), задающий конструкцию, в рамках которой разрешаются валентности: пропозициональная (т. е. предикативная) или референциальная (т. е. атрибутивная) структура. Семантическая характеристика валентности (sem_type) указывает, какой тип следует приписать валентному сегменту. В конструкции пропозиции это может быть объект, атрибут пропозиции, встроенная пропозиция, а в референциальной структуре - объект и атрибут объекта. В том случае когда нет ясности в отношении этих параметров, они могут опускаться. ^ Схема 1. Пример xml -представления рамки валентностей Ролевая характеристика валентности (role) регулярно встречается в различных концепциях описания валентности. Однако вместо традиционного набора (объектив, результатив и проч.) мы используем аргументную (субъектно-объектную) структуру, которая привязана к определенному семантическому дереву RussNet. Например, для дерева глаголов движения, которое рассматривается ниже, выделяются следующий набор аргументов: arg0 - одушевленный или неодушевленный субъект движения; arg1 - конечная точка движения; arg2 - начальная точка движения; arg3 - пересекаемое пространство; arg4 - средство транспорта, которое используется для движения; arg5 - субъект, который направляется при движении; arg6 - объект, который переносится при движении и т. п. Нумерация аргументов показывает, насколько часто признак пропозиции уточняется в контекстах членов синсета, относящихся к данному дереву. Семантические ограничения, накладываемые на заполнение валентной позиции задаются в блоке (sem_data) путем отсылки на семантические деревья RussNet, при этом задается тип отсылки (TYPE): значение "top" указывает на вершину дерева (например "человек"); "group" задает стандартную группировку деревьев (например, "одушевленный"), значение "synset" является отсылкой к определенному синсету RussNet. Параметр ID конкретизирует адрес в структуре тезауруса. Аналогом данного блока являются уточнения в скобках в традиционных словарных описаниях, например: 'двигаться, вращаясь (о круглых предметах'. Однако реальные контексты употребления слов зачастую дают более широкий спектр возможностей для заполнения валентной позиции. Например, для значения катиться1 позицию субъекта заполняют не только шар, колобок, клубок, колесо , но и камни, тела людей, булыжник, комок теста . Грамматическая спецификация валентности ( morph_data ) включает указание части речи (возможны объединения) и значения грамматических категорий, которые существенны для оформления позиции (например, предложно-падежная форма существительного, видовая характеристика инфинитива, разряд наречий и проч.). Среди многообразия способов выражения валентности выбираются те варианты (variant), которые имеют статистическую устойчивость. Низкочастотные заполнения валентной позиции будут обсуждаться ниже, при описании схемы наследования валентностей. Параметр позиции ( place ) используется в том случае, когда валентная позиция устойчиво (>50%) в контекстах занимает позицию, которая не совпадает с нейтральным порядком слов в словосочетании или предложении. 3. 