Поддержка максимального времени безотказной работы системы становится все более важной для успеха вычислений по требованию (on demand computing). WebSphere MQ является важной частью системы обмена сообщениями промежуточного уровня для содействия ускорению вовлечения предприятия в бизнес по требованию. Проектировщики должны учитывать важность включения WebSphere MQ в конфигурацию повышенной готовности. В этой статье описываются методы достижения повышенной готовности для WebSphere MQ с использованием предоставленной на аппаратном уровне кластеризации и программного обеспечения с открытым исходным кодом.
Введение
WebSphereMQ предоставляет функциональные возможности асинхронного обмена сообщениями и обслуживания очереди с гарантированной, единовременной доставкой сообщений. Использование WebSphere MQ совместно с heartbeat предоставляет возможность дальнейшего улучшения степени готовности менеджеров очереди WebSphere MQ.
В первой части данной серии статей я познакомил вас с концепцией повышенной готовности (high availability - HA) и процессом конфигурирования heartbeat. В этой статье я рассмотрю HA-реализацию для WebSphere MQ в конфигурации холодного резерва с использованием heartbeat. В этой реализации heartbeat обнаруживает возникшую проблему с основным узлом. Это может быть аппаратная или программная проблема. Резервная машина:
- Примет IP-адрес.
- Возьмет контроль над общими дисками, хранящими очередь и файлы журналов регистрации событий менеджера очереди.
- Запустит менеджер очереди и соответствующие процессы.
Для наилучшего усвоения материала вы должны иметь базовые знания WebSphere MQ и кластеров повышенной готовности. Вы должны быть также знакомы с первой статьей этой серии "Программное обеспечение повышенной готовности промежуточного уровня в Linux, часть 1: Heartbeat и Web-сервер Apache".
Реализация HA для WebSphere MQ
Менеджер очереди, который будет использоваться в heartbeat-кластере, должен хранить свои файлы журналов и данные на общих дисках так, чтобы они были доступны сохранившему работоспособность узлу при аварии в системе. Узел с работающим менеджером очереди должен также поддерживать некоторое количество файлов на внутренних дисках. В них входят файлы, относящиеся ко всем менеджерам очереди на узле, например, /var/mqm/mqs.ini, и специализированные для менеджера очереди файлы, используемые для генерирования внутренней управляющей информации. Таким образом, файлы, относящиеся к менеджеру очереди, разделяются между внутренним и общим дисками.
Что касается хранения на общем диске файлов менеджера очереди, существует возможность использовать один общий диск для всех восстановительных данных (журналов и данных), относящихся к менеджеру очереди. Однако для оптимальной производительности в производственных условиях рекомендуется размещать журналы и данные на отдельных файловых системах, для того чтобы их можно было независимо настроить для операций ввода/вывода.
На рисунке 1 показана организация файловой системы для нашего примера. Показанные ссылки были созданы автоматически при помощи командных сценариев, которые будут рассмотрены ниже.
Рисунок 1. Организация файловой системы для менеджера очереди - ha.queue.manager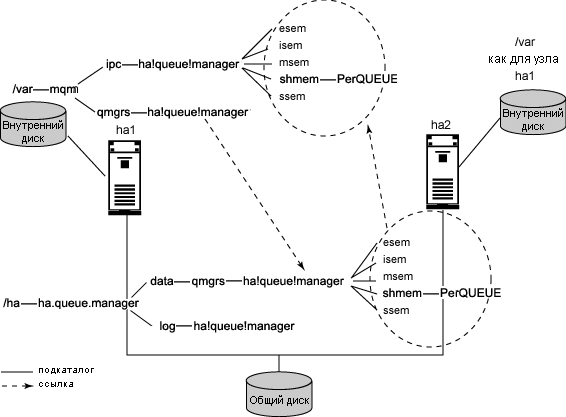
В следующем разделе я приведу пошаговые инструкции по установке WebSphere MQ, созданию и тестированию конфигурации менеджера очереди с повышенной готовностью.
