
Внезапно, будучи в полном расцвете сил, маркетинговая лошадка по кличке "Big Data" вдруг приказала долго жить. Gartnerв в августе 2015 года исключил Big Data из числа прорывных технологий (emerging technologies) и удалил ее с графика Hype Cycle. В исследовании, озаглавленном "The Demise of Big Data, Its Lessons and the State of Things to Come" ("Смерть Больших Данных, извлеченные уроки и ситуация в будущем"), говорится, что это было сделано, чтобы перевести дискуссию о Больших Данных из области спекуляций в практическую плоскость. В утешение нам, скорбящим по Big Data, аналитики говорят, что эта технология просто уже выросла из "цикла ажиотажа" и, дескать, перешла в следующий класс - в класс технологий продуктивного использования. Ведь никто же не говорит сегодня о реляционных СУБД или WiFi, но все этими вещами пользуются. Не волнуйтесь, граждане, жива ваша Big Data.
Гм. Как-то не верится. С кривой Hype Cycle есть два выхода: первый - это когда технология действительно достигает плато продуктивности и за ней престают следить так пристально - как за повзрослевшим ребенком; второй вариант - это когда технология устаревает так и не достигнув стадии зрелости - умерла, так умерла, своего рода естественный отбор. В Hype Cycle Gartner мониторит около 2000 инновационных технологий, и нет ничего необычного, что каждый год какие-то из них погибают - никто не сочиняет по ним пространных некрологов, как мы наблюдаем в случае с Big Data.
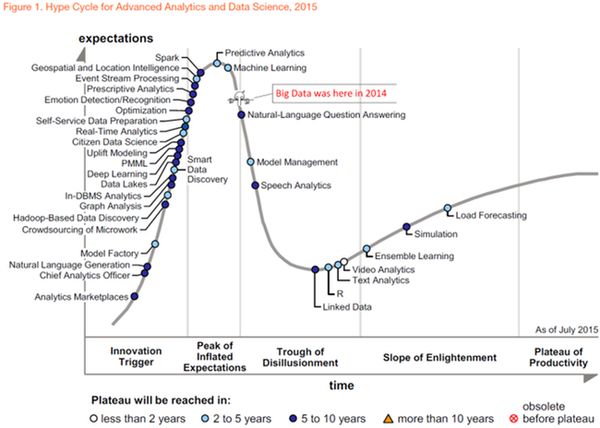
Так что же все-таки произошло? Почему Gartner пустил под нож эту славную лошадку? Ей бы еще скакать и скакать - интерес публики к ней отнюдь не угас. Это мы видим на графике GoogleTrends: рост числа запросов стабилизировался, но признаков падения еще нет.
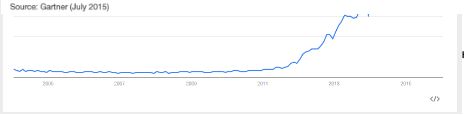
Ну, да, пик популярности миновал, Big Data стала потихоньку спускаться в долину разочарованя (Trough of Disillusionment-букв. 'корыто разочарования'), но это еще не приговор. Многие проходят фазу столкновения с суровой реальностью после эйфории от всеобщего внимания и все-таки попадают на плато продуктивности. Могла бы и Big Data спокойно себе развиваться - но нет же! Зачем-то понадобилось объявить на весь мир о ее кончине.
Зонтик оказался слишком большим
Возможно, дело в том, что Big Data - это типичный зонтичный термин, и в какой-то момент стало ясно, что зонтик оказался слишком большим. На волне ажиотажа все, что угодно стали относить к Big Data - все, что связано с хранением и анализом данных, лишь бы попасть в модный тренд. Разумеется, в отсутствие точных определений базового термина и стека технологий нельзя обозначить и четкие границы рынка, а, следовательно, невозможно строить сколько-нибудь ответственные прогнозы. Может быть поэтому - чтобы не оказаться в какой-нибудь неловкой ситуации из-за слишком широкой трактовки самого понятия Big Data, аналитики Gartner и решили от него избавиться. ( Это моя гипотеза. )
Кстати, Джон Мэши (JohnR. Mashey), Chief Scientist, SGI, который в 1998 году одним из первых ввел в обиход термин Big Data , вообще не считал это какой-то особенной своей заслугой: "Это слишком простой термин - я использовал один ярлык для очень разных вещей, и мне хотелось наиболее простой и емкой фразой передать, что границы возможностей компьютеров постоянно расширяются."
