
Как все начиналось
Эта история началась 15 лет назад. Работая программистом в столице, я накапливал деньги и увольнялся, чтобы потом создавать собственные проекты. Для экономии средств уезжал домой, в небольшой родной город, где работал над сайтом для студентов, программой для торговли, играми для мобильных телефонов. Но из-за отсутствия опыта ведения бизнеса это не приносило дохода, и вскоре проекты закрывались. Приходилось снова ехать в столицу и устраиваться на работу. Эта история повторилась несколько раз.
Когда у меня в очередной раз закончились деньги, наступил кризис. Я не смог найти работу, ситуация стала критической. Пришло время посмотреть на все вещи трезвым взглядом. Нужно было честно признаться себе, что я не знаю, какие ниши выбрать для бизнеса. Создавать проекты, которые просто нравятся, - путь в никуда.
Единственное, что я умел делать, это приложения для iOS. Несколько лет работы в ИТ-компаниях позволили накопить определенный опыт, и было решено сделать много простых принципиально различных приложений (игры, музыка, рисование, ЗОЖ, изучение языков) и протестировать, в каких нишах будет небольшая конкуренция. Был подготовлен набор классов и библиотек, которые позволяли быстро создавать простые приложения на различную тематику (2d игры, gps-трекеры, простые утилиты и т.д). В большинстве из них было несколько картинок, 2 кнопки и всего одна функция. Но этого было достаточно, чтобы проверить идею и то, насколько легко будет на ней заработать. Например, приложение для бега отслеживало скорость человека, пройденное расстояние, а также подсчитывало калории. На создание сотен простых приложений я потратил полтора года. Такая скорость стала возможной благодаря покупке графики на стоках, а также повторному использованию исходников.
Сначала приложения были бесплатными. Потом я добавил рекламу и встроенные покупки, подобрал ключевые слова и яркие иконки. Приложения начали скачивать.
Когда доход достиг 30 тыс $ / месяц, я решил рассказать товарищу, который работал в большой продуктовой компании, что на тестовых приложениях я смог достичь такой цифры, и предложил создавать их вместе. Он ответил, что у них всего 1 приложение - игра с доходом в 60 тыс $ и 25 тыс пользователей в месяц, против 30 тыс $ выручки и 200 тыс пользователей у меня. Это полностью изменило мои взгляды. Выяснилось, что лучше создать одно качественное приложение, чем сто некачественных
Я понимал, что на качественных можно заработать в десятки раз больше, но я был один в маленьком городе без опыта и команды дизайнеров и маркетологов. Мне требовалось платить за аренду квартиры и зарабатывать на жизнь. Тестовые приложения нужны было просто для проверки рыночных ниш и рекламных стратегий, чтобы научиться, какие приложения и как именно создавать. Просто сложилось, что некоторые из них начали приносить неплохой доход. Сейчас тема простых приложений давно умерла, и там больших денег уже не заработать.
Некоторые приложения сильно отличались по прибыли - это были переводчики, приложения для грузоперевозок, музыкальные программы (которые симулируют игру на пианино, барабанах или, например, гитарные аккорды, плееры), а также простые логические игры.
Тестируя различные виды игр, я понимал, что игры с большой длиной сессии и вовлечением пользователей (типа "2048") способны приносить много денег на длинном интервале времени. Но поначалу это было неочевидно. Поэтому я создавал тестовые аппы типа GPS- трекеров для лыжников и в ключевых словах ставил название популярных лыжных курортов типа Куршавеля. А потом радовался, что клик по рекламе приносил 2$. Но это была краткосрочная немасштабируемая стратегия.
Потом я заметил, что буквально за месяц переводчики скачали более 1 млн раз. И это при том, что они находились примерно на 100-й позиции в рейтинге категории.
Музыкальные приложения принесли столько же скачек, но с учетом привлечения пользователей они были менее перспективны. Пользователей для них нужно привлекать по высокочастотным ключевым словам, а их в этой нише не много: тот, кто ищет приложения для гитары, вводит в поиске - "гитара", "бас-гитара", "аккорды" и т.д. Сложно подобрать много синонимов для такой тематики. Таким образом, пользователи сконцентрированы на высокочастотных запросах, и рано или поздно их привлечение будет стоить дорого. В переводчиках все по-другому.
Языков в мире сотни, и люди вводят запрос не только общим словом "переводчик", а несколько слов как решение своей проблемы: "перевести на французский", "переводчик с китайского". Если запросов много, привлекать пользователей можно просто по среднечастотным ключевым словам (ASO). Ниша оказалась перспективной, тем более, сама тема переводов мне нравилась.
Позже было создано около 40 простых переводчиков, где использовался перевод, который предоставлял Google API. Его стоимость была по $ 20 за 1 млн переведенных символов. Постепенно появились улучшенные версии приложений, где я добавил рекламу, встроенные покупки, функцию перевода голоса.
Заработав денег, я переехал в Минск и купил жилье. На то время у меня было 50−70 приложений для перевода и 5 млн скачиваний. Но с ростом пользователей увеличивался расход на платный Google Translate API. Прибыльность бизнеса серьезно снизилась. Платящие пользователи переводили блоки от 1 тыс символов за раз, что заставило ввести лимиты на запрос. Когда они упирались в лимит на перевод, писали плохие отзывы и возвращали деньги. Настал момент, когда 70% выручки уходило на расходы. При больших объемах перевода этот бизнес оказался не такой перспективный. Чтобы окупить расходы, в приложения нужно было добавлять много рекламы, а это всегда отпугивает пользователей. Требовалось сделать свое API для перевода, а это скорее всего будет не дешево.
Я пробовал просить совета и инвестиций у стартапов и ИТ-сообщества, но поддержки не встретил. Большинство людей не понимали, зачем работать на рынке, где уже есть лидер - Google-переводчик.
Помимо Google было еще несколько компаний, которые предоставлял API для перевода. Я был готов заплатить $ 30 тысяч за их лицензии технологий перевода на 40 языков. Это позволило бы мне переводить неограниченное количество раз за фиксированную цену и обслуживать любое количество пользователей на своих серверах. Но мне в ответ называли сумму в несколько раз выше. Это было слишком дорого. Было решено попробовать сделать свою технологию для перевода. Я пробовал привлечь друзей для разработки, но к тому времени у большинства из них уже были семьи, маленькие дети и кредиты. Все хотели стабильности и жизни в свое удовольствие на хорошую ЗП, а не идти в стартап. Также они не понимали, зачем создавать переводчик, если есть Google с крутым навороченным приложением для перевода и API. У меня не было опыта публичных выступлений, харизмы и крутого прототипа приложений, чтобы заинтересовать людей. Аналитика по заработку 300 тыс $ на тестовых приложениях для перевода никого не удивляла.
