
Компания Давида Яна многие годы работала над созданием искусственного интеллекта - технологии, способной понимать человеческий язык. Над проектом трудились сотни лингвистов и программистов, на него потратили свыше $80 млн и добились больших успехов. Дело за малым - отбить инвестиции и получить прибыль. Оказалось, что искусственный интеллект не слишком востребован на рынке
Меньше не имело смысла
В середине 1990-х BIT Software уже имела технологии оптического распознавания текстов и собственный спелчекер. Имеющиеся алгоритмы могли бы распознавать текст, исправлять опечатки и переводить, чтобы клиент, положив документ в сканер, вынимал его из принтера уже на другом языке. Идея была проста и гениальна, не хватало одного звена - автоматического переводчика, которого у компании не было.
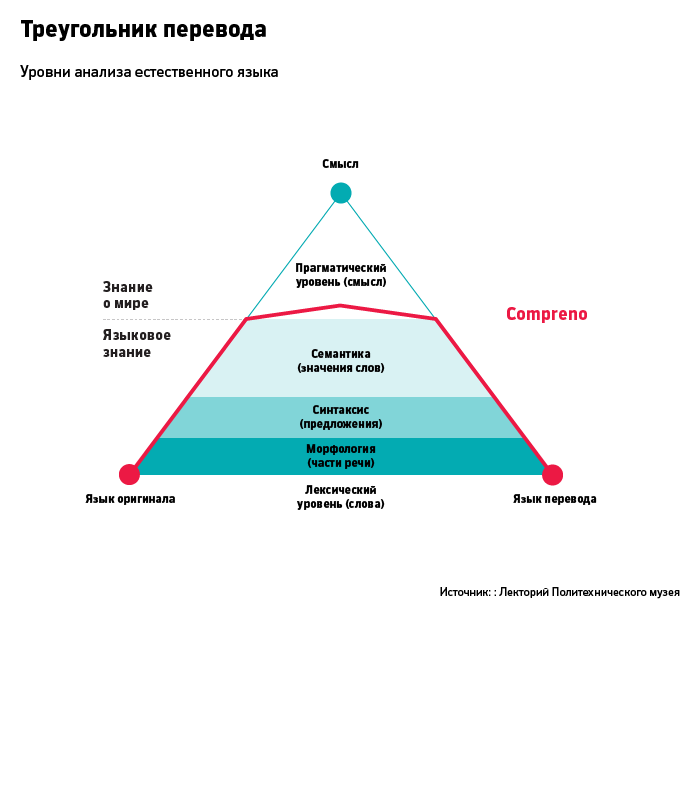
Любая попытка создать машинный перевод сталкивается с очевидной трудностью: языков очень много. Если 10 языков требуют 45 двусторонних переводчиков (10 х 9/2), то 20 - уже 190. Системы, построенные на правилах перевода между конкретными языками, с неизбежностью упираются в эту проблему. Чтобы обойти ее, в ABBYY решили создавать технологию, основанную не на правилах, а на модели естественного языка, говорит директор по лингвистическим исследованиям компании Владимир Селегей. Автоматический переводчик должен научиться понимать смысл текста (анализ), а затем излагать этот смысл на другом языке (синтез). То есть смоделировать работу мозга живого переводчика, построив таким образом искусственный интеллект. Для объяснения принципа работы Compreno в ABBYY используют схематический треугольник. На нижнем его этаже находятся отдельные слова - на этом уровне работает словарь. На следующем этаже - морфология и синтаксис - система умеет понимать, как устроена фраза. Затем - семантика, значения слов. В основе технологии, построенной ABBYY, лежит "универсальная семантическая иерархия", устанавливающая взаимосвязь между значениями слов. Слова в языках разные, но понятия одни и те же, объясняет Татьяна Даниэлян, отвечающая за технологические аспекты Compreno. В любой культуре понятно, что такое мебель и что стул - предмет мебели. Положение стула на дереве семантической иерархии - на мебельной ветке, в этом ее универсальность.