Что ж, термин действительно оказался очень емким и прилипчивым - о Больших Данных вдруг заговорили даже те, у кого их кот наплакал, какие-то сотни гигабайт. Данные растут! Сенсация! На стенку лезет пресса! О Big Data стали писать специализированные и деловые издания, даже гламурные журналы. Вполне закономерно, что это привело к профанации термина, и серьезные заказчики стали его чураться. Наступила полная путаница - BI это тоже Big Data или нет? Хранилища данных и аналитические инструменты - это один рынок или разные? И так далее. В итоге, в Gartner решили с 2015 года выпускать пять отдельных "циклов ажиотажа", которые более четко очерчивают несколько предметных областей, связанных с хранением, управлением и анализом данных:
• Advanced Analytics and Data Science;
• Business Intelligence and Analytics;
• Enterprise Information Management;
• In-Memory Computing Technology;
• Information Infrastructure.
Пусть это выглядит более скучно, чем Big Data, но так будет лучше. Только едва ли публика так легко расстанется с полюбившейся ей игрушкой. Big Data = Big Marketing. Мы еще много-много-много раз услышим знакомые заклинания, что нас окружают пета-экза-зетта-йота-байты и надо с этим что-то делать!
Иллюзия простоты: любой вопрос - любой ответ
Вторая беда с Big Data была в ее обманчивой простоте. По крайней мере так это преподносилось широкой аудитории. Возьмите все ваши данные, загрузите в Hadoop (благо он бесплатный) и наслаждайтесь - скрытые прежде закономерности проявятся сами собой.
Помните, на заре Big Data, году в 2008 появился сервис Google Flu Trends (GFT), который вроде как регистрировал начало эпидемии гриппа быстрее и точнее, чем врачи? В его основе лежало предположение, что, когда приходит грипп, люди начинаю активно искать в интернете лекарства и статьи про способы лечения, поток запросов, связанных с гриппом резко возрастает, а из анализа этих данных можно сделать вывод об уровне распространения вируса в каком-то регионе. Красивая идея, но, увы, ложная. Это стало окончательно ясно в 2013 году, когда GFT ошибся с определением пика эпидемии на 140%. И все потому, что под этим не было никакой внятной математической модели, лишь допущения на уровне здравого смысла. Увы, этого недостаточно, чтобы давать точный прогноз. Корпорация Google тихо похоронила проект, а люди - на то они и люди - одни (кто не прочитал свежих публикаций) по-прежнему преподносят GFT как торжество Big Data, а другие - как полный провал. (Например, вот: )
У этой истории есть еще и вторая сторона: кто сказал, что данные медиков абсолютно точны и достоверны? Ведь грипп - это же просто клондайк для фармкомпаний, продавцов марлевых масок и всей структуры здравоохранения. Потому что как только официально объявлена эпидемия, тут же выделяются дополнительные средства из бюджета на борьбу с ней. Как вы, наверное, догадываетесь, есть много возможностей манипулирования статистическими данными, чтобы заинтересованным сторонам добиться нужного результата. А телевидение и СМИ еще больше раскачивают ситуацию. Так что, на самом деле при помощи GFT мы анализируем не распространение вируса, а лишь уровень озабоченности людей гриппом, что далеко не одно и то же. То есть, это инструмент социологии, а не медицины.