Я обратился к знакомому, который владеет аутсорс-компанией в Минске. В конце 2016 года он выделил для меня команду. Я рассчитывал, что решу задачу за полгода на базе open-source проектов, чтобы не зависеть по API от Google.
На пути к своему переводчику
Работа началась. В 2016 году мы нашли несколько opensource проектов - Apertium, Joshua и Moses. Это был статистический машинный перевод, подходящий для несложных текстов. Эти проекты поддерживали от 3 до 40 человек, и чтобы получить ответ на вопрос по ним, требовалось много времени. После того как разобрались и все-таки запустили их на тесты, стало ясно, что нужны мощные сервера и качественные датасеты, которые стоят дорого. Даже после того, как мы потратили деньги на железо и качественный датасет на одну из пар перевода, качество оставляло желать лучшего.
Технически все не сводилось к схеме "скачать датасет и натренировать". Оказалось, что есть миллион нюансов, о которых мы даже не подозревали. Перепробовали еще несколько ресурсов, но хороших результатов не добились. А Google и Microsoft свои наработки не раскрывают. Тем не менее, работа продолжалась, периодически подключались фрилансеры.
В марте 2017 года мы наткнулись на проект под названием Оpen NMT. Это совместная разработка компании Systran, одного из лидеров на рынке машинного перевода, и университета Гарварда. Проект только стартовал и предлагал перевод уже на базе новой технологии - нейронных сетей.
Современные технологии машинного перевода принадлежат большим компаниям, они закрыты. Мелкие игроки, понимая, как сложно внедриться в этот мир, таких попыток не предпринимают. Это тормозит развитие рынка. Качество перевода среди лидеров не сильно отличалось друг от друга долгое время. Очевидно, что и крупные компании столкнулись с дефицитом энтузиастов, научных работ, стартапов и opensource проектов, чтобы брать новые идеи и нанимать людей.
Поэтому Systran сделала принципиально новый маневр: выложила свои наработки в opensource, чтобы такие энтузиасты, как я, могли включиться в эту работу. Они создали форум, где их специалисты стали бесплатно помогать новичкам. И это принесло хорошую отдачу: начали появляться стартапы, научные работы по переводу, так как каждый мог взять основу и на базе нее проводить свои эксперименты. Systran стал во главе этого сообщества. Потом подключились другие компании.
В то время ещё не было повсеместного нейронного перевода, а Оpen NMT предлагал наработки в этой области, выигрывая по качеству у статистического машинного перевода. Я и другие ребята по всему миру могли взять эти технологии и спросить совета у специалистов. Они охотно делились опытом, и это позволило мне понять, в каком направлении двигаться.
Мы взяли OpenNMT за основу. Это происходило в начале 2017 года, когда он был еще "сырым" и не содержал ничего кроме базовых функций. Все это было на Lua (Torch), чисто для академических исследований. Обнаруживалось много багов, все работало медленно, нестабильно и крешилось при небольшой нагрузке. Для production он вообще не годился. Потом в общем чате мы все вместе тестировали, ловили ошибки, делились идеями, постепенно повышая стабильность (тогда нас было около 100 человек). Сначала я удивлялся: как же так, зачем Systran растит себе конкурентов? Но со временем понял правила игры, когда все больше компаний начали выкладывать свои наработки по обработке естественного языка в opensource.
Даже если у всех есть вычислительные мощности, чтобы обрабатывать большие датасеты, то вопрос с поиском специалистов по NLP (обработка естественного языка) на рынке стоит остро. В 2017 году эта тема была намного менее развита, чем обработка изображений и видео. Меньше датасетов, научных работ, специалистов, фреймворков и прочего. Людей, способных из научных работ по NLP построить бизнес и закрыть какую-либо из локальных ниш, еще меньше. И компаниям верхнего эшелона типа Google, и игрокам поменьше типа Systran нужно получить конкурентное преимущество относительно игроков из своей категории.
Как они решают этот вопрос?
На первый взгляд это кажется странным, но чтобы конкурировать между собой, они решают вводить на рынок новых игроков (конкурентов), а чтобы они там появлялись, нужно раскачать его. Порог входа до сих пор высок, а запрос на технологии обработки речи очень растет (голосовые ассистенты, чат-боты, переводы, распознавание и анализ речи, и т.д.) Нужного количества стартапов, которые можно купить для усиления своих позиции, до сих пор нет.
В открытом доступе публикуются научные работы от команд Google, Facebook, Alibaba. От них же в opensource выкладываются их фреймворки и датасеты. Создаются форумы с ответами на вопросы.
Крупные компании заинтересованы, чтобы такие стартапы, как наш, развивались, захватывали новые ниши и показывали максимальный рост. Они с радостью готовы покупать NLP стартапы для усиления своих больших компаний.
Ведь даже если у тебя на руках все датасеты, алгоритмы и тебе подсказывают, это ещё не значит, что ты сделаешь качественный переводчик или другой стартап в области NLP. А даже если и сделаешь, то далеко не факт, что откусишь большой кусок рынка. Поэтому нужно помочь, и если у кого-то получится, купить или объединиться.
В марте 2018 года Systran пригласила всё сообщество в Париж для обмена опытом, а также устроила бесплатный мастер-класс по основным проблемам, с которыми сталкиваются стартапы по переводам. Всем было интересно посмотреть друг на друга вживую.
У всех были различные проекты. Кто-то создавал бота для изучения английского языка, с которым можно говорить, как с человеком. Другие использовали openNMT для суммаризации текста. Значительная часть стартапов представляла плагины для SDL Trados Studio, заточенные под определенную тематику (медицина, строительство, металлургия и т.д.) или язык, чтобы помогать переводчикам экономить время на редактуру переведенного текста.
Помимо энтузиастов, в Париж приехали ребята из Ebay и Booking, которые создают переводчик на той же платформе, что и мы, но оптимизированный для перевода описаний аукционов и отелей.
Также в мае 2017 года Facebook выложил свои наработки по машинному переводу Fairseq в open-source вместе с натренированными моделями для тестов. Но мы решили остаться на OpenNMT, наблюдая, как растет сообщество.
История DeepL
В сентябре 2017 года, анализируя конкурентов, я узнал про DeepL. Они в это время только запустились и предоставляли перевод всего на 7 языков. DeepL позиционировался как инструмент для профессиональных переводчиков, помогающий тратить меньше времени на корректуру после машинного перевода. Даже небольшое изменение в качестве перевода позволяет сэкономить много денег для компаний, занимающихся переводами. Они постоянно отслеживают API для машинного перевода от разных поставщиков, так как качество на множестве языковых пар у всех разное и нет единого лидера. Хотя по количеству языков - больше всех у Google.