Установка WebSphere MQ
Для установки WebSphere MQ 5.3.0.2 и Fixpack 7 на обоих узлах (основном и резервном) следуйте приведенным ниже инструкциям. Дополнительную информацию можно найти в документе " WebSphere MQ for Linux for Intel and Linux for zSeries Quick Beginnings ":
- Извлеките WebSphere MQ 5.3.0.2 RPM используя следующие команды:
rm -rf /tmp/mq5.3.0.2-installmkdir /tmp/mq5.3.0.2-installtar xzf C48UBML.tar.gz -C /tmp/mq5.3.0.2-install
C48UBML.tar.gz - это файл с установочным образом для WebSphere MQ.tar xf /tmp/mq5.3.0.2-install/MQ53Server_LinuxIntel.tar -C /tmp/mq5.3.0.2-install - Установите уровень ядра:
export LD_ASSUME_KERNEL=2.4.19 - Замените среду времени исполнения Java (JRE), поставляемую с WebSphere MQ, на IBM 1.4.2 JDK JRE:
mv /tmp/mq5.3.0.2-install/lap/jre /tmp/mq5.3.0.2-install/lap/jre.mqln -s /opt/IBMJava2-142/jre /tmp/mq5.3.0.2-install/lap/jre - Подтвердите лицензию:
/tmp/mq5.3.0.2-install/mqlicense.sh -accept -text_only - Установите RPM-пакеты WebSphere MQ:
rpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesRuntime-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesSDK-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesServer-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesClient-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesSamples-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesJava-5.3.0-2.i386.rpmrpm -Uvh /tmp/mq5.3.0.2-install/MQSeriesMan-5.3.0-2.i386.rpm - Очистите каталог:
rm -rf /tmp/mq5.3.0.2-install/ - Извлеките fixpack 7 RPMs:
rm -rf /tmp/mq5.3.0.7-install/mkdir /tmp/mq5.3.0.7-install/tar xzf U496732.nogskit.tar.gz -C /tmp/mq5.3.0.7-install/ - Установите fixpack 7 RPMs:
rpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesRuntime-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesSDK-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesServer-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesClient-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesSamples-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesJava-U496732-5.3.0-7.i386.rpmrpm -Uvh /tmp/mq5.3.0.7-install/MQSeriesMan-U496732-5.3.0-7.i386.rpm - Опять очистите каталог:
rm -rf /tmp/mq5.3.0.7-install/
Создание менеджера очереди повышенной готовности
На некоторых платформах создание менеджера очереди повышенной готовности автоматизировано при помощи сценариев в WebSphere MQ HA Support Packs, например, MC63 и IC61. Однако эти пакеты поддержки недоступны для Linux.
Используемые в данном разделе сценарии являются модифицированными версиями сценариев из вспомогательного пакета MC63 и имеют следующие ограничения:
- Только одна файловая система (filesystem) для журналов и данных (/ha).
- В каждый момент времени работает только один менеджер очереди.
Для создания менеджера очереди повышенной доступности ha.queue.manager следуйте следующим инструкциям:
- Создайте следующие каталоги на общем диске (/ha):
- /ha/ha.queue.manager
- /ha/ha.queue.manager/data
- /ha/ha.queue.manager/log
- На основном узле (ha1) создайте менеджер очереди повышенной готовности при помощи команд, показанных ниже (зарегистрировавшись как root):
Команда/ha/hacode/mq/hascripts/hacrtmqm ha.queue.managerhacrtmqmсоздаст менеджер очереди и обеспечит нужное для разрешения HA-операций размещение его каталогов. Исходный код сценарияhacrtmqmприлагается к этой статье (см. раздел "Загрузка"). - Добавьте следующие две строки в файл .bashrc (начальный сценарий) на обоих узлах для пользователя
mqm.LD_ASSUME_KERNEL=2.4.19export LD_ASSUME_KERNEL - Выполните команду
setmqcap, введя количество процессоров, за которые вы заплатили. Выполните следующую команду на ha1:/opt/mqm/bin/setmqcap 4 - Запустите менеджер очереди ha.queue.manager, используя команду
strmqmи зарегистрировавшись пользователемmqm./opt/mqm/bin/strmqm ha.queue.manager - Разрешите команды MQSC, выполнив:
Сообщение предупредит вас о том, что началась сессия MQSC. MQSC не имеет приглашения командной строки./opt/mqm/bin/runmqsc ha.queue.manager - Создайте локальную очередь HA.QUEUE, введя следующую команду:
define qlocal (HA.QUEUE) - Создайте канал HA.CHANNEL, введя следующую команду:
define channel(HA.CHANNEL) chltype(svrconn) trptype(tcp) mcauser('mqm') - Остановите MQSC, набрав
end. Отобразятся некоторые сообщения и опять появится приглашение командной строки. - Остановите менеджер очереди ha.queue.manager вручную при помощи команды
endmqm:/opt/mqm/bin/endmqm ha.queue.manager - На резервном узле (ha2) создайте менеджер очереди, зарегистрировавшись как пользователь
mqm. Используйте приведенную ниже команду, но в одной строке. Возможно, придется смонтировать /ha как root:
Внутриcd /ha/hacode/mq/hascripts/./halinkmqm ha.queue.manager ha\!queue\!manager/ha/ha.queue.manager/data standbyhacrtmqmиспользует сценарий под названиемhalinkmqmдля повторного присоединения подкаталогов для IPC-ключей и создания символьной ссылки с /var/mqm/qmgrs/$qmgr на каталог /ha/$qmgr/data/qmgrs/$qmgr. Не запускайте сценарийhalinkmqmна узле, на котором вы создали менеджер очереди, используяhacrtmqm, - он уже выполняется на нем. Исходный код сценарияhalinkmqmприлагается к этой статье (в файле, доступном в разделе "Загрузка"). - Выполните команду
setmqcap, введя количество процессоров, за которые вы заплатили:/opt/mqm/bin/setmqcap 4 - Запустите менеджер очереди
ha.queue.manager, используя командуstrmqm, на резервном узле. Убедитесь в том, что он запустился. - Остановите менеджер очереди на основном узле.
Настройка heartbeat для управления WebSphere MQ Server
Пошаговые инструкции для настройки heartbeat для управления MQ-сервером приведены ниже:
- Как упоминалось ранее, управляемые heartbeat ресурсы представляют собой главным образом сценарии start/stop. Вы должны создать сценарии для запуска и останова менеджера очереди WebSphere MQ и всех соответствующих процессов. Очень обобщенный сценарий показан в листинге 1. Вы можете настроить его под ваши требования. Этот сценарий должен быть размещен в каталоге /etc/rc.d/init.d.
#!/bin/bash # # /etc/rc.d/init.d/mqseries # # Starts the MQ Server # # chkconfig: 345 88 57 # description: Runs MQ . /etc/init.d/functions # Source function library. PATH=/usr/bin:/bin:/opt/mqm/bin QMGRS="ha.queue.manager" PS=/bin/ps GREP=/bin/grep SED=/bin/sed #==================================================================== SU="sh" if [ "`whoami`" = "root" ]; then SU="su - mqm" fi #==================================================================== killproc() { # kill the named process(es) pid=`$PS -e / $GREP -w $1 / $SED -e 's/^ *//' -e 's/ .*//'` [ "$pid" != " ] & kill -9 $pid } #==================================================================== start() { for qmgr in $QMGRS ; do export qmgr echo "$0: starting $qmgr" $SU -c "strmqm $qmgr" $SU -c "nohup runmqlsr -m $qmgr -t tcp -p 1414 > /dev/null 2&t;&1 < /dev/null &" done } #==================================================================== stop() { for qmgr in $QMGRS ; do export qmgr echo ending $qmgr killproc runmqlsr $SU -c "endmqm -w $qmgr &" sleep 30 done } case $1 in 'start') start ;; 'stop') stop ;; 'restart') stop start ;; *) echo "usage: $0 {start/stop/restart}" ;; esac - Теперь нужно настроить файл /etc/ha.d/haresources (на обоих узлах) и включить рассмотренный выше сценарий
mqseriesпримерно так:
Это предписывает, что при запуске heartbeat IP-адрес кластера будет назначен узлу ha1, смонтируется общая файловая система /ha, а затем запустятся процессы WebSphere MQ. При останове heartbeat сначала остановит процессы WebSphere MQ, затем размонтирует файловую система и, наконец, освободит IP-адрес.ha1.haw2.ibm.com 9.22.7.46Filesystem::hanfs.haw2.ibm.com:/ha::/ha::nfs::rw,hard mqseries
Тестирование HA для WebSphere MQ
В этом разделе приведены пошаговые инструкции. необходимые для тестирования функций повышенной готовности менеджера очереди ha.queue.manager.