Мнимые закономерности на основе статистики
Технологии Big Data действительно позволяют находить разнообразные корреляции в любых данных. Например, что с XVI века до наших дней сильно сократилось число пиратов и одновременно выросла среднегодовая температура. Означает ли это, что численность пиратов влияет на глобальное потепление? Что за чушь! Конечно же нет! Однако, во многих других случаях ответ может быть не столь очевиден - наблюдаем ли мы причинно-следственную связь или случайное совпадение.
Поэтому скажем честно: модели, основанные только на статистике, фактически моделями не являются, ибо они не обладают предсказательной силой. Не надо обманывать себя и других. А что мы видим на рынке Big Data? Сплошь и рядом - якобы научные "модели покупательского поведения", корреляции всего со всем, если человек купил А, он точно купит и Б. Но, позвольте спросить, почему? Так свидетельствуют Большие данные!

Увы, это огромная системная проблема. В общественных и социальных науках, политологии, маркетинге, психологии, экономике, антропологии на самом деле нет сколько-нибудь строгой теории - теории в том смысле, как это понимают физики. "Вся наука - или физика, или коллекционирование марок" - сказал Эрнест Резерфорд, когда получил известие о присуждении ему Нобелевской премии по химии в 1908 году. И он был абсолютно прав.
Ведь, как известно, нет ничего практичнее хорошей теории! Поэтому все эти забавы с цифрами могут дать результат, который совпадет с реальностью лишь по воле случая. Например, из графика прошлых колебаний цены на нефть совершенно не следует, какой она окажется в будущем. (Просто ради интереса - сравните прогнозы аналитиков с фактическими данными. Будет 50/50, если не хуже.)
Отлично показывает ущербность статистических моделей Нассим Талеб, рассказывая об ошибке индюшки: "Мясник откармливает индюшку тысячу дней; с каждым днем аналитики все больше убеждаются в том, что мясники любят индюшек "с возрастающей статистической достоверностью". Мясник продолжает откармливать индюшку, пока до Дня благодарения не останется несколько суток. Тут мясник преподносит индюшке сюрприз, и она вынуждена пересмотреть свои теории - именно тогда, когда уверенность в том, что мясник любит индюшку, достигла апогея и жизнь индюшки вроде бы стала спокойной и удивительно предсказуемой."
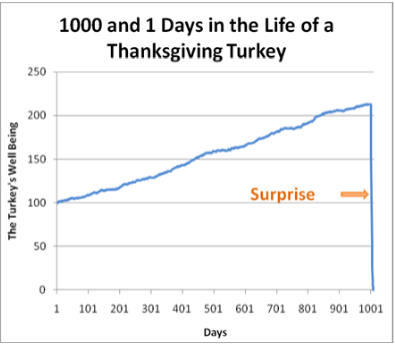
Примерно также себя ощущали владельцы торговых павильонов возле метро до 9 февраля - арендные ставки растут, с мэрией все вопросы решены, все хорошо. А тут бац! - и бульдозеры. Могла бы Big Data предсказать такой поворот событий? Вряд ли. Поэтому глядя на красивые модели прежде всего стоит поинтересоваться, на основании какой теории они построены. Или хотя бы гипотезы.
К счастью, надежда, что вслед за физикой и другие науки обретут прочный теоретический фундамент, все-таки есть. Станислав Лем в "Сумме технологии" еще в начале 1960-х годов писал: "Общая тенденция математизации наук (в том числе и таких, которые до сих пор по традиции не использовали математических средств), охватив биологию, психологию и медицину, постепенно проникает даже в гуманитарные области - правда, пока еще скорее в виде отдельных "партизанских налетов"; это можно заметить, например, в области языкознания (теоретическая лингвистика) или теории литературы (применение теории информации к исследованию литературных, в частности поэтических, текстов)."