Чтобы продемонстрировать качество перевода, DeepL решил устроить тесты на некоторых языках.
techcrunch.com/2017/08/29/deepl-schools-other-online-translators-with-clever-machine-learning
Оценка качества проводилась методом слепого тестирования, когда профессиональные переводчики выбирают лучший перевод из Google, Microsoft, DeepL, Facebook. По результатам победил DeepL, жюри оценило его перевод как наиболее "литературный".
Как так получилось?
Основатели DeepL владеют стартапом Linguee - крупнейшей базой ссылок на переведенные тексты. Скорее всего, у них гигантское количество датасетов, собранных парсерами, и чтобы натренировать их, нужна большая вычислительная мощность.
В 2017 году у них вышла статья о том, что они собрали в Исландии суперкомпьютер в 5 петаФлопс (на тот момент он был 23-м по производительности в мире). Натренировать большую качественную модель было лишь делом времени. В том момент казалось, что даже если мы купим качественные датасеты, то все равно никогда не сможем конкурировать с ними, не имея такого супер-компьютера.
Но все изменилось в марте 2018 года. Nvidia выпускает компьютер DGX-2 размером с тумбочку и производительностью в 2 петаФлопса (FP16), который сейчас можно взять в лизинг от 5000$ / месяц.
www.nvidia.com/en-us/data-center/dgx-2
Имея такой компьютер, можно тренировать свои модели с гигантскими датасетами быстро, а также держать большую нагрузку по API. Это кардинально меняет расклад сил всего рынка стартапов машинного обучения и позволяет небольшим компаниям конкурировать с гигантами в области работы с большими данными. Это было лучшее предложение на рынке в соотношении "цена-производительность".
Я начал искать информацию о статистике DeepL. У Google за 2018 год было 500 миллионов пользователей ежемесячно. У DeepL - 50 миллионов (статья от 12 декабря 2018).
slator.com/ma-and-funding/benchmark-capital-takes-13-6-stake-in-deepl-as-usage-explodes
Получается, что в конце 2018 года 10 % от ежемесячной аудитории Google пользовались DeepL, причем они нигде особо не рекламировались. Чуть более чем за год они захватили 10 % рынка, использую сарафанное радио.
Я задумался. Если DeepL командой в 20 человек победил Google, имея в 2017 году машину в 5 petaFlops, а сейчас можно дешево арендовать машину в 2 petaFlops и купить качественные датасеты, насколько будет сложно добиться качества Google?
Lingvanex Control Panel
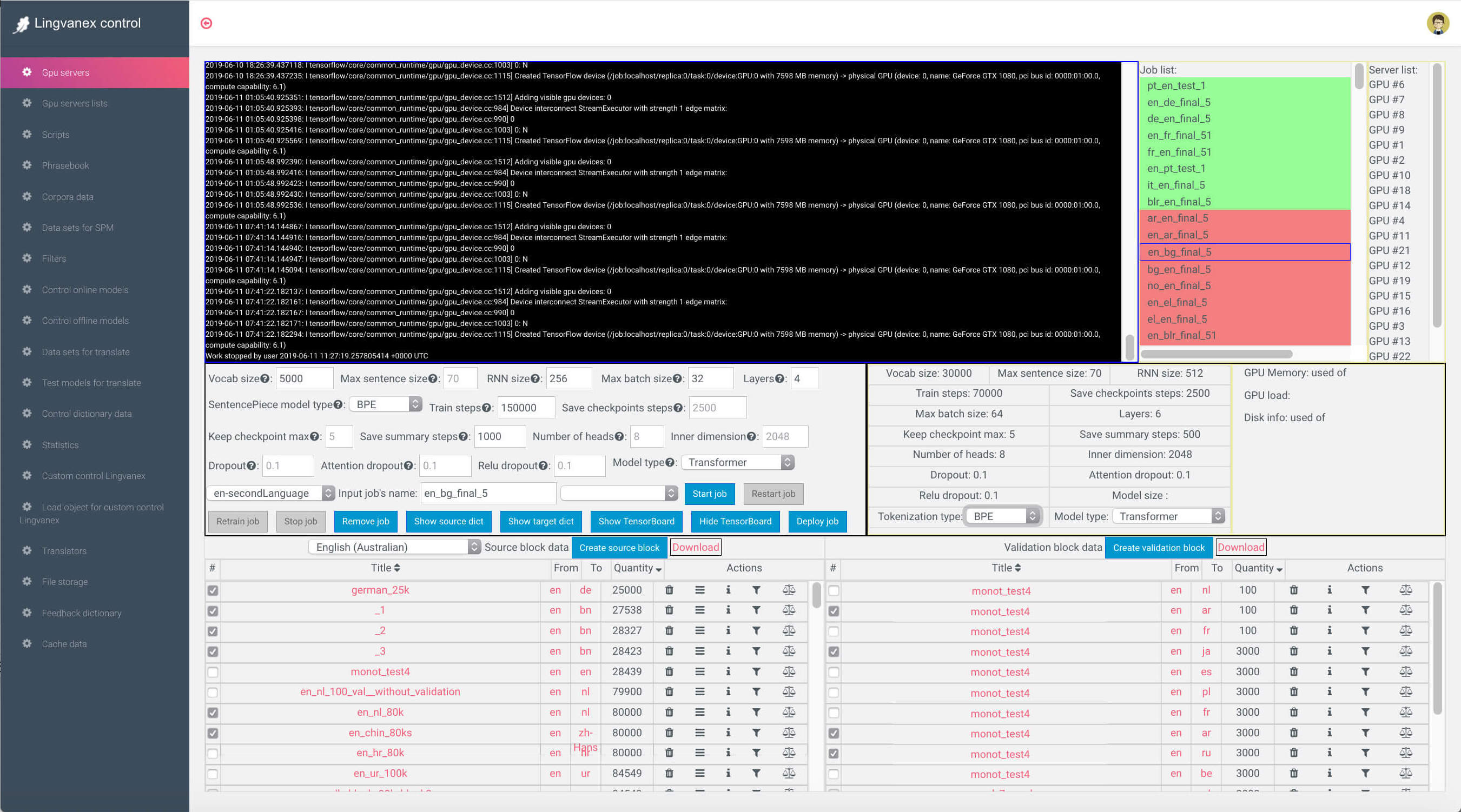
Чтобы быстро разбираться с задачами перевода и не запускать тесты из консоли, был сделан Dashboard, который позволял делать все задачи, начиная от подготовки и фильтрации данных до деплоя тестов перевода на Production. На картинке ниже: cправа - список задач и GPU-серверов, на которых идет тренировка моделей. По центру - параметры нейронной сети, а снизу - датасеты, которые пойдут на тренировку.