А одни и те же слова могут означать разные понятия. Скажем, выражение "собаку съел" в русском и корейском означает принципиально разные вещи. Поэтому собака внутри иерархии будет находиться на нескольких ветвях. Каждое слово, расположенное в той или иной части иерархии, снабжено невероятно подробным описанием, включающим его значения, управление, склонения и оттенки смысла. Compreno знает, к примеру, какие прилагательные русского или английского языка имеют положительные коннотации, а какие - отрицательные. В вершине треугольника находится прагматический уровень анализа языка, тот самый смысл, который так легко дается человеку и все время ускользает от машины. Compreno он пока недоступен, но, по словам Яна, система делает вылазки в эту сторону. Для этого программисты и лингвисты компании пишут специальные модули, которые называются онтологиями. Они моделируют некоторую область человеческой деятельности и учат систему обращать внимание на взаимосвязь между словами. После написания онтологии "начинается магия", говорит один из разработчиков Compreno: "Система понимает, например, что, если человек был откуда-то уволен, значит, прежде он там работал". Давид Ян особенно гордится тем, что Compreno сумела структурировать миф об Эдипе. После того как системе скормили текст, она смогла правильно описать взаимоотношения между героями и нарисовать диаграмму. Даже человеку непросто было бы справиться с сюжетом, в котором главный герой является для собственного отца не только сыном, но и счастливым соперником и убийцей.
Создание иерархии потребовало больших кадровых ресурсов. Владимир Селегей вспоминает, что на проектные мощности компания стала выходить в начале 2000-х. Именно тогда ABBYY создала в своих стенах "целый лингвистический НИИ", говорит сотрудник Института информационных технологий ВШЭ Анастасия Бонч-Осмоловская. С годами компания стала спонсором, а затем и фактическим организатором крупнейшей российской конференции по компьютерной лингвистике "Диалог", а к 2011 году открыла две профильные кафедры - в МФТИ и РГГУ. В научных кругах ABBYY воспринимали тогда как "корпорацию зла", черную дыру, которая вбирает в себя перспективных молодых ученых. "Люди прекращали писать диссертацию и уходили на большие деньги описывать слово "ластик", - возмущается академический лингвист. В лучшие годы над технологией, которая в итоге получила название Compreno, работало, по прикидкам Селегея, до сотни профессиональных лингвистов. Вот только продукта из нее не вышло.
Восстание машин
История современных подходов к машинному переводу началась в середине прошлого века. В 1949-м американский математик Уоррен Уивер написал одну из самых влиятельных работ в области вычислительной лингвистики, которая так и называлась: Translation. Уивер сформулировал предположение, через много лет оказавшееся на редкость продуктивным. Компьютеру необязательно понимать чужой язык, чтобы сделать удовлетворительный перевод, рассуждал он. Переложение, допустим, с турецкого на немецкий может быть задачей сродни расшифровке вражеского кода: не понимая смысла слов, машина может искать правильные соответствия, полагаясь на статистику. Если одна и та же конструкция раз за разом переводится одинаково, программа подставит этот перевод в нужное место. Так не создашь литературный перевод псалмов Давида, заметил Уивер, но для огромного числа технических текстов этого было бы довольно. Набрав большой корпус двуязычных документов и разжившись мощными компьютерами, можно попытаться перевести текст, не забивая себе голову тонкостями грамматики. В середине ХХ века компьютеры были недостаточно мощными, поэтому первые массовые попытки машинного перевода строились на других подходах. Компьютерные лингвисты пытались создать алгоритмы, основанные на грамматических правилах, бум таких программ пришелся на 1950-е. Затем разочаровались и в них, и на 20 лет гонка за машинным переводом, лишенная американских оборонных бюджетов, была приостановлена. А потом случилось то, на что надеялся Уивер. Сначала появились по-настоящему мощные компьютеры, а вслед за ними бесконечный источник параллельных текстов - проиндексированный интернет.
В начале 1990-х в IBM создали работающий образец программы статистического перевода Candide, задавший направление целой ветви компьютерной лингвистики. Через несколько лет появились интернет-поисковики, которые начали с невероятной скоростью индексировать терабайты человеческих знаний. В конце 2000-х, когда проект ABBYY наконец вышел на проектную мощность и должен был дать результат, свой переводческий сервис в открытое пользование выложил Google (а чуть позже и "Яндекс"). С бесплатным продуктом трудно конкурировать, признает Сергей Андреев.
