1. Краткая характеристика ведущих глобальных поисковых машин
1.1. Популярность ведущих мировых поисковых машин
Согласно исследованию агентства Nielsen NetRatings (http://www.nielsen-netratings.com/) в январе 2005 года наблюдалась следующая ситуация на американском рынке поисковых услуг.
| Поисковый сервис | Поисковый движок | Количество запросов (млн.) | % |
|---|---|---|---|
| 1923 | 47,1 | ||
| Yahoo! | Yahoo! Search | 868 | 21,2 |
| MSN | MSN Search | 523 | 12,8 |
| AOL | 194 | 4,7 | |
| Netscape | 75 | 1,8 | |
| Ask | Teoma | 73 | 1,8 |
| My Way | Google, Teoma, Yahoo! Search | 58 | 1,4 |
| iWon | 43 | 1,0 | |
| EarthLink | 37 | 0,9 | |
| My Search | Google, Teoma, Yahoo! Search | 34 | 0,8 |
| прочие | 258 | 6,3 | |
| Итого | 4086 | 100 |
Как следует из таблицы, почти 95% запросов пользователей США обслуживаются четырьмя поисковыми механизмами - Google, Yahoo! Search, MSN Search и Teoma. Причем, на долю первого приходится больше половины всех поисковых запросов, а на долю последнего - менее 2%.
Рассмотрим эти поисковые механизмы подробнее.
1.2. Google (www.google.com)
Самая популярная среди пользователей и имеющая одну из самых больших баз проиндексированных документов (по собственным заявлениям - около 8 млрд.) поисковая система. Поисковый движок был разработан в 1997 году выпускниками Стэндфордского университета Сергеем Брином (Sergey Brin) и Ларри Пейджем (Larry Page), которые применили для ранжирования документов технологию PageRank, где одним из ключевых моментов является определение "авторитетности" конкретного документа на основе информации о документах, ссылающихся на него. Говоря общими словами, чем больше документов ссылается на данный документ и чем они авторитетнее, тем более авторитетным данный документ становится. Количественное значение авторитетности документа (другими словами, взвешенное количество ссылок или PageRank) относится к так называемым статическим факторам (т.е. независящим от конкретного запроса) и учитывается при определении релевантности документа конкретному запросу как весовой коэффициент. Наряду с этим Google применил для определения релевантности документа не только текст самого документа, но и текст ссылок на него. Эта технология позволила ему обеспечить выдачу довольно релевантных результатов на фоне других поисковиков. Довольно быстро Google стал лидировать в различных опросах по такому показателю, как удовлетворенность пользователей результатами поиска. Кроме поиска по HTML документам Google в настоящее время осуществляет поиск еще по другим типам документов, таких как Adobe Portable Document Format (pdf) или Microsoft Word (doc).
Google позволяет пользователям просматривать сохраненные копии документов, содержащихся в его поисковой базе.
Наряду с поиском по документам Google имеет сервисы поиска по изображениям (images.google.com), группам UseNet (groups.google.com), новостям (news.google.com), товарам (froogle.google.com), местный поиск по предприятиям и услугам (local.google.com) и другие поисковые сервисы, а также каталог сайтов (directory.google.com) на основе каталога Open Directory Project (dmoz.org). Google осуществляет поиск по документам на около 100 языках, в том числе русском (русская локализация поисковика находится по адресу www.google.ru). В настоящее время многие порталы и специализированные сайты предоставляют услуги поиска информации в интернете на базе Google, что делает задачу успешного позиционирования сайтов в Google еще более важной. Крупнейшие из них - порталы AOL (www.aol.com), Netscape (www.netscape.com), iWon (www.iwon.com).
Нормированное значение показателя авторитетности PageRank для конкретного документа, загруженного в броузер, можно узнать, скачав и установив Google ToolBar (toolbar.google.com) - специальную панель инструментов для работы с этим поисковиком. Не смотря на то, что в поисковике имеется форма для бесплатного добавления страницы в базу, Google предпочитает сам находить новые документы по ссылкам с уже известных и не будет индексировать добавленную через форму страницу, если в его базе не найдется ни одной страницы, ссылающейся на нее.
Форма бесплатного добавления документов в поисковую базу находится по адресу http://www.google.com/addurl/.