Работа над новым языком начиналась с подготовки датасета. Мы брали их из открытых источников типа Wikipedia, заседания Европарламента, Paracrawl, Tatoeba и др. Чтобы получить среднее качество перевода, достаточно 5 миллионов переведенных строк.
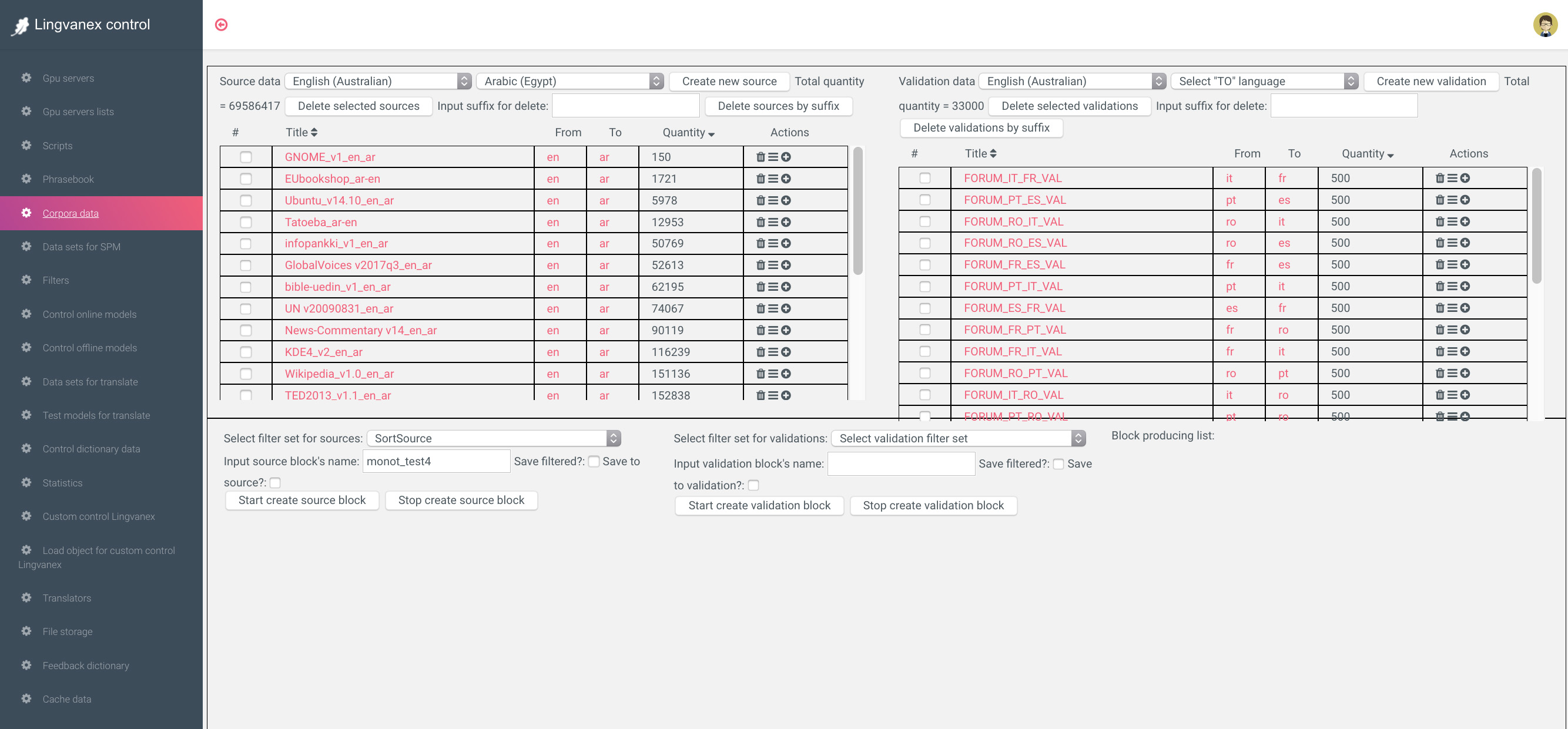
Датасеты представляют собой строки текста, переведенного c одного языка на другой. Потом токенизатор разделяет текст на токены и создает из них словари, отсортированные по частоте встречания токена. Токеном могут быть как единичные символы, слоги, так и целые слова.
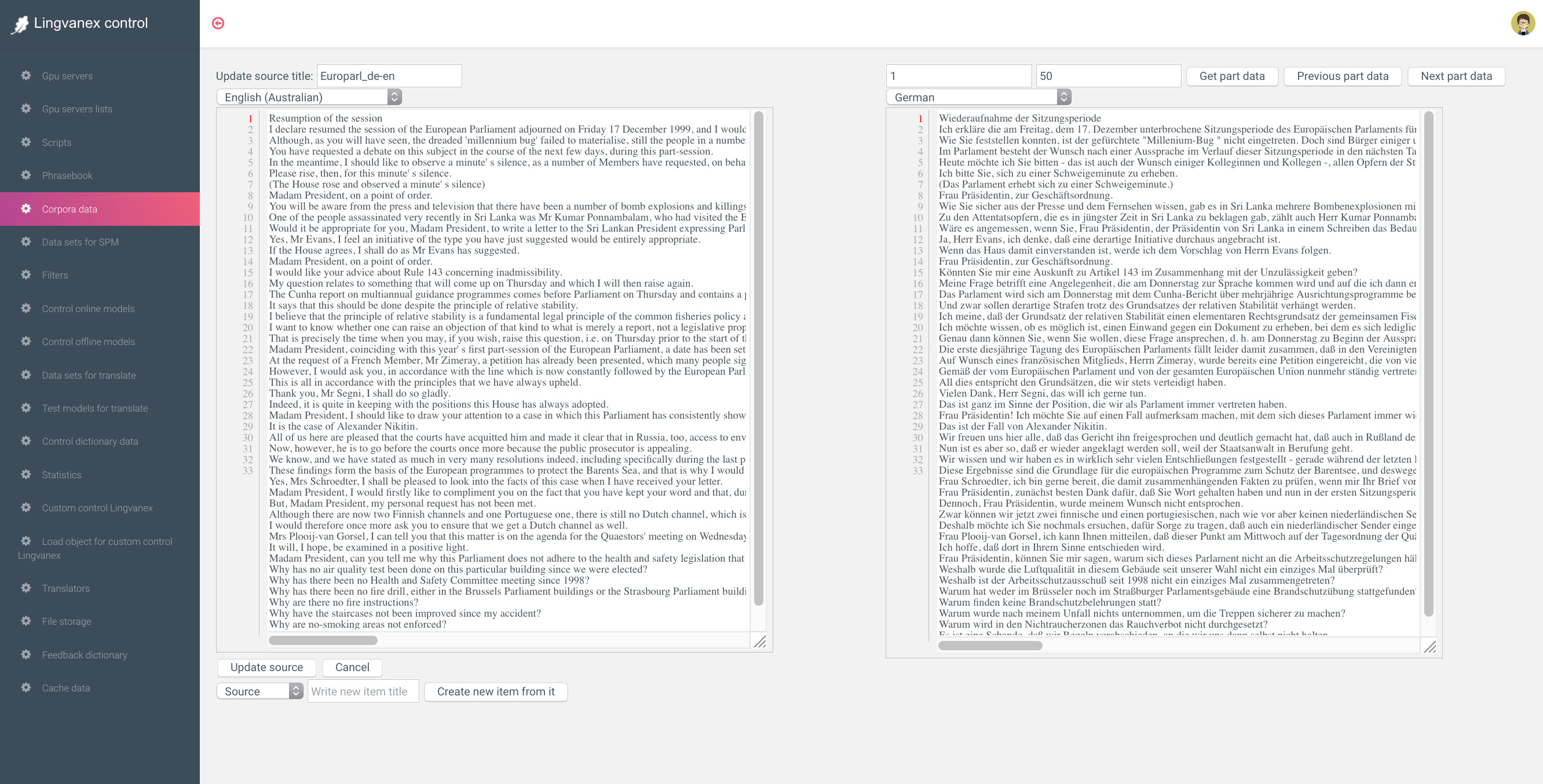