2. Схема наследования рамок валентностейИсследовательской задачей настоящей работы является описание того, как и в какой степени параметры рамок валентностей наследуются в семантических деревьях RussNet в синсетах, связанных родовидовым отношением (синсет А - гипероним, В - гипоним). Мы рассматриваем данную проблему применительно к трем разным деревьям: глаголам движения, глаголам принятия положения в пространстве и глаголам изменения местоположения объекта. Для иллюстрации описываемой схемы на рис. 2 приведен фрагмент дерева глаголов движения. 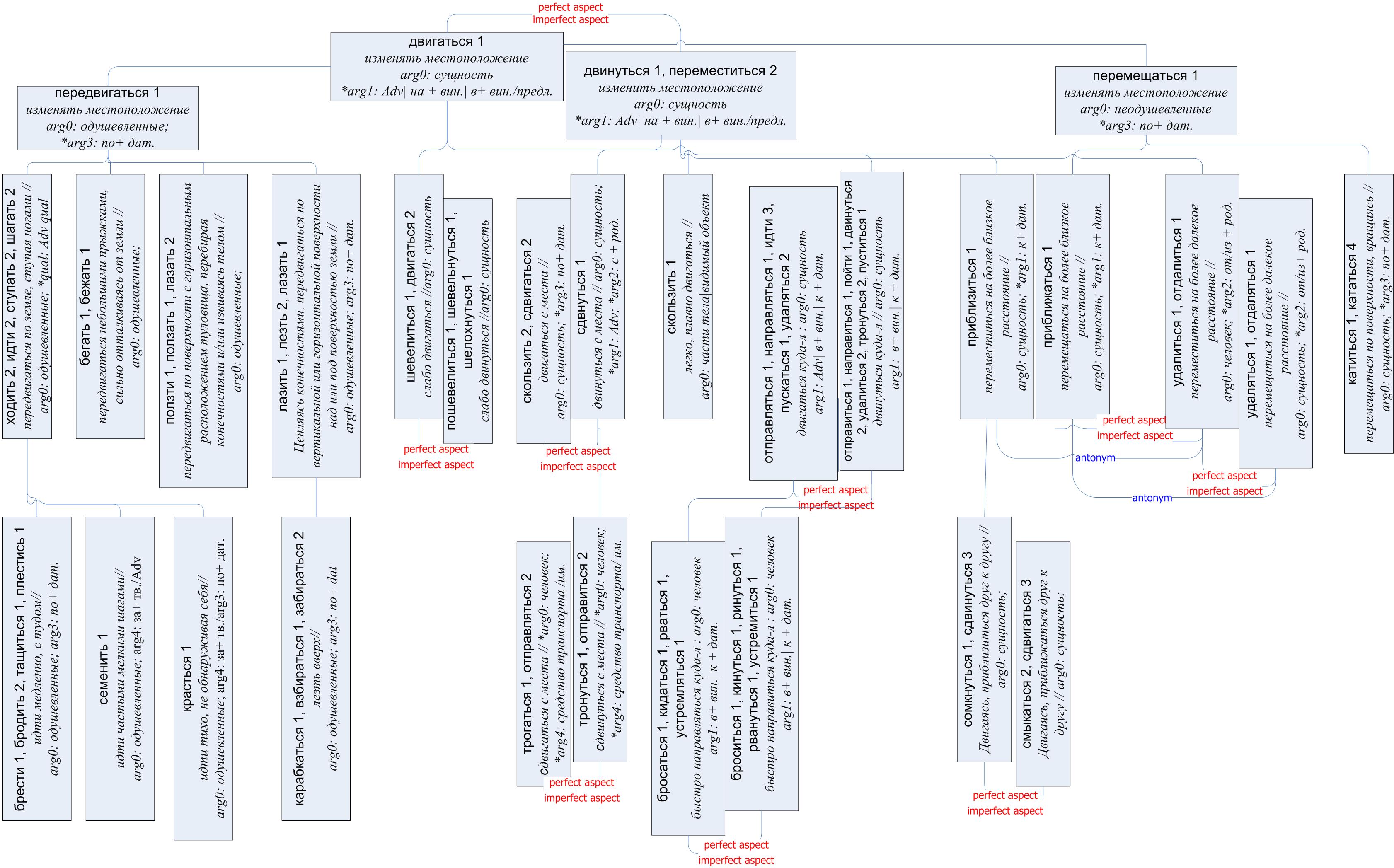 Фрагмент семантического дерева представлен в виде двух параллельных гипонимических структур для глагольных синсетов совершенного/несовершенного вида (СВ/НСВ). Соотносимые по значению глаголы связаны семантико-грамматическим отношением perfect/imperfect aspect. Гипонимические структуры не полностью идентичны, поскольку некоторые значения синсетов чаще реализуются в корпусе глаголами НСВ, а другие - СВ. На рисунке частотно доминирующий синсет слегка "приподнят" по отношению к синсету с видовыми парами. При определении "доминирования" учитывается, что общее число глаголов несовершенного вида примерно в 1,5-2 раза превышает число глаголов совершенного вида в корпусе (что объясняется грамматической маркированностью значения совершенного вида). В отдельных случаях, например для синсета { трогаться1, отправляться2 }, частота употребления глаголов НСВ столь незначительна по сравнению с их видовыми коррелятами 0,1 vs 7 ipm, что они присоединяются в тезаурусе лишь аспектной связью к синсетам коррелятов { тронуться1, отправиться2 }. Такой же способ присоединения будет использован для "потенциальных" видовых глагольных пар, которые не были зарегистрированы в корпусе, но которые могут встретиться окказионально при обработке текста. Что касается схемы наследования рамок валентностей для синсетов видовых коррелятов, то они регулярно совпадают. Однако при низкой частотности членов синсета полная картина дистрибуции контекстных маркеров бывает не видна. Опираясь на адекватно представленные дистрибуции синсетов разных видовых пар, мы считаем, что валентная рамка более частотного видового синсета наследуется низкочастотным коррелятом. Будем рассматривать наследование рамок по отдельным параметрам, которые будут указываться в подзаголовке. ( I ) Обязательность/факультативность (obligatory) Параметр факультативности валентности обозначен на рисунке звездочкой. Наследование этих параметров проходит по-разному в субъектной позиции и остальных аргументных позициях. ( I а) Субъектная позиция (arg0) В субъектной позиции возможны два типа соотношения между значениями параметра obligatory для гиперонима А и гипонима В (после слеша указан процент реализации соотношения в рассмотренных деревьях): (1) obligatoryА="yes" => obligatoryВ="yes" / 99% (2) obligatoryА="yes" => obligatoryВ="no" / 1% Процент сохранения обязательности субъектной позиции является практически абсолютным. Ослабление субъектной валентности происходит при появлении другого "агентивного" участника в рамке, например для глагола везти1 'двигаясь, перемещать кого-/что-либо каким-либо средством транспорта' ( В машине я спросил, куда меня везут ? Он не хотел, чтоб меня везли в другую больницу ). При этом формы 1-2-го л. дают возможность установить субъекта действия, хотя он и не задан в