
Перед всеми веб-разработчиками встает задача индивидуальной выборки контента для пользователей. С ростом объема данных и увеличением их разнообразия обеспечение точности выборки становится все более важной задачей, оказывающей существенное влияние на привлекательность проекта в глазах пользователей. Если вышеописанное входит в сферу ваших интересов, то, возможно, данный пост натолкнет на какие-то новые идеи.
В каждой эпохе развития IT-индустрии существовали свои buzzwords - слова, которые у всех были на слуху, каждый знал, что за ними будущее, но лишь немногие знали, что действительно стоит за этим словом и как им правильно воспользоваться. В своем время баззвордами были и "водопад", и "XML", и "Scrum", и "веб-сервисы". Сегодня одним из основных претендентов на звание баззворда №1 является "big data". С помощью больших данных британские ученые диагностируют беременность по чеку из супермакета с точностью, близкой к ХГЧ-тесту. Крупные вендоры создают платформы для анализа больших данных, стоимость которых зашкаливает за миллионы долларов, и нет сомнений, что каждый пиксель в любом уважающем себя интернет-проекте будет строиться с учетом больших данных не позднее, чем к 2020 году.
При этом редкая статья про алгоритмы анализа больших данных обходится без комментария "Ну покажите мне работающий в промышленных масштабах пример!". Поэтому не будем ходить вокруг да около и начнем с примера: www.ok.ru/music. Большая часть контента в музыкальном разделе Одноклассников подбирается на основе "больших данных" индивидуально для каждого пользователя. Стоит ли оно того? Вот несколько простых цифр:
- +300% прослушиваний и подписок
- +200% добавлений песен
- +1000% CTR при таргетировании музыкальной рекламы
Но главное совсем не это. Куда ценнее живое и непредвзятое мнение реальных пользователей. Год назад в рамках проекта "За окном" люди, никогда раньше не пользовавшиеся Одноклассниками, провели в сети две недели, подробно отчитываясь о своих впечатлениях. Один из отзывов о музыкальном разделе звучал так: "Оно каким-то образом угадывает, что мне нравится. Не понимаю как, но это приятно".
На самом деле никакой магии, конечно, нет - все дело в данных. Тех самых данных, которые генерируют наши пользователи, прослушивая и загружая музыку, просматривая музыкальный каталог. Информация обо всех действиях пользователя стекается в классическую реляционную базу данных MS SQL, где происходит первичная обработка, фильтрация и агрегация данных (да, старый добрый SQL тоже может обрабатывать big data). Подготовленные в SQL данные выгружаются для дополнительного анализа в небольшой Hadoop-кластер, который делает компактную, но информативную выжимку, используемую уже в реальном времени (часть её импортируется в Cassandra, часть загружается сразу в память). Для пущей оперативности последние действия пользователей складываются в БД (Tarantool) и также учитываются в онлайне.
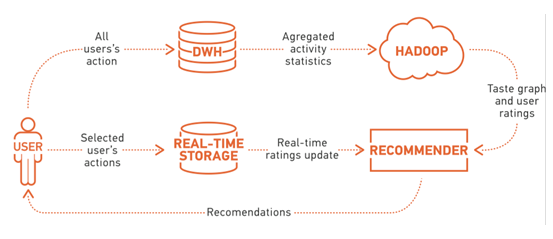
Используемая для подборки контента выжимка включает в себя разного рода корреляции между объектами разных типов. Для музыкальных треков это информация о том, как часто их слушают в пределах небольшого временного окна (темпоральная схожесть). Для музыкальных исполнителей это информация о том, как часто они нравятся одному и тому же пользователю (коллаборативная схожесть), и о том, насколько похожи музыкальные списки их ближайших соседей (коллаборативная схожесть второго порядка). Для пользователей это информация о том, какие треки, каких исполнителей и как часто они слушают (пользовательские рейтинги). Для удобства обработки все корреляции записываются в единую структуру - граф вкусов.