- Запустите службу heartbeat на основном узле, а затем на резервном узле:
Если она не запустится, посмотрите файл /var/log/messages для определения причины и ее устранения. После успешного запуска heartbeat вы должны увидеть новый интерфейс с IP-адресом, который вы указали в файле ha.cf. Вы можете отобразить его, выполнив команду/etc/rc.d/init.d/heartbeat startifconfig. В листинге 2 приведена соответствующая часть отображаемой на экране информации:Листинг 2. Интерфейс для IP-адреса кластера
... eth0:0 Link encap:Ethernet HWaddr 00:D0:59:DA:01:50 inet addr:9.22.7.46 Bcast:9.22.7.127 Mask:255.255.255.128 UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:76541 errors:0 dropped:0 overruns:0 frame:0 TX packets:61411 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:8830515 (8.4 Mb) TX bytes:6755709 (6.4 Mb) Interrupt:11 Base address:0x6400 Memory:c0200000-c0200038 ...
Сразу после запуска heartbeat посмотрите ваш log-файл (по умолчанию /var/log/ha-log) перед тестированием. Если все нормально, log-файл на основной машине (в данном примере ha1) должен быть похож на приведенный в листинге 3 (некоторые строки в целях форматирования приведены с переносом).Листинг 3. Содержимое файла ha-log
... heartbeat: 2004/09/01_11:17:13 info: ************************** heartbeat: 2004/09/01_11:17:13 info: Configuration validated. Starting heartbeat 1.2.2 heartbeat: 2004/09/01_11:17:13 info: heartbeat: version 1.2.2 heartbeat: 2004/09/01_11:17:13 info: Heartbeat generation: 10 heartbeat: 2004/09/01_11:17:13 info: Starting serial heartbeat on tty /dev/ttyS0 (19200 baud) heartbeat: 2004/09/01_11:17:13 info: ping heartbeat started. heartbeat: 2004/09/01_11:17:13 info: pid 9226 locked in memory. heartbeat: 2004/09/01_11:17:13 info: Local status now set to: 'up' heartbeat: 2004/09/01_11:17:14 info: pid 9229 locked in memory. heartbeat: 2004/09/01_11:17:14 info: pid 9230 locked in memory. heartbeat: 2004/09/01_11:17:14 info: pid 9231 locked in memory. heartbeat: 2004/09/01_11:17:14 info: pid 9232 locked in memory. heartbeat: 2004/09/01_11:17:14 info: pid 9233 locked in memory. heartbeat: 2004/09/01_11:17:14 info: Link 9.22.7.1:9.22.7.1 up. heartbeat: 2004/09/01_11:17:14 info: Status update for node 9.22.7.1: status ping ... heartbeat: 2004/09/01_11:19:18 info: Acquiring resource group: ha1.haw2.ibm.com 9.22.7.46 mqseries heartbeat: 2004/09/01_11:19:18 info: Running /etc/ha.d/resource.d/IPaddr 9.22.7.46 start heartbeat: 2004/09/01_11:19:18 info: /sbin/ifconfig eth0:0 9.22.7.46 netmask 255.255.255.128 broadcast 9.22.7.127 heartbeat: 2004/09/01_11:19:18 info: Sending Gratuitous Arp for 9.22.7.46 on eth0:0 [eth0] ... heartbeat: 2004/09/01_11:19:49 info: Running /etc/init.d/mqseries start ...
Вы можете увидеть, что сначала был присвоен IP-адрес, а затем запущены процессы WebSphere MQ. Используйте команду ps для проверки выполнения WebSphere MQ на основном узле. - Поместите несколько сообщений для обязательной доставки в BGQUEUE. Это можно сделать при помощи программы MQ Sender, send.bat или send.sh (в зависимости от вашей операционной системы). Вы должны запустить эту программу на машине, на которой установлен MQ Client. В листинге 4 показана отображаемая информация при запуске на узле ha1.