Без математической модели не добудешь ответ из озера данных
Без труда не выловишь и рыбку из пруда - пока не построишь математическую модель явления или предметной области, никаких достоверных ответов из озер данных не получишь. Вообще говоря, озера данных (data lakes) продвигаются поставщиками как платформы управления данными масштаба предприятия, чтобы анализировать данные из различных источников в нативном формате, говорит Ник Эудекер (Nick Heudecker), директор по исследованиям Gartner. Идея очень проста: вместо того, чтобы загружать данные в специализированное хранилище, можно слить их в "озеро" в формате, в котором они поступили из внешних систем. Это сильно удешевляет проект и избавляет нас от сложностей, связанных с очисткой и трансформацией. А дальше кто угодно может их анализировать, пользуясь палочкой-выручалочкой Big Data. Красиво, да?
Следует сказать, что компании недооценивают риски такого подхода. К 2018 году 90% внедренных озер данных будут бесполезны потому что они будут переполнены информацией, собранной неизвестно с какой целью. (Gartner, Strategic Planning Assumption, Gartner BI Summit, 2015). Данные в озере могут быть неконсистентны и не иметь метаданных, поэтому реально только очень опытные аналитики, хорошо знающие контекст, смогут сливать и согласовывать данные из разных источников. Однако, это уже какая-то алхимия. Сегодня мы получим один ответ на свой запрос, а завтра может быть другой - в зависимости от квалификации и настроения аналитика. Можно ли принимать серьезные бизнес-решения на такой зыбкой почве? Не думаю. Прежде, чем вбрасывать аналитические данные в контур управления, нужно разработать математическую модель, которая поможет эти данные правильно интерпретировать. Иначе не получится ничего, кроме игрушек для менеджеров - а ну-ка построим такой график, а теперь другой!
Самая сексуальная работа 21-го века
Логично, что наблюдается большой спрос на специалистов по Data Science. Средняя зарплата "ученого по данным", согласно исследованию Glassdoor, составляет 114 808 долларов, тогда как средняя зарплата обычного статистика находится на уровне 75 000 долл. McKinsey предсказывает, что к 2018 году США столкнутся с нехваткой 190 тысяч data scientists и 1.5 миллиона менеджеров с навыками использования аналитических данных для принятия бизнес-решений. Сегодня дефицит этих специалистов так велик, что на работу берут и без профильного образования по математике и программированию. Harvard Business Review назвал работу ученого по данным самой сексуальной работой 21-го века . В корпорациях даже появились должности директоров по данным и аналитике - chief data officers или chief analytics officers.
Поскольку работа эта новая, какого-либо канонического определения, кто такой data scientist и тем более профессионального стандарта еще не сформировалось. Некоторые шутят, что data scientist-это аналитик, живущий в Калифорнии, но вообще-то требования к этим специалистам различаются, аналитик и "ученый по данным" - это не одно и то же. Объединяет же их академическое любопытство, способность делать выводы и доходчиво о них рассказывать.
Правда, злые языки предрекают, что уже к 2025 году все эти хипстеры от Big Data, получающие сейчас большие деньги, останутся без работы. Аналитиков-людей заменит искусственный интеллект - и целая армия новоиспеченных data scientists вовсе не понадобится. Ну, поживем - увидим.
Почему все-таки данные большие?
Как известно, Big Data характеризуется тремя "V": Volume, Velocity, Variety - объем, скорость, разнообразие. Первым, определяющим параметром идет объем. Но откуда пошла такая мода говорить о Больших данных?
С этим как раз все просто. В конце 90-х разработчики систем визуализации в Silicon Graphics, которая на тот момент была признанным лидером в ИТ-индустрии и выполняла множество заказов для студии Disney, NASA и других клиентов, столкнулись с тем, что данные не помещались в оперативной памяти, а при обращении к диску все начинало тормозить и нельзя было выдать качественную видео-картинку, даже если использовать самые мощные по тем временам рабочие станции.