Имеет собственную систему контекстной рекламы в результатах поиска Google AdWords (adwords.google.com).
1.3 Yahoo! Search (search.yahoo.com)
Портал Yahoo! (www.yahoo.com) был основан в 1995 как каталог сайтов. С 2000 года после результатов поиска по каталогу в качестве дополнительных результатов стала появляться выдача поискового движка Inktomi. В 2001 году ее сменили результаты поиска Google, которые с 2002 стали выдаваться по умолчанию вместо результатов поиска по каталогу. В феврале 2004 года Yahoo! прекратил сотрудничество с Google и стал выдавать результаты своего собственного поискового движка. К этому времени Yahoo! были приобретены поисковые движки Inktomi, AllTheWeb и AltaVista, и на их основе и был создан свой собственный механизм поиска.
Наряду с поиском по документам (search.yahoo.com) портал Yahoo! предоставляет возможность поиска по изображениям, видеофайлам, каталогу, товарам, локальным предприятиям и услугам.
Если документ зарегистрирован в каталоге, то в сниппетах поисковой выдачи приводится его каталожное описание.
Результаты поискового механизма Yahoo! Search также транслируются на других поисковых сервисах, крупнейшими из которых являются принадлежащие Yahoo! сервисы AltaVista (www.altavista.com) и AllTheWeb (www.alltheweb.com), некогда имевшие собственные поисковые движки.
Так же, как и в Google, в поисковом движке Yahoo! Search существует понятие авторитетности документа, называемое Yahoo! Web Rank. Непродолжительное время после запуска собственного движка индикатор Yahoo! Web Rank можно было наблюдать, скачав и установив бета-версию Yahoo! Toolbar (toolbar.yahoo.com). Некоторые сайты предлагают сервисы по определению значения Yahoo! Toolbar (например, http://www.digitalpoint.com/tools/webrank/), но за корректность их показаний сложно ручаться.
В поисковую базу новые документы можно бесплатно добавить по адресу http://submit.search.yahoo.com/free/request, однако для этого потребуется пройти процедуру регистрации пользователя. Также есть возможность платной регистрации Search Submit Express, которая гарантирует постоянную 48-часовую переиндексацию документов.
Контекстная реклама в результах поиска осуществляется через собственный сервис Yahoo! Search Marketing (searchmarketing.yahoo.com), который организован на основе системы pay-per-click рекламы Overture, приобретенной порталом Yahoo! в октябре 2003 года.
1.4. MSN Search (search.msn.com)
Поисковый сервис на портале MSN (www.msn.com) появился в 1998 году. До 2004 года он представлял собой трансляцию выдачи поискового сервиса Looksmart, который в свою очередь, в качестве главных результатов предоставлял результаты поиска по собственному каталогу, а в качестве вторичных - выдачу поискового движка Inktomi. В конце 2003 MSN Search отказался от услуг LookSmart и стал транслировать выдачу поискового движка Inktomi, параллельно разрабатывая свой собственный поисковый механизм. Этот механизм был официально введен в эксплуатацию 1 февраля 2005 года и содержит на данный момент более 5 миллиардов документов.
Кроме поиска по документам портал MSN предоставляет возможность поиска по новостям, изображениям, музыкальным файлам и энциклопедическим статьям.
Авторитетность документа, также как и у рассмотренных выше поисковых машин, является одним из ключевых факторов при ранжировании, однако никакой информации о значении этого параметра для конкретного документа не предоставляется пользователю.
Добавление документов в поисковую базу бесплатно и осуществляется с помощью формы, находящейся по адресу http://search.msn.com/docs/submit.aspx.
Контекстная реклама в результатах поиска осуществляется через собственный сервис MSN Advertising (http://advertising.msn.com/) сервис Yahoo! Search Marketing.