После того как загрузили датасеты в БД, в них оказалось очень много слов с ошибками или с некачественным переводом. Чтобы добиться хорошего качества, их нужно сильно фильтровать. Также можно купить уже качественные отфильтрованные датасеты.
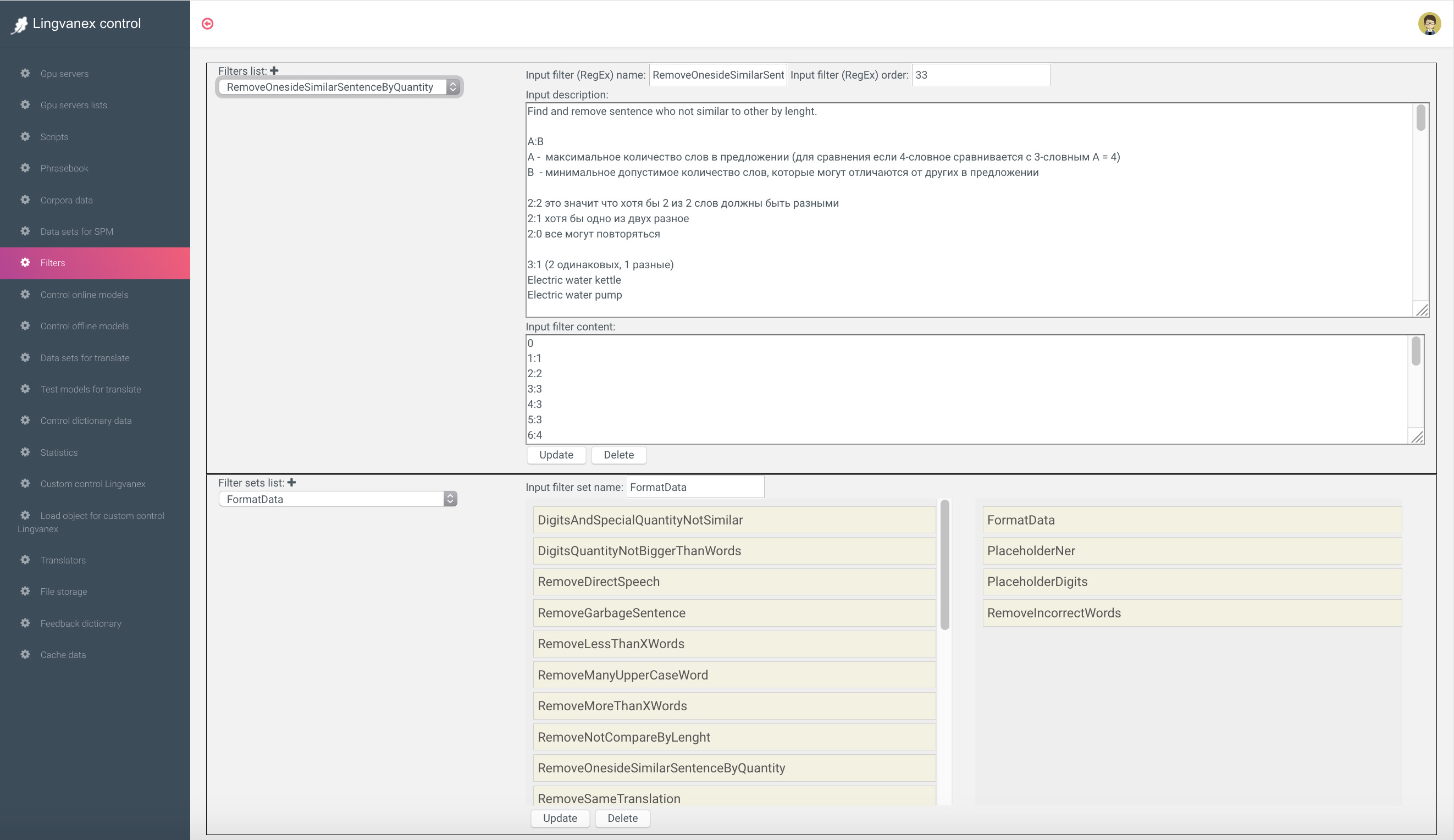
Когда язык развернут на API, нужно установить для него список доступных функций (распознавание голоса, синтез речи, распознавание картинки, парсер файла, сайта и др.). Для работы функций используется стороннее API часть opensource - часть third-parties.
Потом это все разворачивается на API. Со временем был добавлен кеш. Он хорошо работает на 1- и 2-словных фразах и позволяет экономить до 30% запросов.