В 1997 году на 8-й конференции IEEE по визуализации Майкл Кокс и Дэвид Эллсворс (Michael Coxand David Ellsworth) из NASA делали доклад о своей работе по вычислительной гидродинамике. Им нужно было показывать результаты расчетов на экране, для чего приходилось идти на различные ухищрения - об этом и была их статья "Application-controlled demand paging for out-of-corevisualization" ("Управляемый приложением спрос на подкачку данных вне ядра визуализации"). Вот что они писали: "Визуализация представляет интересный вызов для компьютерных систем: наборы данных в основном настолько велики, что они превосходят емкость основной памяти, локального диска и даже удаленного диска. Мы называем этопроблемой больших данных."
Насколько тогда велики были данные? Собственно, наборы данных, используемые в расчетах Кокса и Эллворса были порядка 100-500 ГБ. А параметры компьютеров SGI смотрите в таблице:

То есть, изначально это была сугубо инженерная проблема - как при ограниченных ресурсах компьютера обеспечить визуализацию различных моделей. И заметьте, что big data тогда писали еще с маленькой буквы!
Тема вычислений в памяти сегодня по-прежнему актуальна, только масштабы выросли. В 2012 году SAP анонсировала самую большую in-memory базу данных HANA объемом 100 ТБ, способную хранить миллиард записей. MarketsandMarkets прогнозирует, что глобальный рынок вычислений в памяти (In-Memory Computing - IMC) вырастет с USD 5.58 млрд. долл. в 2015 до 23.15 млрд. долл. к 2020 году, со среднегодовым приростом (CAGR) порядка 32.9% в течение этого периода. (Это что касается второй 'V' - Velocity.)
Где данных реально много - XLDB
Большинство презентаций на наших конференциях по Big Data повторяет одну и ту же мысль: "давайте анализировать данные о потребителях, чтобы больше продавать". По правде говоря, это как-то мелко - и в прямом, и в переносном смысле. В прямом - потому что объемы данных в коммерции, банкинге или даже в телекоме и рядом не лежали с объемами научных данных. А в переносном - потому что едва ли оправданно тратить столько интеллектуальных усилий на то, чтобы продать лишнюю пачку памперсов.
Действительно огромные массивы данных вы найдете не в бизнесе, а в Большой науке - это астрономия, физика, науки о Земле, науки о жизни. Новые инструменты научных исследований достигли сегодня поистине циклопических размеров и производят невообразимые объемы данных, хранить которые ученые настроены вечно. Например, Large Synoptic Survey Telescope (LSST) с основным зеркалом диаметром 8,4 метра способен заснять всю доступную площадь неба всего за несколько ночей. Телескоп снабжен 3.3 Гигапиксельной цифровой камерой, которая за ночь производит 30 ТБ данных, а за все время работы накоплен архив более чем 200 ПБ!
Но это еще цветочки. Возьмем Большой адронный коллайдер (LHC). Его главный детектор ATLAS (A Toroidal LHC ApparatuS) при всех своих гигантских размерах (длина 46 метров, диаметр 25 метров и вес 7000 тонн) еще генерит данные с фантастической производительностью. Одно событие (то есть, столкновение частиц) дает нам примерно 25 МБ данных. Вроде немного, да? Но событий этих - 40 миллионов в секунду! Итого мы имеем 1 ПБ сырых данных в секунду. Разумеется, такой поток информации мы не в силах записывать в реальном времени, поэтому приходится выбирать, что сохранить для дальнейшего изучения. Но даже если отфильтровать 100 тысяч наиболее интересных событий (в секунду, не забываем, в секунду!) все равно получается около 1 ПБ в год. А подобных датчиков на LHC - семь. Вот и считайте…
Чтобы ответить на этот вызов, в 2007 году команда по масштабируемым системам данным в SLAC, которая как раз отвечала за проектирование и разработку 100-Петабайтного хранилища для телескопа LSST, инициировала организацию на базе Стэнфордского университета сообщества по разработке сверхбольших СУБД (XLDB - Extremely Large Data bases). Точного определения, что значит "сверхбольшие" нет, это как говорят, подвижная цель. По состоянию на сегодня речь идет об объемах порядка нескольких петабайт.