Листинг 4. Помещение сообщений для обязательной доставки в HA-очередь
[root@ha1 mq]# ./send.sh MSender is running Hostname = ha.haw2.ibm.com QManager = ha.queue.manager Channel Name = HA.CHANNEL Channel Port = 1414 Q = HA.QUEUE Enter a message: Hello This is a test Done Sending Message [root@ha1 mq]#
- Просмотрите и получите все сообщения. Используйте программу MQ Browse, receive.bat или receive.sh (в зависимости от вашей операционной системы). Получите все сообщения, помещенные в очередь ранее, за исключением последнего "test." Последнее сообщение вы получите после аварийного восстановления работоспособности. В листинге 5 приведена отображаемая информация при запуске на узле ha1.
Листинг 5. Получение сообщений для обязательной доставки из HA-очереди
[root@ha1 mq]# ./receive.sh MBrowse is running Hostname = ha.haw2.ibm.com QManager = ha.queue.manager Channel Name = HA.CHANNEL Channel Port = 1414 Q = HA.QUEUE Browsed message: Hello Actually get message?y Actually getting the message Browsed message: This Actually get message?y Actually getting the message Browsed message: is Actually get message?y Actually getting the message Browsed message: a Actually get message?y Actually getting the message Browsed message: test Actually get message?n MQJE001: Completion Code 2, Reason 2033 MQ exception: CC = 2 RC = 2033
Игнорируйте исключительную ситуацию MQ Exception с кодом Reason 2033 в конце. Она возникает из-за того, что нет больше сообщений для получения из очереди. - Сэмулируйте аварию. Это может быть сделано простым остановом heartbeat на основной системе при помощи команды:
Вы должны увидеть, что менее чем через минуту на второй машине запустятся все процессы. Если нет, просмотрите файл /var/log/messages для определения и устранения проблемы. Вы можете восстановить работу на основной машине, повторно запустив heartbeat. Heartbeat всегда будет отдавать предпочтение основной системе и будет запускаться, как только появится возможность. Убедитесь, что WebSphere MQ работает, проверив файл /var/log/ha-log и выполнив команду ps на резервной машине./etc/rc.d/init.d/heartbeat stop - Просмотрите и получите последнее сообщение. Выполните программу MQ Browse, receive.bat или receive.sh (в зависимости от вашей операционной системы). На этот раз вы получите последнее сообщение. В листинге 6 приведена отображаемая на экране узла ha2 информация.
Листинг 6. Получение сообщений для обязательной доставки из HA-очереди
[root@ha2 mq]# ./receive.sh MBrowse is running Hostname = ha.haw2.ibm.com QManager = ha.queue.manager Channel Name = HA.CHANNEL Channel Port = 1414 Q = HA.QUEUE Browsed message: test Actually get message?y Actually getting the message MQJE001: Completion Code 2, Reason 2033 MQ exception: CC = 2 RC = 2033
- Повторно запустите службу heartbeat на основном узле. Это должно остановить процессы WebSphere MQ-сервера на второстепенной системе и запустить их на основной. Основная система должна также взять под свой контроль IP-адрес кластера.
Теперь вы увидели, как при использовании общего диска можно восстановить сообщения, помещенные в очередь перед аварией.
Заключение
В этой части вы узнали, как реализовать повышенную готовность для WebSphere MQ при помощи программного обеспечения с открытыми исходными кодами в операционной системе Linux. В следующей части мы рассмотрим HA-реализацию планировщика IBM LoadLeveler.
- Программное обеспечение повышенной готовности промежуточного уровня в Linux, часть 1: Heartbeat и Web-сервер Apache
- Купить книгу "Офис, графика, Web в Linux" в интернет-магазине ITshop.ru
- Обратиться в Interface Ltd. за дополнительной информацией/по вопросу приобретения продуктов
- Программное обеспечение повышенной готовности промежуточного уровня в Linux, часть 3: IBMLoadLeveler