Продолжаем работу
Весь 2018 год я потратил на решение проблемы качественного перевода на основных европейских языках. Думал, что ещё полгода - и всё получится. Я был очень ограничен в ресурсах, задачами по Data Science занималось всего 2 человека. Нужно было двигаться быстро. Казалось, что решение проблемы в чем-то простом. Но светлый момент всё не наступал, я не был доволен качеством перевода. Было потрачено уже около 450 тыс $, заработанных на старых переводчиках, и требовалось принимать решение, как быть дальше. Запуская этот проект в одиночку и без инвестиций, я понял, сколько управленческих ошибок совершил. Но решение принято - идти до конца!
В это время я заметил, что в нашем сообществе начали говорить про новую архитектуру для нейросетей - Transformer. Все бросились тренировать нейронные сети на базе этой Трансформер-модели и стали переходить на Python (Tensorflow) вместо старой Lua (Torch) Я решил тоже попробовать.
Также мы взяли новый токенизатор, сделали препоцессинг текста, по-другому стали фильтровать и размечать данные, иначе обрабатывать текст после перевода, чтобы исправлять ошибки. Сработало правило 10 тысяч часов: было много шажков к цели, и в определённый момент я понял, что качество перевода уже достаточно для того чтобы использовать его в API для собственных приложений. Каждое изменение добавляло 2-4% качества, которых не хватало для критической массы и при которой люди продолжают пользоваться продуктом, не уходя к конкурентам.
Потом мы начали подключать различные инструменты, которые позволяли и дальше улучшать качество перевода: определитель именованных сущностей, транслитерацию, тематические словари, систему исправления ошибок в словах. За 5 месяцев этой работы качество переводов на некоторых языках стало значительно лучше и люди начали меньше жаловаться. Это был переломный момент. Ты уже можешь продать программу, и из-за того что у тебя есть свое API для перевода, можно сильно сократить расходы. Можно наращивать продажи или количество пользователей, ведь расходы будут только на сервера.
Для обучения нейронной сети нужен был хороший компьютер. Но мы экономили. Сначала мы арендовали 20 обычных компьютеров (с одной GTX 1080) и одновременно запускали на них 20 простых тестов через Lingvanex Control Panel. На каждый тест уходило по неделе, это было долго. Чтобы добиться лучшего качества, нужно было запускать с другими параметрами, которые требовали больше ресурсов. Требовалось облако и больше видеокарт на одной машине. Мы решили взять в аренду облачный сервис Аmazon 8 GPU V100 x 4. Он быстрый, но очень дорогой. Запустили на ночь тест, а утром - счёт на 1200 $. В то время было очень мало вариантов аренды мощных GPU сервероров, кроме него. Пришлось отказаться от этой идеи и искать варианты дешевле. Может, попробовать собрать свой?
Обзвон компаний заканчивался тем, что мы сами должны были прислать детальную конфигурацию, а они его соберут. Что лучше с точки зрения "производительность / цена" для наших задач, никто не мог ответить. Попытались заказать в Москве - наткнулись на какую-то подозрительную фирму. Сайт был качественный, отдел продаж - в теме. Но банковский перевод они не принимали, и единственным вариантом оплаты был скинуть деньги на карту их бухгалтеру. Стали совещаться с командой и решили, что можно самостоятельно собрать компьютер из нескольких мощных GPU и ценой до 10 тысяч долларов, который будет решать наши задачи и окупится за месяц. Комплектующие буквально скребли по сусекам: звонили в Москву, что-то заказывали в Китае, что-то в Амстердаме. Через месяц все было готово.
В начале 2019 у себя дома я наконец-таки собрал этот компьютер и начал проводить много тестов, не беспокоясь, что нужно платить за аренду. На испанском языке я начал замечать, что перевод близок к переводу Google по метрике BLEU. Но я не понимал этот язык и на ночь поставил тренироваться модель англо-русского переводчика, чтобы понять, в какой точке нахожусь. Компьютер всю ночь гудел и жарил, спать было невозможно. Нужно было следить, чтобы не было ошибок в консоли, так как периодически все зависало. Утром я запустил тест на перевод 100 предложений с длинами от 1 до 100 слов и увидел, что получился хороший перевод, в том числе на длинных строках. Эта ночь изменила всё. Я увидел свет в конце тоннеля, что все же можно когда-нибудь добиться хорошего качества перевода.
Улучшаем качество приложений
Заработав деньги на iOS переводчике с одной кнопкой и одной функцией, я решил улучшить его качество, а также сделать версию для Android, Mac OS, Windows Desktop. Надеялся, что когда у меня будет свое API, я закончу разработку приложений и зайду на другие рынки. За то время, когда я решал задачу своего API, конкуренты ушли намного вперед. Нужны были какие-то функции, ради которых будут скачивать именно мой переводчик.
Первое, что я решил сделать, это голосовой перевод для мобильных приложений без доступа в интернет. Это было личной проблемой. Например, Вы едете в Германию, скачиваете только немецкий пакет на телефон (400 мб) и получаете перевод с английского на немецкий и обратно. На самом деле, проблема интернета в зарубежных странах стоит остро. Wifi либо нет, либо он запаролен или просто медленный, в итоге им невозможно пользоваться. Хотя качественных приложений переводчиков, которые работают только через интернет, используя API Google, даже в 2017 году были тысячи.
Так как с Lua (Torch)-версией OpenNMT у многих были проблемы ввиду не очень широкой распространенности языка, основатели перенесли логику скрипта translate.lua в C++ версию (CTranslate), которая служила для более удобных экспериментов с переводами. На Lua-версии можно было тренировать модели, на C-версии запускать. К маю 2017 года это уже можно было хоть как-то использовать за основу production для приложений.
Мы портировали CTranslate для работы под приложения и выложили все это в opensource.
Вот ссылка на эту ветку:
github.com/hunter-packages/onmt
Портировать CTranslate под разные платформы - это только первый шаг. Нужно было понять, как сделать офлайн модели небольшого размера и нормального качества для работы в телефонах и компьютерах. Первые версии моделей для перевода занимали в оперативной памяти телефона 2GB, что абсолютно никуда не годилось.
Я нашел ребят в Испании с хорошим опытом в области проектов по машинному переводу. Около 3 месяцев мы сообща вели R & D в области уменьшения размера модели нейронки для перевода, чтобы добиться в 150 мб на пару и потом запускать на мобильных телефонах.
Размер нужно было уменьшать таким образом, чтобы в определенный размер словаря (к примеру, 30 тыс слов) вложить как можно больше вариантов по переводу слов разных длин и тематик.
Позже результат наших исследований был выложен в открытый доступ и представлен на Европейской ассоциации машинного перевода в г. Аликанте (Испания) в мае 2018 года, а один из членов команды защитил по ней PhD.