1.5. Teoma (www.teoma.com)
Поисковый механизм разработан в 2000 г. При определении авторитетности документа по теме запроса учитывает тематическую популярность (Subject-Specific Popularity), то есть цитируемость документа документами сходной тематики, которая определяется с помощью алгоритма HITS (Hyperlink-Induced Topic Search), разработанного Джоном Клейнбергом (Jon Kleinberg). Этот алгоритм определяет важность страниц по двум критериям - "авторитеты" (authorities), то есть цитируемость другими страницами, и "хабы" (hubs), то есть ссылаемость на другие страницы, затем разбивает страницы на сообщества, каждое из которых представляет одну из возможных тем. Внутри сообщества вычисляется значение "авторитет"-веса каждой страницы как сумма "хаб"-весов, ссылающихся на нее страниц, и "хаб"-веса каждой страницы как сумма "авторитет"-весов цитируемых страниц. Эти значения выступают весовыми коэффициентами при определении релевантности страницы запросу. Однако алгоритм HITS плохо работает для очень конкретных запросов, в этом случае бывает невозможно выделить для них тематическое сообщество, и все документы ранжируются на общих основаниях. Подробное описание алгоритма HITS можно найти в статье Клейнберга "Авторитетные источники в гиперссылочной среде" ("Authoritative Sources in a Hyperlinked Environment", http://www.cs.cornell.edu/home/kleinber/auth.pdf).
Teoma также предлагает пользователю ряд дополнительных сервисов - уточнение запроса в виде несколько ключевых фраз по теме запроса и ссылки на страницы по теме запроса, подготовленные, коллективом экспертов и энтузиастов. В 2001 году Teoma была приобретена компанией Ask Jeeves, и ее поисковые результаты используются довольно популярным в Европе (особенно в Великобритании) поисковым сервисом Ask Jeeves (www.ask.com), что делает ее интересной в свете раскрутки англоязычных сайтов. Русского языка Teoma не поддерживает и для раскрутки сайтов, имеющих только русскоязычную версию, на данный момент совершенно бесполезна.
Специальных возможностей для регистрации документов в Teoma на данный момент не существует. Сервис регистрация и перерегистрация сайтов на платной основе закрыт. Teoma включает в свою базу документы, самостоятельно найденные роботом по ссылкам с уже имеющихся в поисковой базе документов.
Контекстная реклама в результатах поиска осуществляется с помощью сервиса Google AdWords.
1.6. Другие поисковые машины
Из множества глобальных поисковых систем, не являющихся лидерами, можно упомянуть, пожалуй, WiseNut (www.wisenut.com), разработанный в Корее в 2001 году и приобретенный 2002 году компанией LookSmart. Однако популярность WiseNut среди пользователей остается довольно низкой по сравнению с вышеупомянутыми поисковыми машинами.
2. Основные факторы, влияющие на ранжирование
Факторы, оказывающие влияние на соответствие документа тому или иному запросу, можно разделить на следующие:
- Статический (независящий от запроса). Как правило, он носит название ранга или авторитетности документа и зависит от количества и ранга документов, ссылающихся на данный документ.
- Динамические (зависящие от запроса). Их можно разделить на 2 категории:
- Внутренние (страничные). Они учитывают степень соответствия запросу содержимого самого документа.
- Внешние (ссылочные). Один из факторов учитывает степень соответствия запросу текста ссылок на документ (в среде русскоязычных специалистов по оптимизации такой фактор носит название "ссылочное ранжирование"). При этом может учитываться и ранг документа, который содержит текстовую ссылку. Также одним из факторов может быть динамический (т.е. зависящий от запроса) ранг докумена.
Статистический фактор измеряют важность или авторитетность страницы, не обращая внимание на ее содержание. В то время как страничные факторы измеряют собственно релевантность текста страницы, то есть показывают насколько содержимое самой страницы соответствует определенному запросу. Ссылочные факторы измеряют релевантность ссылок на страницу с других страниц, т.е. показывают насколько соответствующей запросу эта страница считается другими документами. Совокупность этих факторов - взвешенная по значению авторитетности страницы релевантность запросу текста самого документа и релевантность запросу текста ссылок на него - и составляет конечную величину соответствия документа тому или иному запросу. Среди рассматриваемых поисковый машин из этой схемы несколько выбивается только Teoma. У нее нет понятия статического ранга документа, потому что ранг документа может меняться в зависимости от запроса. Т.е. ранг документа является наряду с текстом ссылок, одним из внешних динамических факторов.