:
В ABBYY быстро поняли, что профессиональным переводчикам не нужен продвинутый автоматический перевод: даже если семантическое дерево позволяет создавать переводы лучшего качества, ни один заказчик не примет их в нередактированном виде. С точки зрения профессиональных переводчиков, работающих конвейерным методом, дорогостоящий робот ABBYY едва ли мог быть полезнее, чем простые "пассатижи" Google Translate. Сложнейшая технология ABBYY еще до рождения проиграла конкуренцию алгоритму, который разве что не гордится своим лингвистическим невежеством. Андреев уверен, что битва проиграна, но исход войны не решен. "Кто мог предположить, - рассуждает он, - что этажерка братьев Райт - это бизнес? Ведь уже были и пароходы, и железные дороги. А будущее осталось за самолетами". Пусть система ABBYY не до конца отполирована, она принципиально лучше конкурентов и когда-нибудь возьмет свое, считает он.
Алексей Байтин, который отвечает за развитие статистического машинного перевода "Яндекс.Перевод", в этом совсем не уверен. Он отмечает главное достоинство машинного обучения: качество результата растет вместе с объемом доступных данных. Механически увеличьте корпус параллельных текстов в 2 раза - и вы достигнете лучших результатов, чем 50 лингвистов со знанием суахили. После нескольких лет бурного развития качество машинного перевода растет чуть медленнее, констатирует Байтин. Он и его коллеги ждут нового скачка, который случится не только за счет прогресса в машинном обучении, но и за счет того, что программа начнет лучше понимать грамматику естественного языка. Незнание лингвистики ограничивает успех алгоритмов, в Google и "Яндексе" этого не отрицают. И занимаются грамматикой, не обращая внимания на презрительные усмешки сотрудников ABBYY. "Еще посмотрим, кто из нас будет большим лингвистом через несколько лет", - замечает Байтин. Пока статистические переводчики учат грамматику, ABBYY движется в противоположном направлении: тренирует свою иерархию на статистических выборках. "Наша иерархия как ребенок, которому сначала помогают родители, а затем он учится самостоятельно", - говорит Ян. Мелкие неудобства Московский офис ABBYY занимает три этажа в бизнес-центре на территории режимного объекта, которая обнесена бесконечным забором и сообщается с миром через КПП. Вдобавок каждый дом в окрестностях располагает собственной оградой со шлагбаумом. Все вместе делает пейзаж довольно безотрадным. Если бы не яркий логотип на крыше бизнес-центра, можно было бы подумать, что идешь в шарашку. Внутри, впрочем, все выглядит вполне современно. ABBYY не пытается удерживать кадры, снимая крутой офис и расставляя вазы со свежими фруктами. Когда работа интересна, о мелких удобствах не задумываются, считает Сергей Андреев. А вот на будущем компания не экономит: если верить гендиректору, на исследования и разработки уходит около четверти выручки ABBYY - в 2 раза больше, чем тратят в относительном выражении Google или Microsoft. Рентабельность текущих проектов, говорит Андреев, составляет около 25%. Получается, что практически вся прибыль уходит в перспективные разработки. Дивидендов компания не платит, подтверждает Давид Ян. В конце 2010 года ABBYY получила грант "Сколково" на разработку технологии Compreno. Фонд выделил $15 млн при условии, что компания вложит в проект такую же сумму. По оценкам Андреева, на момент подписания договора инвестиции ABBYY в проект достигли $50 млн. Таким образом, всего Compreno обошлась минимум в $80 млн и все средства пошли на создание технологии, а не на маркетинг или продажи. Безумные траты на лингвистические исследования стали возможны потому, что они оплачиваются за счет основного, прибыльного бизнеса компании. Около 70% выручки поступает от продажи систем оптического распознавания символов (OCR). На этом рынке ABBYY - один из мировых лидеров, ее продуктами пользуются тысячи фирм, программное обеспечение лицензируется по всему миру, больше 30% сканеров оснащены программой FineReader.