поверхностной структуре, ср. Важных гостей везу! (arg0: "я"). ( Ib ) Несубъектные позиции (arg1…) В других аргументных позициях факультативной валентности гиперонима может соответствовать обязательная валентность гипонима. Например: передвигаться1 - лазить1 (arg3: 40% vs 80%). (3) obligatoryА="no" => obligatoryВ="yes" / 43% Факультативная валентность гиперонима может преобразоваться в окказиональную, которая не указывается в рамке валентности, например: передвигаться1 - ползти1 (40% vs 20%). (4) obligatoryА="no" => / 44% Сохранение параметра обязательности аргументной позиции встречается окказионально в рассматриваемых деревьях: (5) obligatoryА="Х" => obligatoryВ="Х" / 13% Вариант соотношения (4) значения параметра обязательности в рамках гиперонима-гипонима может быть использован в процедуре разрешения неоднозначности для идентификации низкочастотных "следов" валентностей гиперонима в контекстах гипонима. Еще один важный аспект наследования схемы валентностей - то, что для низкочастотных синсетов в структуре RussNet, у которые нет в корпусе достаточно данных для задания рамки валентностей, ее можно экстраполировать по рамке гиперонима, используя (3). ( II ) Семантические ограничения (sem_data/"group") Первоначально было замечено, что семантические группировки рамки прилагательного-гиперонима являются тождественными или более общими, чем у гипонима (Azarova, Sinopalnikova 2004). Это положение вполне подтверждается для рассмотренных деревьев. В частности, вершиной дерева глаголов движения глагол можно выбрать глаголы двигаться (двинуться), передвигаться , перемещаться (пе ре ме ститься) , в корпусе соответствующие значения представлены в объеме 42 ipm4 (10 ipm), 12 ipm (1,3 ipm), 7 ipm. В словарном определении МАС для дви гаться 'совершать движение, передвигаться, перемещаться', глагол представлен как синоним пе редвигаться , перемещаться . Однако различия в частотности глаголов подкрепляются разными типами заполнения позиции arg0. Для двигаться это любой наблюдаемый объект: человек, группа людей, средства транспорта, части тела человека, животные, механизмы, естественные объекты, то есть группировкой "RUS-nEntity". Соотношение одушевленных и неодушевленных заполнений позиции 3:2. Для глагола передвигать ся эта группировка сокращается до RUS-nAnimate (человек, животные), а для перемещаться - до RUS-nInanimate (средства транспорта, естественные объекты, механизмы, части тела человека). Поскольку эти соотношения носят статистический характер, нельзя сказать, что не бывает противоположных случаев, но они укладываются в границы окказиональных флуктуаций. Более того, даже если речь идет о человеке при глаголе перемещаться контекст весьма характерно представляет действие, например: Гора мышц и мускулов перемещалась на столе . Таким образом, в отношении параметра sem_data чаще наблюдается схема наследования, реже - сужения: (6) groupА = groupВ / 85% (7) groupА groupВ / 15% ( III ) Морфологическое оформление (morph_data) Для данного параметра соотношения рамок гиперонима-гипонима зависят от аргументной позиции. ( III а) Субъектная позиция (arg0) В субъектной позиции наблюдается доминирование схемы наследования формы именительного падежа (8) CASEА="nom" => CASEВ="nom" / 