3. Особенности реализации алгоритмов
3.1 Google
Статическим фактором является значение RageRank документа, представляющий собой взвешенное количество ссылок, - количественный показатель его авторитетности. Алгоритм определения значения PageRank для конкретной страницы описан в статье авторов Google "The PageRank Citation Ranking: Bringing Order to the Web".
С ростом объёма информации в интернете вообще и информации, индексируемой поисковыми системами в частности, перед разработчиками поисковиков встала серьёзная проблема - количество одинаково релевантных запросу документов было велико, и корректно ранжировать их в результатах поиска становилось всё сложнее. К тому же алгоритмы ранжирования, разработанные для контролируемых коллекций документов, оказались беззащитны перед простейшими способами воздействия на них, когда для обеспечения хорошего результата достаточно было просто скопировать структуру расположения ключевых слов из текста хорошо ранжируемого по этому запросу документа. Появилась необходимость разделять информацию на более и менее достоверную, учитывать "важность" или "авторитетность" ресурсов, предоставляющих её. Как это сделать? Лучше всего на основе данных о популярности страницы у пользователей, например посещаемости. Но тогда потребуется устанавливать какой-либо счётчик на каждую страницу. Такой вариант для глобального поиска не подходит. Тогда в качестве критерия была выбрана теоретическая посещаемость страницы.
Была разработана модель, эмулирующая движение пользователя по документам сети путем перехода по ссылкам с документа на документ, подразумевающая, что пользователь с равной долей вероятности перейдет по любой из ссылок, содержащихся в документе, который он в данный момент просматривает. Следовательно, вероятность пользователя попасть на конкретный документ будет зависит от количества ссылок на него с других документов и от того, насколько вероятно нахождение пользователя на одном из ссылающихся документов и сколько исходящих ссылок содержит этот ссылающийся документ. Эта вероятность и была принята за показатель авторитетности или ранг страницы (PageRank):
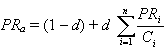
где
PRa - PageRank рассматриваемой страницы,
d - коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не прекратит путешествие по сети, обычно устанавливается равным 0,85),
N - общее количество документов,
PRi - PageRank i-й страницы, ссылающейся на страницу а,
Ci - общее число ссылок на i-й странице.
Одним из распространенных заблуждений является то, что можно вычислить PageRank по этой формуле для отдельно взятого документа, используя известные значения PageRank для ссылающихся на него документов. Так делать нельзя. Чтобы вычислить PageRank какого-либо документа надо составить систему N линейных уравнений данного вида для каждого из документа из поисковой базы, где N - количество документов в поисковой базе. Причем, для выполнения условия, что сумма значений PageRank для всех документов (т.е. вероятность того, что пользователь находится на любой из страниц) равна 1, к свободному члену (1 - d) в каждом уравнении добавляют множитель 1/N. Эта система будет содержать N неизвестных. Решив ее, получим значения PageRank для каждого документа, известного поисковой машине. В поисковой базе крупнейших поисковых машин содержится огромное количество документов. Несмотря на то, что матрица, соответствующая системе уравнений будет сильно разрежена, численное решение этой системы требует огромных вычислительных мощностей. Поэтому поисковая система должна постараться максимально упростить процесс расчета, вводя некоторые допущения. Вот эти конкретные особенности реализации классической формулы PageRank, увы, составляют коммерческую тайну поисковых машин.
Подытоживая, можно сказать, что PageRank страницы A - это взвешенное количество ссылок на страницу A, причем вес каждой ссылки равен значению PageRank ссылающейся страницы, поделенному на количество исходящих с нее ссылок. Можно сказать, что PageRank страницы - это мера еe голоса, и страница может разделить этот голос поровну между одной, двумя или многими ссылками, но общая голосующая сила будет всегда той же самой.