Главный конкурент ABBYY на рынке OCR - американский софтверный конгломерат Nuance Communications с капитализацией за $5 млрд. В 1998-м Nuance хотел купить российский стартап, но акционеры отказались от сделки: по словам Андреева, условия были совершенно неадекватные. 10 лет спустя американцы подали против Яна и компании патентный иск на $265 млн - существенно больше выручки ABBYY, признает Андреев. Разбирательство длилось пять лет и обошлось ответчикам в $15 млн одних судебных издержек, но год назад дело было выиграно. Адвокаты строили свою защиту, рассказывая присяжным из Северной Калифорнии, как студенты-физики создали высокотехнологичный стартап и долго шли к успеху. "Мы хотели показать схожесть выпускников МФТИ и тех, кто выходит из стен Стэнфорда и Беркли", - вспоминал адвокат Джеральд Айви.
Карт-бланш на эксперименты
Со стороны ABBYY выглядит почти семейным предприятием. Все основатели до сих пор на месте, из 15 человек, перечисленных на сайте ABBYY в разделе "Руководство", семеро работают в компании больше 20 лет, пятеро - выпускники МФТИ. По словам Давида Яна, ему и его семье принадлежит контрольный пакет. За все время компания привлекала внешние инвестиции только дважды. В 2004 году долю в ней купил фонд инвесткомпании Mint Capital - по данным СМИ, около 10%. В 2011-м еще один небольшой пакет скупила у акционеров PFU Ltd, дочка японской Fujitsu. Кроме того, в ABBYY действует опционная программа, в которой участвуют более 150 человек. На поощрение сотрудников, рассказывал Сергей Андреев "Коммерсанту" в начале прошлого года, выделено 15% акций. В совете директоров три места из пяти принадлежат ветеранам компании - Яну, Андрееву и CTO Константину Анисимовичу, одно - Ульфу Перссону из Mint Capital и одно - независимому директору.
Перссон говорит, что менеджмент компании имеет большой кредит доверия у инвесторов и может не беспокоиться о получении немедленных финансовых результатов: "Фонд окупился уже много раз". Является ли проект Compreno следствием того, что идеалисты-основатели компании и инвесторы дают менеджменту карт-бланш на безумные эксперименты? "Конечно да! - не задумываясь отвечает Андреев. - Наверное, можно было бы потратить эти деньги на что-то более прибыльное и предсказуемое. Но нам хотелось сделать что-то большое и амбициозное".
В академическом сообществе Compreno уважают. Анастасия Бонч-Осмоловская несколько лет участвовала в организации соревнований между алгоритмами, посвященных анализу естественного языка. Программы ABBYY каждый раз занимали на них самые верхние места. "Если нанять несколько десятков лингвистов и 15 лет платить им нормальную зарплату, что-нибудь дельное обязательно получится", - добавляет она, но не видит для технологии очевидного преимущества в бизнесе. В ABBYY с этим, разумеется, не согласны. Их искусственный интеллект нужен всем. "Объем данных растет немыслимыми темпами, старые технологии захлебываются", - говорит Андреев. Кто справится с упорядочиванием знаний лучше робота, понимающего смысл сказанного? Compreno может претендовать на долю многомиллиардного, по оценкам ABBYY, рынка knowledge management (управление знаниями) - работ, касающихся каталогизации, тэгирования документов, поиска и выделения релевантных фактов. Андреев объясняет достоинства своего продукта на примере клиента - производителя цифровой техники. Кто-то из покупателей оставил в социальных сетях рецензию на видеокамеру, которая начиналась долгим перечислением достоинств устройства (красивая, удобная, и проч.), а заканчивалась словами "вот только не снимает". Compreno понимает, что это отрицательный отзыв, утверждает Андреев, а статистические системы - нет. 80% информации в мире не структурировано, говорит Максим Михайлов, который ищет клиентов для Compreno. Одно расследование банкротства Lehman Brothers потребовало анализа 350 млрд страниц текста. Никакая команда не способна вручную извлечь из такого массива данных релевантную информацию, для этого требуются алгоритмы. Лучше, если они при этом понимают смысл документов.
Жизнь в оранжерее
В деле извлечения фактов у ABBYY есть конкуренты. Один из них - знаменитая программа Watson, созданная IBM (два года назад она победила живого чемпиона в "Свою игру"). Конкуренция с гигантом не слишком пугает Яна: рынок очень большой.