На конференции множество человек хотели купить продукт, но пока была готова только одна языковая пара (английский - испанский). Офлайн перевод на нейронках для телефонов был готов уже в марте 2018 года, и можно было сделать его на все остальные языки до лета. Но по договору я не мог получить исходники и используемые для этого инструменты, чтобы сделать офлайн переводчик на других языках. Нужно было внимательно читать договор. В одиночку я не мог быстро воспроизвести результаты на другие языки. Пришлось приостановить эту функцию. Спустя год я вернулся к ней и доделал.
Помимо перевода текста, голоса и картинок, было решено добавить перевод телефонных звонков с транскрипцией, которой не было у конкурентов. Был расчет на то, что люди часто звонят в поддержку или по вопросам бизнеса в разные страны, причем на мобильный или стационарный телефон. Тому, кому адресуется звонок, не нужно устанавливать приложение. Эта функция потребовала много времени и затрат, поэтому позже было решено вынести ее в отдельное от основного приложение. Так появился Phone Call Translator.
У приложений для перевода была одна проблема - ими пользуются не каждый день. Не так много в жизни ситуаций, когда нужно переводить ежедневно. А вот если изучаешь язык, использование переводчика становится частым. Для изучения языков мы создали функцию карточек, когда слова добавляются в закладки на сайте через расширение для браузера или в субтитрах к фильму, а потом происходит закрепление знаний с помощью мобильного приложения чат-бота или приложения для умной колонки, которая будет проверять выбранные слова. Все приложения Lingvanex связаны между собой единым аккаунтом, поэтому можно начать переводить на мобильном приложении и продолжить на компьютере.
Также добавили голосовые чаты с переводом. Это будет полезно для туристических групп, когда гид может говорить на своем языке, а каждый из посетителей будет слушать в переводе. И в конце - перевод больших файлов на телефоне или компьютере.
Проект Backenster
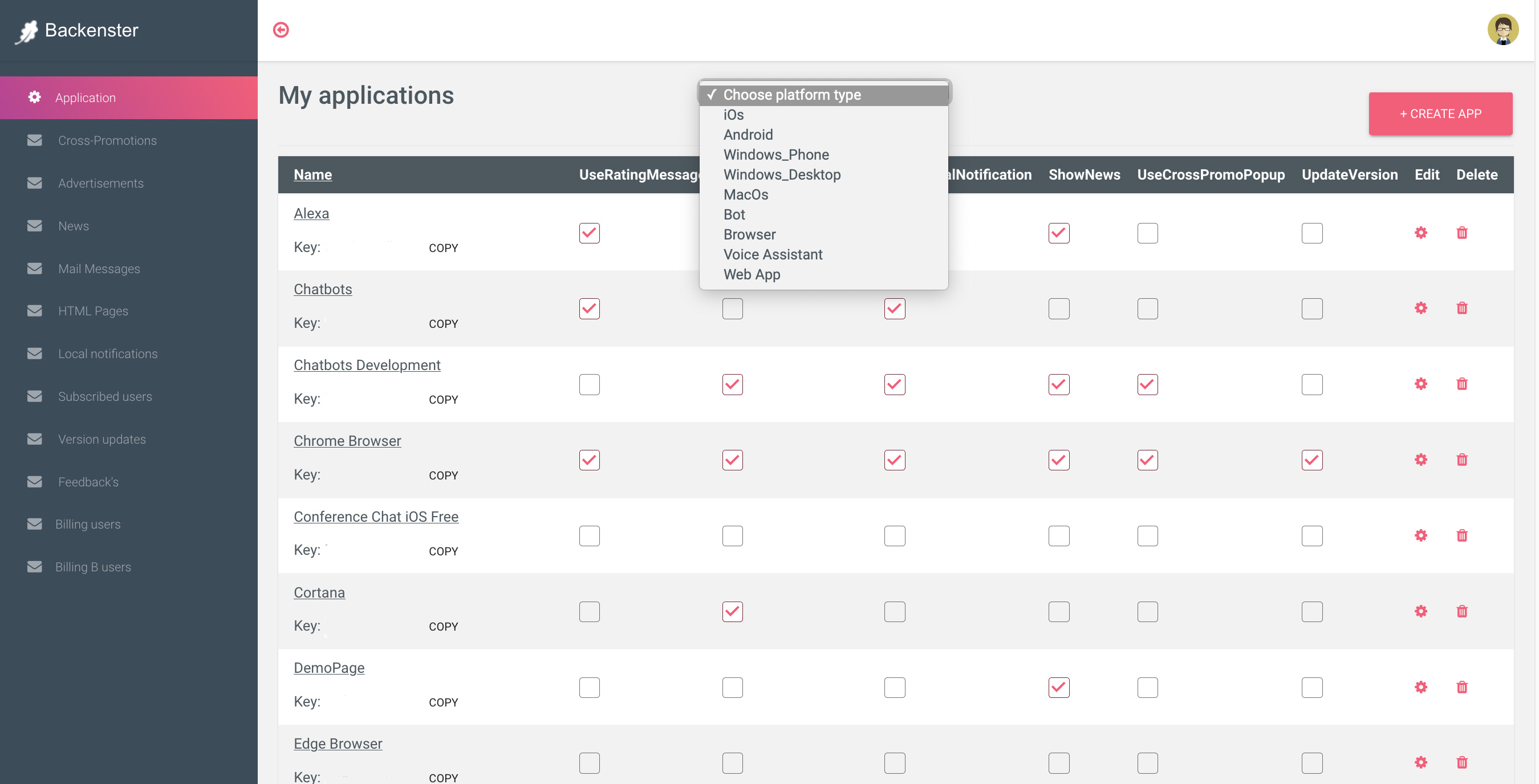
За 7 лет я получил 35 миллионов скачиваний без затрат на рекламу и заработал более 1 млн долларов. Из них почти половина - переводчики. Это были тестовые приложения, чтобы научиться мобильному маркетингу. Из-за большого количества ошибок миллионы пользователей как пришли, так и ушли. Получив необходимый опыт, я принимаю решение создать небольшой внутренний подпроект Backenster для управления приложениями, рекламой и аналитикой, чтобы на качественных переводчиках не повторить ошибок прошлого и зарабатывать максимально.
Через эту систему я собираюсь перенаправить пользователей своих старых приложений-переводчиков в новые, так как на закупку трафика денег уже нет. Еще где-то 5-10 млн старых приложений осталось на телефонах. Когда будут готовы приложения, останется только нажать "Старт". Это обойдется в разы дешевле, чем привлекать то же количество пользователей платно. Постепенно добавилась система управления тестами, подписками, обновлениями, конфигурацией, уведомлениями, медиатор рекламы и др., а также возможность делать кросс-рекламу мобильных приложений в расширениях браузера, чатботах, десктоп, голосовых ассистентах и наоборот. Я решил предусмотреть все проблемы, которые возникли за это время с приложениями.