С ноября 2003 года, после революционного апдейта, названного англоязычными вебмастерами "Florida", в среде западных специалистов по поисковой оптимизации (SEO) стали муссироваться слухи, что Google перешел на модификацию алгоритма PageRank, носящую название Hilltop (http://www.cs.toronto.edu/~georgem/hilltop/). Этот алгоритм, патент на который Google получил в 2001 году, подразумевает использование не статического, а динамического (т.е. зависящего от запроса) ранга документа и основан на алгоритме HITS, использующемся в поисковой машине Teoma. Однако, Google не делал никаких официальных заявлений по поводу того, что при ранжировании теперь используется алгоритм Hilltop. Кроме того, в Google постоянно идут параллельные научные изыскания по модификации алгоритма PageRank, как правило, в плане учета тематики документа и запроса. Так, например, есть исследования по использованию в алгоритме не скалярного, а векторного показателя PageRank - Topic-Sensitive PageRank (http://dbpubs.stanford.edu:8090/pub/2002-6). Но, судя по всему, до широкой реалиазации подобных модификаций дело еще не дошло.
К динамическим страничным факторам можно отнести частоту ключевых слов из запроса в тексте документа (рассматриваемые области - тег title, непосредственно текст документа и поле alt тега img у изображений, которые являются ссылками) причем предпочтение отдается точному вхождению поисковой фразы, а также наличие ключевых слов из запроса в адресе документа. Один важный момент - у очень больших документов индексируются только первые 101 килобайт текста. Надо заметить, что влияние динамических страничных факторов весьма невелико по сравнению с остальными.
К динамическим ссылочным факторам относятся текст ссылок на документ с других документов и содержимое поля alt тега img у изображений, которые являются ссылками на документ с других документов. Причем, больший вес имеет текст ссылок со страниц с большим значением PageRank, а у страниц с достаточно небольшим значением PageRank он может вообще не учитываться. Следует заметить и тот факт, что учет ссылки происходит не сразу после переиндексации документа, на котором она находится, а спустя некоторое время.
Google может исключать сайты из своей базы за использование следующих запрещенных приемов:
- клоакинг - выдачу роботам документов, содержимое которых отлично от содержимого документов, выдаваемых обычным посетителям;
- использование текста или ссылок, невидимых пользователем;
- участие в программах обмена ссылками с целью накрутки значения PageRank;
- множественное добавление в поисковую базу страниц-дубликатов;
- использование множественных автоматически сгенерированных входных страниц.
Также в Google практикуется наложение определенных фильтров при учете статических и динамических ссылочных факторов. Например, если в достаточно короткий срок робот проиндексирует подозрительно большое количество внешних ссылок на низкоранговый документ (либо документ находится на новом для Google сайте), то на их учет может быть наложен блокирующий фильтр. Подобный фильтр даже получил в среде англоязычных вебмастеров название "Sandbox" ("песочница"). Считается, что могут быть наложены блокирующие или понижающие фильтры на учет ссылок, если будет обнаружено очень много ссылок с одинаковым текстов; если ссылки идут с сайтов, находящихся в том же блоке IP-адресов, с документов, содержащих контент на другом языке, и т.д.
Теоретические аспекты учета различных дополнительных факторов для коррекции релевантности документа запросу (таких, как частота обновления документа, динамика изменения документа, динамика изменения ссылок на документ, тематичность ссылок на документ, поведение пользователей при просмотре документа и т.д.) отражены в Заявке на Патент США № 20050071741 "Information Retrieval Based on Historical Data" ("Получение информации, основанное на временных данных"), поданной компанией Google 31 марта 2005 года. Однако, точно неизвестно, в какой мере эти теоретические аспекты на данный момент реализованы в алгоритме Google.
Довольно любопытен механизм формирования результатов поиска в зависимости от языка браузера пользователя - документы на языке, совпадающем с языком браузера пользователя получают некоторый дополнительный вес по сравнению с остальными.
3.2 Yahoo! Search
Статическим фактором является значение Yahoo! Web Rank, которое, судя по всему, также представляет собой взвешенное количество ссылок на документ. Официальной информации о том, каким образом вычисляется значение Yahoo! Web Rank нет.
К страничным факторам относятся частота ключевых слов и точность вхождения поисковой фразы в различных частях документа - теге title, мета-тегах keywords и description, тексте документа. Содержимое атрибута alt тега img, по всей видимости, не учитывается. Подобно Google страничные факторы относительно слабы по сравнению с другими.
Ссылочными факторами является наличие ключевых слов в тексте ссылок на данный документ с других документов и содержимое поля alt тега img у изображений, которые являются ссылками на данный документ с других документов. Вполне вероятно, что при этом учитывается значение Yahoo! Web Rank ссылающегося документа и текст ссылок с документов, у которых этот показатель весьма низок, игнорируется. В последнее время учет текста ссылок происходит непосредственно после ее индексации роботом.