100% ( IIIb ) Несубъектные позиции (arg1…) Наследование грамматического оформления аргументной позиции, помимо субъектной, носит окказиональный характер (например направиться вперед, в сторону, к дому & идти вперед, в сторону, к дому ), причем наследоваться может схема не только непосредственного гиперонима (ср. передвигаться по залу & красться по коридору ). (9) variantsВ = variantsА / 23% Чаще всего грамматические варианты оформления валентности гипонима представляют собой пересечение с вариантами гиперонима. Например, валентность конечной точки движения (arg1) для синсета { двигаться1 } оформляется наречием; предложно-падежной конструкцией "в + В./П.п." или "на + В.п." ( двигаться вперед, в сторону, в направлении, на север ); два варианта - наречие и конструкция "в + В.п." - совпадают с морфологическим оформлением гипонима { отправиться1, направиться1, … }, при этом у гипонима есть и другие частотные варианты ( направиться вперед, в сторону, к дому ). остальные варианты различаются. (10) variantsВ variantsА (70%) Существенно реже наблюдается сокращение морфологических вариантов оформления аргументной позиции гиперонима у гипонима (ср. направиться вперед, в сторону, к дому vs броситься в сторону, к дому ). (11) variantsВ variantsА (7%). Следует отметить, что даже в тех случаях, когда морфологическое оформление валентности у гипонима-гиперонима не наследуется частотно, на уровне окказиональных употреблений они составляют приблизительно один и тот же набор. Поэтому у корневых синсетов { двигаться1 } наблюдается самый широкий диапазон окказиональных вариантов грамматического оформления валентности, которые тем не менее столь разнообразны и малочисленны, что не представляется возможным их перечислить. Поэтому более реальным является перечисление частотных морфологических вариантов у гипонимов, но тогда надо признать наследование в обратном направлении, как "просачивание" морфологической формы аргументной позиции от гипонима к гиперониму. В качестве частного замечания относительно морфологического оформления хотелось бы отметить, что среди предложных вариантов оформления валентностей регулярно встречаются многозначные исконные предлоги к, в, по, на, с в отличие от мотивированных предлогов типа вдоль, сквозь и т. п. Этот факт интерпретируется следующим образом: "семантически определенные" предлоги относительно самостоятельны, их интерпретация в отношении аргументной структуры более-менее однозначна, кроме того, их использование отчасти факультативно: они задают "фокусное" (конкретизированное) заполнение аргументной позиции. Такую же точку зрения высказывала Е.С. Скобликова (Скобликова 1990, с. 87), указывая на синонимию предлогов: у стола, около стола, возле стола, подле стола, рядом со столом, близ стола, недалеко от стола . ( IV ) Набор аргументных позиций В отношении набора (конфигурации) аргументных позиций полное наследование встречается на уровне факультативности (52%), а с учетом наследования не только от непосредственного гиперонима доходит до уровня обязательности (66%). Все остальные случаи подпадают под соотношение типа "пересечения" (типа 10), если учитывать субъектную позицию (arg0). Появление новой аргументной позиции регулярно соотносится