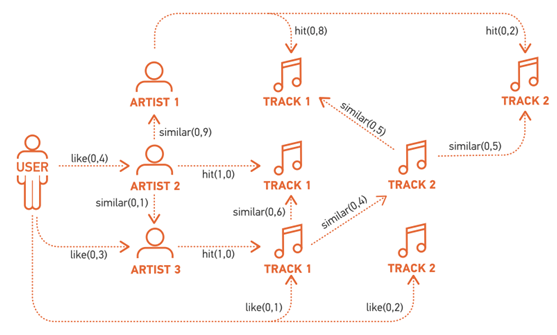
Благодаря относительно компактному размеру, граф вкусов позволяет в реальном времени решать широкий спектр задач, связанных с персональным подбором контента. Имея список наиболее популярных треков по всей системе, можно:
- оценить их релевантность для конкретного пользователя (количество и вес путей длины не больше N между пользователем и треками),
- разбить вкусы пользователя на связные блоки (кластеризация по плотности подграфа общих соседей методом affinity propagation) и подобрать рекомендации под блок (personalized PageRank)
Имея сборник песен, составленный пользователем, можно подобрать похожие интересные треки (тоже PPR для сборника и персонализация результата для пользователя). Технические детали о том, как, зачем и почему, можно найти здесь.
От взгляда внимательного читателя не ускользнет тот факт, что ни одно из используемых решений нельзя назвать новым/прорывным/уникальным (нужное подчеркнуть) ни с точки зрения алгоритмов, ни с точки зрения технологий. Почему тогда действительно качественные решения на основе big data появляются на российском рынке так редко?
Немало копьев было сломано (и ломается до сих пор) в спорах о том, какого же размера данные можно считать действительно "большими". Но действительно ли дело в размере? Сотни гигабайт/терабайт/петабайт (нужное подчеркнуть) данных не представляют ценности сами по себе - основное их предназначение в том, чтобы помочь понять прошлое и предсказать будущее. Очевидно, что одних лишь данных для этого не достаточно - нужны алгоритмы анализа, технологии и люди, которые смогут их внедрить.
Многие компании обладают массивами данных, достаточными для того, чтобы принести пользу бизнесу при правильном использовании. Алгоритмы обработки широко известны и активно развиваются, технологии обработки тоже доступны в различных ценовых категориях (от открытого ПО, способного работать на стоковом железе, до многомиллионных интегрированных комплексов). Очевидно, не хватает последнего, самого важного компонента - опытных людей, способных собрать все компоненты воедино.
Достаточно легко найти программиста, знающего все нюансы сборки мусора в Java, имеющего опыт работы с дюжиной СУБД разного типа, досконально знакомого со Spring/Trove/Hibernate и еще полусотней библиотек и пакетов. Однако большинство из них технологически ориентированы и "не заточены" на то, чтобы работать с литературой, осваивать новые методы статистической обработки, ставить эксперименты. Найти математика, способного на это, сложнее, но тоже возможно. Но в этом случае продвинуться дальше бесформенного облака кода Matlab будет чрезвычайно сложно. Вероятность же найти человека, способного взять лучшее от двух миров, настолько мала, что многие вообще сомневаются в их существовании.
Казалось бы, в такую ценную экологическую нишу должны стремиться попасть многие выпускники ВУЗов, но даже у вчерашних студентов наблюдается то же расслоение на "технарей" и "математиков". Первые в задачах интеллектуального анализа склонны к шапкозакидательским подходам "что тут делать-то", вторые уходят в нирвану математики и не всегда возвращаются. Но способности к обучению у них еще не так притуплены, как у зрелых специалистов, хотя их развитие и требует серьезных дополнительных инвестиций.
Несмотря на сложность и капиталоемкость, эффективная система интеллектуального анализа данных способна сделать проект очень привлекательным и удобным для пользователей, обеспечив прирост аудитории.