За использование поискового спама Yahoo! Search может исключить сайт из индекса с последующим запретом на индексацию. Yahoo! Search считает спамом следующее:
- страницы, перенаправляющие пользователя на другие документы (редирект);
- дубликаты страниц;
- страницы с автоматически сгенерированным бессмысленным содержанием;
- страницы с текстом, скрытым от пользователя;
- клоакинг;
- сообщества страниц, содержащих чрезмерное количество перекрестных ссылок друг на друга;
- неправомерное использование торговых марок конкурентов.
Массового использования каких-либо понижающих фильтров, существенно влияющих на результаты ранжирования, не замечено.
3.3. MSN search
Поисковый механизм MSN Search появился сравнительно недавно и поэтому весьма мало изучен. Но, исходя из анализа поисковой выдачи, можно предположить наличие статического фактора как взвешенного количества ссылок на документ. В разделе помощи на сайте поисковой машины также говорится о том, что одним из факторов, учитываемым при ранжировании является количество и качество входящих ссылок.
Страничные факторы - частота ключевых слов и точность вхождения поисковой фразы в различных частях документа: в теге title, непосредственно в тексте документа. Следует отметить, что страничные факторы весьма сильны.
Ссылочные факторы - наличие ключевых слов в тексте ссылок на документ с других документов. Вполне вероятно, что учитывается также ранг ссылающегося документа. Есть предположение, что вляние этого фактора может зависеть от того, насколько сильны страничные факторы документа, на который ведет ссылка, для данного запроса.
Удалению из поисковой базы могут подвергнуться страницы, которые:
- искусственное завышение концентрации ключевых слов;
- использование скрытого от пользователя текста;
- искусственное повышение ссылок на документ, например, вступление в линк-фармы.
3.4. Teoma
Статических факторов нет. Все факторы, использующиеся при ранжировании, зависят от запроса.
Страничные факторы - частота ключевых слов и точность вхождения поисковой фразы в теге title, непосредственно в тексте документа, мета-тегах keywords и description, содержимом атрибута alt тега img.
Ссылочные факторы - входящие и исходящие ссылки и их текст - используются при определении тематических сообществ документов и авторитетности документа по теме запроса (значений "авторитет"- и "хаб"-весов).
Информация о методах, считающихся поисковым спамом, на сайте Teoma не представлена.
3.5. Сводная таблица учета факторов
Приведенную выше информацию можно систематизировать в виде следующей таблицы:
| Yahoo! Search | MSN Search | Teoma | ||
|---|---|---|---|---|
| Статические факторы | ||||
| Статический ранг | + | + | + | - |
| Динамические страничные факторы, по частям документа: | ||||
| title | + | + | + | + |
| текст документа | + | + | + | + |
| description | - | + | - | + |
| keywords | - | + | - | + |
| alt | + (только у изображений, являющихся ссылками) |
- | - | + |
| Динамические ссылочные факторы | ||||
| Ссылочное ранжирование | + | + | + | + |
| Динамический ранг | - | - | - | + |
Несмотря на то, что содержимое поля alt тега img не используется рассматриваемыми поисковиками (кроме Google) при поиске по документам, оно используется при поиске по изображениям поисковыми машинами, предоставляющими такой сервис - Google, AltaVista, FAST.
4. Практические советы по продвижению сайтов
Основываясь на приведенном выше анализе факторов можно дать следующие общие рекомендации по позиционированию сайтов в рассмотренных поисковых системах:
4.1. Составление семантического ядра
Необходимо выбрать целевые ключевые слова и фразы для позиционирования сайта. Для оценки популярности среди пользователей поисковых машин англоязычных запросов можно воспользоваться сервисом, предоставляемыми сайтом WordTracker (www.wordtracker.com), а также сервисом Search Term Suggestion Tool (https://launchpresso.com/what-happened-to-overture-com/), предоставляемый сервисом контекстной рекламы Overture, являющейся частью сервиса Yahoo! Search Marketing.