с наличием в морфемной структуре глагола аффикса (чаще префикса) (см. сдвинуться1 ). Можно предположить, что сходные наборы аргументов указывают на однотипность семантической структуры глаголов в каких бы частях семантического дерева они ни находились (ср. семенить1 и красться1 ). Контексты слов общей семантики типа двигаться дают максимальный набор возможных аргументов, правда, контекстные маркеры столь низкочастотны и разнообразны, что возникают проблемы как с идентификацией типа аргументов, так и с их нумерацией. Более реальным является исчисление аргументов по рамкам семантического дерева, порядок их нумерации определяется частотой употребления аргумента в дереве. Контекстные маркеры, которые не попали ни в одну рамку валентности семантического дерева, являются сирконстатами, они определяют общую ситуацию безотносительно к специфике его значений. Естественно, что аргументы одного дерева могут быть сирконстантами для другого. Между списками аргументов можно установить соответствия. 4. ЗаключениеОписанная выше схема наследования рамок валентностей в тезаурусе RussNet может уточнить процедуру разрешения неоднозначности системы ИДЕОГРАФ и процедуру семантического анализа в терминах аргументных структур пропозиций. Рассмотрение схемы наследования валентных рамок показывает, что наследуются лишь отдельные параметры, а не вся структура целиком. Расширяя набор обследованных деревьев RussNet, мы в дальнейшем постараемся уточнить описанную схему. Литература^ Advances in Probabilistic and Other Parsing Technologies / Blunt H., Nijholt A. (eds.) Kluwer Academic Publishers. 2000. Azarova I. The matching of AGFL subcategories to Russian lexical and grammatical groupings // Proceedings of the Second AGFL Workshop on Syntactic Description and Processing of Natural Language. Radboud University Nijmegen, the Netherlands, www.cs.ru.nl/agfl/papers/ 2002. Azarova I., Mitrofanova O., Sinopalnikova A., Yavorskaya M., Oparin I. RussNet: Building a Lexical Database for the Russian Language // Workshop on WordNet Structures and Standardisation, and how these affect Wordnet Application and Evaluation. 28th May 2002. Las Palmas de Gran Canaria, (2002) pp. 60-64. Azarova I., Sinopalnikova A. (2004) Adjectives in Russnet. In "Proceedings of the Second International WordNet Conference", GWC 2004, Brno, Czech Republic, January 20-23, pp. 251-259. Baker, Collin F., Fillmore, Charles J., and Lowe, John B. (1998): The Berkeley FrameNet project. In Proceedings of the COLING-ACL, Montreal, Canada. Beinema P., Koster C.H.A. (2004) ^ AGFL Grammar Work Lab: Manual for the AGFL system. URL: http://www.cs.ru.nl/agfl/papers/manual.pdf . 62 p. Calzolari N., Fillmore C., Grishman R., Ide N., Lenci A., McLeod C., Zampolli A. (2002) Towards Best Practice for Multiword Expressions in Computational Lexicons. In "Proceedings of LREC 2002". Las Palmas, Spain. Carpenter B. (1992) ^ The Logic of Typed Feature Structures. Cambridge University Press, Cambridge, England. 