Перспектива и стратегия
Создавая API для своих приложений и вложив кучу денег, нужно понимать объем и перспективы рынка машинного перевода. В 2017 году был прогноз, что рынок к 2023 году станет 1.5 млрд $, хотя объем рынка всех переводов будет 70 млрд $ (на 2023 год).
Почему такая разбежка - около 50 раз?
Допустим, лучший машинный переводчик сейчас переводит хорошо 80% текста. Остальные 20% нужно редактировать человеку. Самое большие расходы в переводе - это корректура, то есть зарплаты людей.
Увеличение качества перевода даже на 1% (до 81% в нашем примере) может образно на 1% сократить расходы на корректуру текста. 1% от разницы между рынком всех переводов за вычетом машинного будет (70 - 1.5 = 68.5 млдрд $) или 685 млн $ уже. Цифры и расчет выше даны приблизительно, чтобы передать суть.
То есть улучшение качества даже на 1% позволяет значительно сэкономить большим компаниям на услугах перевода. По мере развития качества машинного перевода все большая его часть будет заменять рынок ручного перевода и экономить на расходах по зарплате. Не обязательно стараться охватить все языки, можно выбрать популярную пару (англо-испанский) и одно из направлений (медицина, металлургия, нефтехимия и др.). 100% качества - идеальный перевод машиной по всем тематикам - недостижим в ближайшее время. А каждый следующий процент улучшения качества будет даваться труднее.
Тем не менее, это не мешает рынку машинного перевода занять значительную часть общего всего рынка к 2023 году (по аналогии как DeepL незаметно отхватил 10% рынка Google), так как большие компании каждый день тестируют API различных переводчиков. И улучшение качества одного из них на процент (для какого-нибудь языка) позволит им экономить много миллионов $.
Стратегия больших компаний по созданию своих наработкок opensouce начала приносить свои плоды. Стало больше стартапов, научных работ и людей в индустрии, что позволило раскачать рынок и добиваться все лучшего качества перевода, повышая прогноз по рынку машинного перевода.
Каждый год проводятся соревнования по задачам NLP, где корпорации, стартапы и университеты соревнуются у кого будет лучше перевод на определенных языковых парах.
Анализируя список победителей, появляется уверенность, что небольшими ресурсами можно добиться отличного результата.
Открытие компании
За несколько лет проект вырос во много раз. Появились приложения не только для мобильных платформ, но и для компьютеров, носимых устройств, мессенджеров, браузеров, голосовых ассистентов. Помимо перевода текста был создан перевод голоса, картинок, файлов, сайтов и телефонных звонков. Вначале я планировал делать свое API для перевода, чтобы использовать только для своих приложений. Но потом решил предложить его всем желающим. Конкуренты ушли вперед, и нужно было не отставать.
До этого времени я управлял всем в одиночку как индивидуальный предприниматель, наняв людей на аутсорсе. Но сложность продукта и количество задач начали быстро расти, и стало очевидно, что нужно делегировать функции и быстро нанимать людей в собственную команду в своем офисе. Я позвонил другу, он уволился с работы и принял решение открыть в марте 2019 года компанию Lingvanex
До этого момента я создавал проект, нигде не рекламируясь, и когда решил собрать свою команду, столкнулся с проблемой поиска. Никто не верил, что это вообще можно сделать, и не понимал зачем. Пришлось собеседовать многих людей и каждому по 3 часа рассказывать о тысячах неочевидных деталей. Когда вышла первая статья о проекте, стало проще. Мне всегда задавали один вопрос:
Первый вопрос всегда звучит "Чем вы лучше Google?"
В данный момент наша цель - добиться качества перевода Google общей тематики на основных европейских и азиатских языках и после этого предоставлять решения для:
1) Перевода текста и сайтов через наше API втрое дешевле конкурентов, предоставляя отличный сервис поддержки и простую интеграцию. Например, стоимость перевода Google $20 за миллион символов, что получается очень дорого при значительных объемах
2) Качественного тематического перевода документов по определенным тематикам (медицина, металлургия, юриспруденция и т.д.) по API, в том числе c интеграцией в инструменты для профессиональных переводчиков (типа SDL Trados)
3) Интеграция в бизнес-процессы предприятий для запуска моделей перевода на их серверах по нашей лицензии. Это позволяет сохранить приватность данных, не зависеть от объема переведенного текста и оптимизировать перевод под специфику конкретной компании.
Можно сделать качество перевода лучше конкурентов на определенные языковые пары или темы. Можно и на все. Это вопрос ресурсов компании. При достаточных инвестициях с этим проблем нет. Что и как делать - известно, просто нужны рабочие руки и деньги.
На самом деле рынок NLP растет очень быстро по мере того, как совершенствуется распознавание, анализ речи, машинный перевод, и может принести хорошую прибыль для небольшой команды. Весь хайп тут начнется через 2-3 года, когда сегодняшняя раскрутка рынка большими компаниями принесет свои плоды. Начнется череда сделок по слиянию / поглощению. Главное в этот момент - иметь хороший продукт с аудиторией, который можно продать.
Итог
За все время тестовые приложения принесли более 1 миллиона долларов, из которых большая часть потрачена на то, чтобы сделать свой переводчик. Сейчас очевидно, что все можно было сделать гораздо дешевле и лучше. Было сделано много управленческих ошибок, но это опыт, а тогда советоваться было не с кем. В статье описана очень маленькая часть этой истории и иногда может быть непонятно, почему принимались те или иные решения. Задавайте вопросы в комментариях.
На данный момент мы не добились качества перевода Google, но я не вижу никаких проблем это сделать если в команде будет хотя бы несколько специалистов по Natural Language Processing.
Сейчас лучше всего наш переводчик работает с английского языка на немецкий, испанский, французский.
Ссылки на новые программы, которые разрабатывались в течении 3 лет и в которые были вложены деньги. Если кто хочет увидеть старые тестовые приложения, про которые шла речь в начале статьи (где были заработаны деньги и 35 млн скачек) - пишите в личку.
Переводчик для iOS
Переводчик для Android
Переводчик для Mac OS
Переводчик для Windows
Переводчик для Chrome
Переводчик для Telegram
По этой ссылке можно найти
Демонстрацию API перевода
Еще в команду нужен продакт-менеджер (мобильные приложения) и программист Python с опытом проектов NLP
Если есть идеи совместных партнерств и предложений - пишите в личку, добавляйте в Facebook, LinkedIn.