Затем необходимо распределить ключевые фразы из семантического ядра по страницам сайта в зависимости от их содержания. Наиболее популярные запросы целесообразно использовать при оптимизации главной страницы сайта.
4.2. Оптимизация структуры сайта
Под организацией оптимальной ссылочной структуры понимается, прежде всего то, как наилучшим образом распределить "авторитетность" между страницами сайта, учитывая количество страниц и конкурентность запросов, составляющих семантическое ядро. В зависимости от этого, перед нами могут стоять различные задачи - равномерно распределить "авторитетность" между всеми страницами или максимально сфокусировать его на некоторых, наиболее важных. На этом этапе остановимся немножно поподробнее.
Существует несколько базовых способов для связывания страниц внутри сайта. На практике, конечно, чаще используются их комбинации, но в ознакомительных целях мы рассмотрим две основные топологии связи страниц - иерархическую и "все на всех".
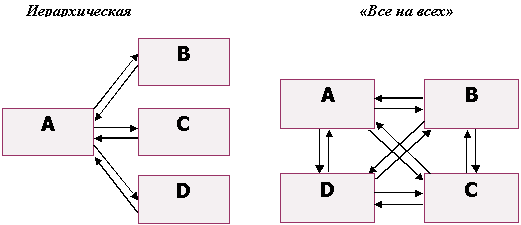
Рассчитаем PageRank по классическому алгоритму для страниц этих сайтов, приняв d=0.85 и решив систему линейных уравнений.
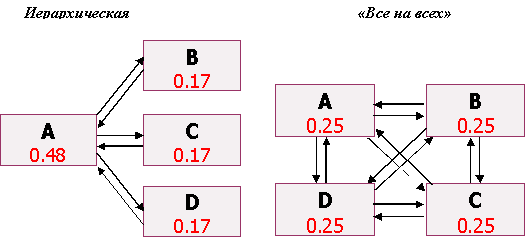
Смотрим на распределение весов. Иерархическая структура обеспечивает наибольший вес главной странице, схема "все на всех" распределяет PageRank равномерно между участвующими в ней страницами.
Рассмотрим более сложную структуру связей между страницами - многоуровневую.
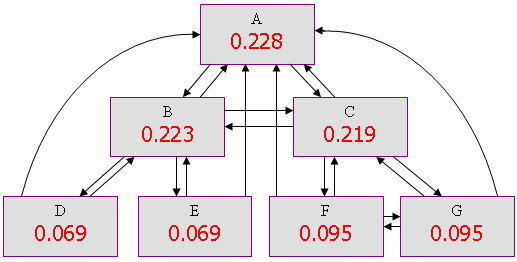
На основе этой схемы можно сделать вывод, что при множестве иерархических связей страницы, стоящие выше в структуре, получают намного больший вес PageRank. Поэтому страницы, оптимизированные под более конкурентные запросы необходимо размещать выше в иерархической структуре. Более плотная связь между группой страниц способствует более равномерному распределению PageRank между ними. Поэтому страницы, содержащие основной контент следует как можно плотнее перелинковать между собой и со страницами, стоящими достаточно высоко в иерархической структуре сайта.
Для более эффективного контроля за распределению весов можно использовать карту сайта. Карта сайта - это страница, на которой отражена структура сайта и находятся ссылки все его страницы. Изначально её стали создавать для удобства использования сайта - до любой страницы с неё всего один переход. Но есть у неё и другие, не менее важные функции. Первое из них - эффективное распределение PageRank внутри сайта.