270 p. Church K, Hanks P. (1990) Word Association Norms, Mutual Information and Lexicography. Computational Linguistics, 16 (1), pp. 22-29. Hirst G. & St-Onge D. (1998) Lexical Chains as Representations of Context for the Detection and Correction of Malapropisms. In "WordNet: An electronic lexical database", Ch. Fellbaum (ed.), The MIT Press, pp. 307-332. Horak A., Kadlec V., Smrz P. (2002) Enhancing Best Analysis Selection and Parser Comparison. In "Proceedings of the TSD". Brno, Czech Republic, pp. 463-466. Kay M. (1986) Parsing in Functional Unification Grammar. In "Readings in Natural Language Processing", B. J. Grosz, K. Spark Jones & B. L. Webber, ed., Morgan Kaufmann Publishers, Inc., Los Altos, California, pp. 125-138. Koster C.H.A. (1991) Affix Grammars for natural languages. In "Attribute Grammars, Applications and Systems", International Summer School SAGA, Prague, Czechoslovakia, June 1991. Koster C.H.A. Transducing Text to Multiword Units // Workshop on MultiWord Units MEMURA at the fourth International Conference on Language Resources and Evaluation, LREC-2004. Lisbon, Portugal, May 2004. Leacock C., Chodorow M. (1998) Combining Local Context and WordNet Similarity for Word Sense Identification. In "WordNet: An Electronic Lexical Database". C. Fellbaum (ed.) MIT Press. pp. 265-283. Makino T., Torisawa K. and Tsujii J. (1997) LiLFeS - Practical Programming Language For Typed Feature Structures . In "Proceedings of Natural Language Pacific Rim Symposium "97" . Pantel P., Lin D. (2003) Word-for-Word Glossing with Contextually Similar Words. In "Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics, May 27 - June 1, Edmonton, Canada" Pollard C. & Sag I. (1994) ^ Head-Driven Phrase Structure Grammar. Chicago: University of Chicago Press. 440 p. Voorhees E.M. (1998) Using WordNet for Text Retrieval. In "WordNet: an Electronic Lexical Database", Ch. Fellbaum, ed., MIT Press, pp. 285-303. Азарова И.В. ^ Морфологическая разметка текстов на русском языке с использованием формальной грамматики AGFL // Компьютерная лингвистика и интеллектуальные технологии. Труды Международной конференции Диалог'2003 (Протвино, 11-16 июня 2003 г .) М., 2003. C . 51-55. Азарова И.В., Митрофанова О.А., Синопальникова А.А. Компьютерный тезаурус русского языка типа WordNet // Компьютерная лингвистика и интеллектуальные технологии. Труды Международной конференции Диалог'2003 (Протвино, 11-16 июня 2003 г .) М., 2003. C . 43-50. Азарова И.В., Секликов Ю. В., Иванов В. Л. ^ Интерпретация текстовых документов с использованием формальной грамматики AGFL и компьютерного тезауруса RussNet // Компьютерная лингвистика и интеллектуальные технологии. Труды Международной конференции Диалог'2004 ("Верхневолжский", 2-7 июня 2004 г .) М., 2004. C. 1-6. Азарова И.В., Синопальникова А.А., Яворская М.В. Принципы построения wordnet-тезауруса RussNet // Компьютерная лингвистика и интеллектуальные технологии. Труды Международной конференции Диалог'2004 ("Верхневолжский", 2-7 июня 2004 г .) М., 2004. C. 542-547. Скобликова Е.С. Очерки по теории словосочетания и предложения. Изд-во Саратовского университета: Куйбышевский филиал. 1990. 3 Сходные оценки наборов предложений (25 vs 200), которые можно использовать в качестве обучающей совокупности для разграничения значений полисемантичного слова, были получены в работе (Leacock & Chodorow, 1998). 4 ipm (items per million) - единиц на 1 миллион словоупотреблений в корпусе. |