
В Google и Стэнфордском университете независимо друг от друга разработали очень схожие алгоритмы распознавания объектов на изображениях.
Результаты работы Google можно посмотреть здесь, а Стэнфордского университета - здесь. Полученные результаты очень похожи. Это набор картинок, который компьютерная программа пытается описать обычным человеческим языком.
Оба алгоритма используют принципы нейронных сетей и умеют самостоятельно обучаться даже на относительно небольших объемах данных, после чего с высокой степенью вероятности распознают похожие объекты на других изображениях.

Однако распознавание нескольких предметов на изображении это лишь часть проблемы. Необходимо также соотнести полученную информацию с остальной картинкой и описать ее понятным человеческим языком.
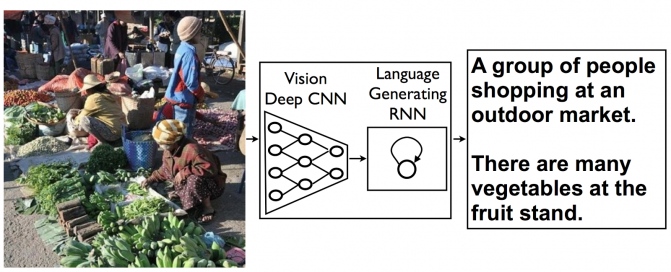
Для решения этой проблемы также используются принципы нейронных сетей в генераторе описания. Оба модуля системы (модуль распознавания и модуль описания) работают по вероятностному принципу и уже демонстрируют неплохие результаты даже на относительно сложных изображениях.
Несложно представить как в недалеком будущем Google сможет использовать подобный алгоритм для улучшения поиска по изображениям и видео на Youtube.