При использовании многоуровневой структуры ссылок на сайте, особенно это касается иерархической, с каждым последующим уровнем авторитетность страниц становится всё меньшей. И для тех из них, которые находятся на самых нижних уровнях в результате низкого их веса становиться трудно попасть в выдачу поисковиков даже по слабоконкурентным запросам. А ведь на них зачастую располагается очень много информации, потенциально интересной пользователю. В этом случае одним из решений может стать использование карты сайта. В результате размещения на всех страницах ресурса ссылки на карту, на ней накапливается сравнительно большой PageRank. А так как с карты сайта присутствуют ссылки на все страницы, то этот PageRank равномерно перейдёт по ссылкам на все страницы сайта, добавит вес даже наиболее глубоко расположенным страницам. Так, например, добавление карты сайта, на которую ссылается каждая страница сайта, для рассмотренной многоуровневой структуры, приводит к следующему результату:
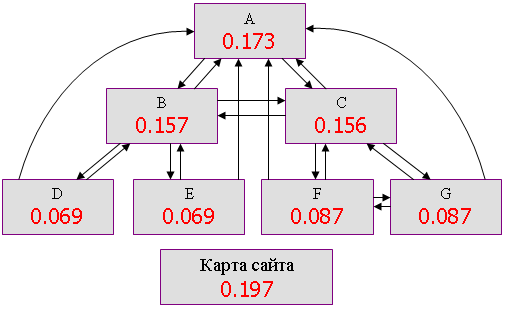
То есть, как мы видим, разница в значениях PageRank между разноуровневыми страницами сайта уменьшилась.
Есть у карты сайта и ещё одно полезное применение. Она позволяет роботам поисковых машин более эффективно обходить страницы. Дело в том, что у многих роботов имеются ограничения на количество уровней вложенности ссылочной структуры, индексируемых за один визит. Приходя же на карту сайта, робот получает сразу весь список существующих страниц, что как минимум увеличивает скорость индексации всего сайта.
В некоторых случаях использование карты сайта становится вообще единственной возможностью для индексации сайта. А случаи эти не так уж и редки и возникают они из-за использования для организации ссылочного меню элементов, не индексируемых поисковыми системами.
4.3. Обеспечение корректной индексации страниц
Для того, чтобы документа сайта были корректно проиндексированы и отранжированы необходимо воздержаться от использование следующих вещей:
- Использование конструкций, затрудняющих индексирование документов (фреймы, динамические адреса страниц, ссылки, реализованные с помошью скриптов, редиректов, технологии Flash и т.п.).
- Засорение индексов поисковых машин дубликатами страниц (идентификаторы сессий, некорректные отклики страниц и т.п.).
- Использование поискового спама (клоакинг, скрытый текст, использование автоматически сгенерированных малоинформативных страниц и т.п.).
4.4. Оптимизация страниц сайта
На этом этапе необходимо распределить выбранные ключевые слова и фразы в индексируемых частях страниц сайта - желательно, чтобы каждое ключевое слово (фраза) встречалось один раз в теге title, мета-тегах keywords и description, атрибутах alt тега img, и (по крайней мере, один раз) непосредственно в тексте документа, желательно в начале. В тексте рекомендуется придерживаться естественной концентрации ключевой фразы в 3-7%.
Следует заметить, что чем больше разнообразного тематического контента находится на сайте, тем больше вероятность хорошего ранжирования его страниц по большому количеству низкочастотных целевых запросов. Поэтому необходимо постоянно заниматься наполнением сайта качественным тематическим контентом.
4.5. Работа с внешними факторами
Необходимо использовать ключевые слова (фразы) в текстовых ссылках (равно как и в атрибуте alt тега img у изображений, являющихся ссылками) между страницами сайта.
Постоянно проводить мероприятия по повышению цитируемости страниц сайта другими сайтами - обмен ссылками, регистрация страниц сайта в каталогах, публикация объявлений, содержащих ссылки на страницы сайта, на тематических досках объявлений, рассылка пресс-релизов, покупка ссылок с других сайтов и т.п. При этом по возможности добиваться употребления в ссылках с других сайтов на страницы своего сайта выбранных ключевых слов и фраз в целях увеличения влияния ссылочных факторов. Необходимо также обращать внимание, чтобы среди ссылающихся сайтов были сайты сходной тематики. Приоритетное значение целесообразно придавать ссылкам с более авторитетных документов, их авторитетность можно приблизительно оценивать по значению индикатора PageRank на панели инструментов Google ToolBar.
Осталось, пожалуй, отметить еще один важный фактор, который косвенным образом может повлиять на показатели авторитетности сайта в терминах алгоритмов поисковых машин. Это уникальность, полезность, актуальность и интересность для целевой аудитории материалов, размещенных на вашем сайте. Вебмастера охотно сами ставят на своих сайтах ссылки на интересный, по их мнению, ресурс. Также повышается вероятность цитирования материалов сайта на других ресурсах с указанием ссылки на первоисточник.