Одним из результатов деятельности этого сообщества стал opensource-проект SciDB - многомерная СУБД для научных, геопространственных, финансовых и промышленных данных, созданная под руководством Майкла Стоунбрекера (Michael Stonebraker), одного из пионеров реляционных баз данных. Стоунбрекер был техническим директором Informix, занимался разработкой Ingres (а потом и Postgres), Illustra, Cohera, StreamBaseSystems, Vertica, VoltDB, TamrиParadigm4.
После 40 лет разработки баз данных, Стоунбекер пришел к выводу, что мир изменился и позиция "один размер для всех" больше не работает, что жизнь не вписывается в реляционную модель. Его SciDB- это пост-реляционная база данных, которая может работать с очень большими массивами информации в распределенных дата-центрах. "В 1980-х "ответом" на все вопросы была обработка бизнес-данных, и это делалось с помощью реляционных баз. Мы старались натянуть SQL на все, что только можно, но это был неестественный путь," - говорит Стоунбекер. Для научных СУБД нужна иная модель. SciDB нативно работает с многомерными массивами и может выполнять над ними алгебраические операции, выигрывая у РСУБД в скорости и эффективности хранения данных. SciDB не использует Map Reduce и совсем не похожа на Hadoop. Причина в том, что операции линейной алгебры весьма трудно реализовать в концепции Map Reduce. SciDB отлично масштабируется и активно используется в больших проектах, типа архива LSST.
От Big Data к продвинутой аналитике
Термины приходят и уходят, не всегда точно отражая суть вещей. Пускай говорить Big Data стало немодно, однако сами задачи никуда не делись - все равно нужно хранить весьма большие объемы данных, управлять ими и, самое главное, - извлекать из них знания, получать ответы на самые разнообразные запросы. Причем делать все нужно максимально быстро. Аналитика как область профессиональной деятельности была, есть и будет. Новые инструменты будут востребованы - и не только статистические. На подходе когнитивные семантические технологии и искусственный интеллект. Да какое там на подходе! Фанаты IBM Watson организуют кампанию по выдвижению его в президенты США!

С другой стороны, будет расширяться круг пользователей, аналитические технологии будут встроены во многие продукты и станут незаметными для людей - как сегодня мы не замечаем, скажем уровень сетевых протоколов и другие инфраструктурные вещи. Они просто есть и работают. Также и аналитика из умственного упражнения для избранных превратится в сугубо утилитарную технологию, тем не менее, пронизывающую все сферы деятельности.
Big Data - феномен культуры
Надо признать, что сейчас Большие Данные стали феноменом массовой культуры - как и Большой взрыв. Но это уже совсем другая история, совсем не про технологии. Эту проблематику начинают осваивать философы - нужно ли нам столько данных и как жить в мире, перенасыщенном информацией. (См. напр. М. Эпштейн " Информационный взрыв и травма постмодерна").
На самом деле история о том, как данные стали большими, началась за много лет до нынешней шумихи вокруг Big Data. Про "информационный взрыв" - это термин впервые был использован в 1941 году, согласно Oxford English Dictionary, начали говорить еще семьдесят лет назад - пишет Джил Пресс (GilPress), колумнист Forbes в статье "Очень короткая история Больших данных" (A Very Short History Of Big Data).
Как ученые раньше работали с информацией? Шестьдесят лет назад - читали все вышедшие статьи; сорок лет назад - все статьи по теме + аннотации в реферативных журналах; двадцать лет назад - все аннотации по теме плюс некоторые статьи. А что можно успеть прочитать сегодня из этой лавины публикаций, которая на нас обрушилась?
Вот вам еще одно новое словечко- "datanami", по аналогии с цунами. Весьма удачное название сайта по Big Data. А что, очень хороший образ для нынешней картины. Может быть, вообще грядет идеальный информационный шторм, кто знает?