Есть конкуренты поменьше. В компании RCO, которая называет своими клиентами Центробанк, "Газпром" и ФСБ, работает 30 человек, но ее руководитель Владимир Плешко не боится ABBYY. "Они росли в оранжерейных условиях", - уверен он. 10 лет назад Плешко увидел телеинтервью Давида Яна, который рассказывал о своей революционной системе анализа текста. "Я подумал: нам конец. Прошел год, другой, третий, мы выпустили собственную систему [извлечения фактов. - Прим. РБК], а у них так ничего и не появилось. То, на что они потратили 15 лет, мы сделали за пять усилиями нескольких людей", - говорит Плешко. Лингвисты RCO не пытаются создать универсальный искусственный интеллект, для каждого клиента делается своя система, которая удовлетворительно работает еще и потому, что анализирует специализированные тексты. Подавляющее большинство документов, с которыми работает Банк России, приносящий компании до 20% выручки, - финансовые; едва ли ЦБ понадобится интерпретировать "Царя Эдипа"
Проблема специализации стоит и перед Compreno. В компании прекрасно понимают, что специализированные алгоритмы работают гораздо эффективнее, поэтому большая часть возможностей системы не востребована. Разработка специальной онтологии для клиента лишает компанию главного преимущества ее технологии - универсальности. Один из несостоявшихся клиентов ABBYY завершил переговоры, когда понял, во сколько ему обойдется установка системы. "Их можно понять, они выделяют несколько специалистов на много месяцев работы. Но пока это того не стоит", - уверен он. У ABBYY есть конкурентные преимущества, обеспеченные основным бизнесом. Технология Compreno предлагается клиентам вместе с технологией ввода потоковых данных FlexiCapture, которая используется для массированного ввода, например, счетов за электричество, экзаменационных листов ЕГЭ или бюллетеней на выборах. Для крупной электрогенерирующей компании ABBYY успешно тестирует систему, которая интерпретирует и автоматически обрабатывает поток платежек - и ошибается реже, чем живые операторы, говорит Максим Михайлов. Для нефтяной компании внедряет систему анализа журналов учета происшествий на буровых.
Все эти изобретательные методы - недавнее начинание, замечает один из сотрудников компании: "До этого ABBYY, как Россия, профукала 10 тучных лет". Несколько собеседников журнала "РБК" в компании и за ее пределами согласны с этой оценкой. Анастасия Бонч-Осмоловская считает, что совладельцы и менеджеры компании - идеалисты, которые создавали искусственный интеллект скорее из романтических, нежели коммерческих побуждений. Но в кризис деловые соображения стремительно выходят на первый план. "Мы могли бы создать программу, которая пройдет тест Тьюринга, но что скажут наши маркетологи?" - размышляет Владимир Селегей. В конце 2014 года два десятка лингвистов вывели за штат. Сергей Андреев объясняет это тем, что ABBYY надо больше думать о продажах. "Наш НИИ должен, к сожалению, быть еще и успешной компанией", - лаконичен Давид Ян. Несмотря на 11 часовых поясов, которые отделяют калифорнийский дом основателя от центрального офиса, Ян не прекращает заниматься делами ABBYY. У него есть кабинет в штаб-квартире, а недавно Андреев временно устраивал его на менеджерскую позицию в фирме. В жизни Compreno он тоже принимает непосредственное участие, пытаясь вывести проект на потребительский рынок, на котором ABBYY не слишком успешна. Андреев жалуется на главную проблему потребителей: "Они не знают, чего хотят".
Год назад прямо внутри ABBYY возник настолько секретный стартап, что даже ветераны компании не всегда понимают, чем именно он занимается. Подчиняется он лично Яну и работает над тем, чтобы применить технологии интеллектуального поиска ABBYY в частных электронных архивах. Триллионы писем и сообщений, которые хранятся в миллиардах компьютеров и телефонов по всему миру, могут быть превращены в полезную информацию точно так же, как и данные компаний. Инженеры отличаются от ученых тем, что хотят не только исследовать мир, но и принести пользу, говорит Ян. Недавно он сходил в офис Facebook и рассказывает, как его заворожила мысль, что их продуктом пользуется больше миллиарда человек. На полпути к романтической цели создания "вавилонской рыбки" компания Яна нашла золотую жилу и теперь должна ее разрабатывать. Но это не значит, что задача качественного машинного перевода не будет решена. По крайней мере Давид Ян отступать не собирается